We spent a lot of time experimenting with frameworks. Let's pause that for a moment and instead add some functionality to our file manager.
File types
A lot of functionality like viewing or editing or executing files, or even displaying them in a nice way with proper icons, will depend on us knowing "type" of the file.
On the web we don't need to worry about that, as HTTP responses come with Content-Type header, which is hopefully correct. And we rarely do anything dynamic based on response type, just handing all responsibility over to the browser.
For local files, we need to do our work.
File extensions
Traditional way of determining file type is to use file extension. For example, .txt is a text file, .jpg is a picture, .mp3 is a music file, etc.
The best thing about it is that you don't need to inspect the file contents to determine the type. If it's called kitten17.jpg, it's a picture.
This is a good start. Unfortunately that's not a complete solution, and we need to deal with issues like:
- in addition to name, we need to check other file properties, like is it directory, is it symlink etc.
- a lot of files have no extension, like executables on Unix systems
- because there are only so many possible file extensions, it's common for multiple unrelated formats to share them
- some files have double extensions, like
.tar.gz - some files like XML can be crazy many different things - fortunately people mostly use more specific extensions, like SVG XML files will generally be
.svgnot.xml - in certain sense directories can also have "types", like
.git,node_modules,*.app, and might require special handling
Looking inside files
An alternative to file extension is to look inside the file.
Most binary file formats have specific bytes at some specific position - usually at start of file, occasionally at the end. Wikipedia has some examples, but there's a lot more.
The main downside of doing this is that we need to read at least some contents of the file. For most formats reading the first block ("block" being 512 or 1024 or such bytes - files are stored this way on disk so we don't need to worry exactly how many bytes to read - it will generally get a miminum of one block) will do.
It's no big deal if user asked to view one specific file, but if we want to know types of 1000 files in a directory just to put proper icons next to them, reading the first block of each file is going to have significant performance cost.
file command
Unix systems come with file program that does it for us, either in human readable form, or as mime type. Unfortunately it's not very good:
```$ shell
$ file *
index.js: ASCII text
node_modules: directory
package-lock.json: JSON data
package.json: JSON data
preload.js: ASCII text
public: directory
rollup.config.js: Java source, ASCII text
src: directory
$ file --mime-type *
index.js: text/plain
node_modules: inode/directory
package-lock.json: application/json
package.json: application/json
preload.js: text/plain
public: inode/directory
rollup.config.js: text/x-java
src: inode/directory
`file` only looks at file contents not name, and why it got an idea that `rollup.config.js` is Java not JavaScript, while `index.js` is plaintext, is anyone's guess.
And obviously it's not available on Windows.
### `#!` shebang
For text-based executables, there's a special `#!` shebang line at the start of the file. It tells the operating system which language to use to run the file.
It requires some mapping, for example these are just some of the real `#!` lines from my computer, all containing various Python programs:
* `#!/usr/bin/env python`
* `#!/usr/bin/python2`
* `#!/usr/local/Cellar/awscli/2.2.14/libexec/bin/python3.9`
* `#!/usr/local/Cellar/python@3.9/3.9.6/Frameworks/Python.framework/Versions/3.9/bin/python3.9`
* `#!/usr/local/opt/python/bin/python3.7`
* `#!/usr/local/opt/python@3.9/bin/python3`
* `#!/usr/local/opt/python@3.9/bin/python3.9`
`file` does an OK job with that.
### Algorithhm for detecting file type
As none of these methods are sufficient on their own, we need to combine them:
* first we check file stats - is it a directory, is it a symlink, is it a regular file etc.
* then we check file extension
* only then if extension is ambiguous or missing, we check file contents, either by reading the first block of the file, or running `file` command
And then it might be a good idea to cache that information, as it's quite expensive to calculate, and file types don't just change all the time.
However even then, we're not done yet. Once we detect file type, we need some list of what to do with each types, so how to show them, view them, or edit them, or execute them, and so on.
### Code for today
There's plenty of libraries for detecting file type, but let's write one ourselves.
I'll do it in Ruby, as command line Javascript is somewhat tedious.
And I'm not even attempt to be comprehensive here, just do something that establishes pattern we could use to write a proper file type library.
Any real file detector would have a list of at least a few hundred file types.
### Iterate for every argument
We'll get list of paths to check from command line. Let's instantiate our `FileType` class for each of them, then `.call` it.
```ruby
require "pathname"
class FileType
attr_reader :path
def initialize(path)
@path = Pathname(path)
end
...
def call
puts "#{path}: #{type}"
end
end
ARGV.each do |path|
FileType.new(path).call
end
Deal with symlinks
The first thing we need to do is decide what to do with symlinks. I'll just add extra "(symlink)" to end of the type.
def type
if @path.symlink?
"#{base_type} (symlink)"
else
base_type
end
end
Type from file stat
The next step is dealing with directories. We should also support nonexistent files, and various operating system specific special files (like block devices, character devices, sockets, and pipes).
def base_type
return "inode/directory" if @path.directory?
type_from_extension or type_from_contents
end
Type from extension
First, if we can use file extension to figure out the type, without reading what's inside, we should definitely do that.
def type_from_extension
case @path.extname.downcase
when ".png"
"image/png"
when ".jpg", ".jpeg"
"image/jpg"
when ".js", ".jsx"
"text/javascript"
when ".json", ".jsx"
"application/json"
when ".md"
"text/markdown"
when ".txt"
"text/plain"
end
end
Of course this part would need to be a lot longer to come even close to covering enough file types.
Type from interpretter
Extension is not of much help? Time to check the contents.
This step is sort of optional, but file is pretty bad at #! files, and I'm not even sure why, as it's quite easy.
The idea is that these paths are typically #!/some/path/<interpretter><version> <arguments>, and we just want to get the intepretter.
Alternatively they're #!/usr/bin/env <interpretter><version> <arguments>, so if interpretter is env, we just keep going.
def first_line
@first_line ||= @path.open(&:readline)
end
def interpretter
@interpretter ||= begin
parts = first_line[2..-1].split
command = parts[0].split("/").last
command = parts[1].split("/").last if command == "env"
command
end
end
def type_from_shebang
case interpretter
when /\Aruby/
"text/ruby"
when /\Apython/
"text/python"
when /\Anode/
"text/javascript"
when /\A(sh|bash)/
"text/bash"
when /\Aperl/
"text/perl"
else
"text/x-#{interpretter}"
end
end
def type_from_contents
if first_line[0, 2] == "#!"
type_from_shebang
else
`file -b --mime-type #{@path.to_s.shellescape}`.chomp.split.first
end
end
And finally if we can't figure it ourselves we call file command. Unfortunately OSX file often adds some extra crap at the end even if we ask for just mime type (-b --mime-type), so just keep the first word of its output.
Result
Here's the results:
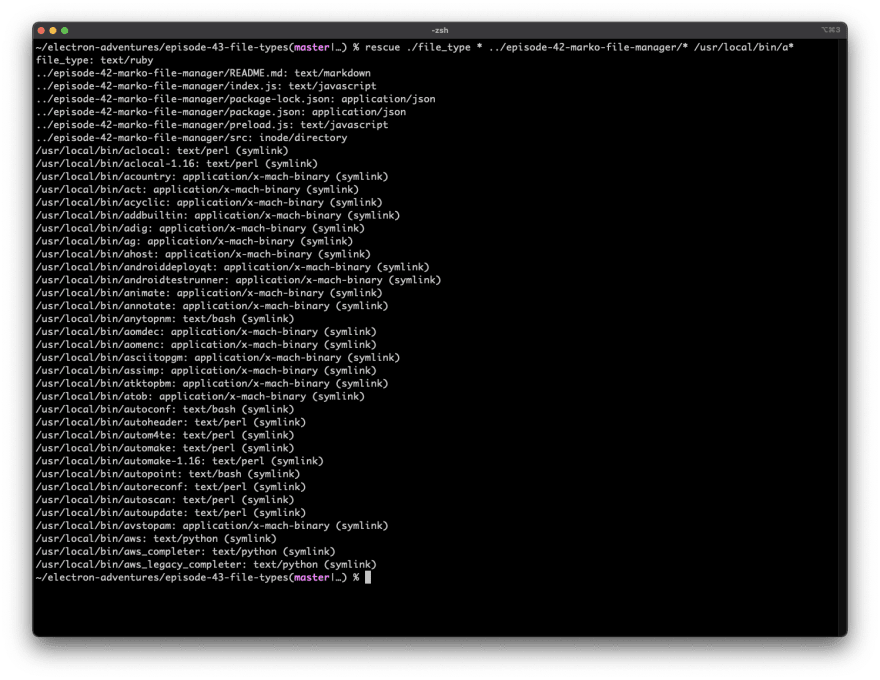
For something so simple, it's working pretty decently. In the next episode, we'll add file type icons to our file manager.
As usual, all the code for the episode is here.

Top comments (0)