Write a function that, when given a URL as a string, returns only the domain name as a string.
domainName(https://twitter.com/explore) == "twitter" domainName(https://github.com/thepracticaldev/dev.to) == "github" domainName(https://www.youtube.com) == "youtube"
Good luck!
Want to propose a challenge idea for a future post? Email yo+challenge@dev.to with your suggestions!

Top comments (24)
Javascript!
Can you please explain what
const { hostname } = a;does and how?
It has the same effect as:
const hostname = a.hostnameThat's called destructuring assignment. "a" probably is an object which has the hostname property so that assignment extracts hostname.
I'm just writin about this 😅. Hopefully that'll help you.
Actually the domain name is the whole thing - "twitter.com", "github.com", "youtube.com". What do you want to get for something like "a.b.c.ac.il"?
Even "com" or whatever other TLD is a domain name. The most specific domain name in "www dot youtube dot com" is "www".
(edited because def dot to removed the www from my youtube URL.)
JavaScript one-liner
Haskell
Note: Assuming the string will always start with either
http://orhttps://or nothing but not supporting any other protocols (by lazyness).Note2: This won't work for the URIs that have a dot in their name, still working on it.
Note3: Working all good but the end is a mess haha...
Try it online
Hosted on Repl.it.
Have you tried it using a
.co.ukTLD? :DNo I didn't and I assume it will fail for this particular case. Do you have any way on improving this one?
Unfortunately, I think the only way to improve on it is to use the list of all TLDs to find how much of the end of the domain is TLD.
Javascript, using npm package "tldjs"
Try it: codesandbox.io/s/affectionate-dawn...
Jesus, NO! This is what's wrong with development today. This is equivalent to killing a fly with a Sherman tank.
Please, please, for the love of God and companies everywhere that are sick of obfuscated, confusing unmanageable, unmaintainable and insecure code, please look at the one line pure Javascript code above this answer.
There is absolutely no reason on earth to include a library with hundreds of lines of code to perform a simple operation.
Your comment is what's wrong with development today. Taking the shortest solution that seems to somehow solve the vague requirements and declaring it solved and secure.
Each of the JS solutions will fail for one of these test URLs: 'a.b.c.ac.il/', 'news.com.au/', 'youtube.com'.
Except for mine.
My solution in js
One in JS
hostNameis based on a quick reading of the spec and should cope with usernames and ports. Uniform_Resource_Identifier on wikipediasalientSubdomainis the human-readable part of a domain name host as reqd. It just clips off www's and TLD's, with a little complication to handle non-matching strings cleanly.output:
The hostname extractor regex looks fairly funky but isn't too bad if you break it down into parts...
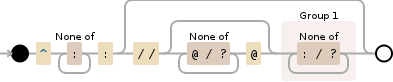
(vis by Debuggex, which rocks)
JavaScript:
considering subdomains & second-level domains (ie. '.bc.ca')
Python one-liner:
O(N) approach:
Naive approach: