
The Problem
The problem at hand involves two tables, Products and Orders.
Table: Products
| Column Name | Type |
|---|---|
| product_id | int |
| product_name | varchar |
| product_category | varchar |
In this table, product_id is the primary key, and it contains data about the company's products.
Table: Orders
| Column Name | Type |
|---|---|
| product_id | int |
| order_date | date |
| unit | int |
The Orders table does not have a primary key, which means it can contain duplicate rows. product_id in this table is a foreign key referencing the Products table. The unit column represents the number of products ordered on order_date.
The task is to write an SQL query to get the names of products that have at least 100 units ordered in February 2020 and their amount. The result can be returned in any order.
Explanation
Let's consider the following input data:
Products table:
| product_id | product_name | product_category |
|---|---|---|
| 1 | Leetcode Solutions | Book |
| 2 | Jewels of Stringology | Book |
| 3 | HP | Laptop |
| 4 | Lenovo | Laptop |
| 5 | Leetcode Kit | T-shirt |
Orders table:
| product_id | order_date | unit |
|---|---|---|
| 1 | 2020-02-05 | 60 |
| 1 | 2020-02-10 | 70 |
| 2 | 2020-01-18 | 30 |
| 2 | 2020-02-11 | 80 |
| 3 | 2020-02-17 | 2 |
| 3 | 2020-02-24 | 3 |
| 4 | 2020-03-01 | 20 |
| 4 | 2020-03-04 | 30 |
| 4 | 2020-03-04 | 60 |
| 5 | 2020-02-25 | 50 |
| 5 | 2020-02-27 | 50 |
| 5 | 2020-03-01 | 50 |
From the above input, we can deduce the following:
- Products with
product_id = 1are ordered in February a total of (60 + 70) = 130. - Products with
product_id = 2are ordered in February a total of 80. - Products with
product_id = 3are ordered in February a total of (2 + 3) = 5. - Products with
product_id = 4were not ordered in February 2020. - Products with
product_id = 5are ordered in February a total of (50 + 50) = 100.
Thus, the expected output is:
| product_name | unit |
|---|---|
| Leetcode Solutions | 130 |
| Leetcode Kit | 100 |
The Solution
There are several ways to solve this problem. We will be discussing three different approaches: basic JOIN and aggregate functions, using the DISTINCT keyword with window function, and using a subquery. Each method has its own advantages and disadvantages in terms of readability, scalability, and execution speed.
Source Code 1
The first method uses a simple JOIN operation between the two tables on product_id, filters the Orders based on the month and year of order_date, groups by product_name, and sums the unit values. Products with a total of 100 units or more are included in the result set.
SELECT
p.product_name,
SUM(o.unit) [unit]
FROM Products p JOIN Orders o ON p.product_id = o.product_id
WHERE MONTH(o.order_date) = 2
AND YEAR(o.order_date) = 2020
GROUP BY
p.product_name
HAVING SUM(o.unit) >= 100
The runtime for this solution is 856ms, beating 19.90% of submissions on LeetCode.

Source Code 2
The second approach uses the DISTINCT keyword along with a window function, providing a more sophisticated solution that can be useful in more complex scenarios.
SELECT
p.product_name,
sum_unit [unit]
FROM Products p JOIN (
SELECT DISTINCT
product_id,
SUM(unit) OVER (PARTITION BY product_id) [sum_unit]
FROM Orders
WHERE MONTH(order_date) = 2
AND YEAR(order_date) = 2020
) o ON p.product_id = o.product_id
WHERE sum_unit >= 100
This solution performs faster than the previous one, with a runtime of 613ms, beating 62.56% of submissions on LeetCode.
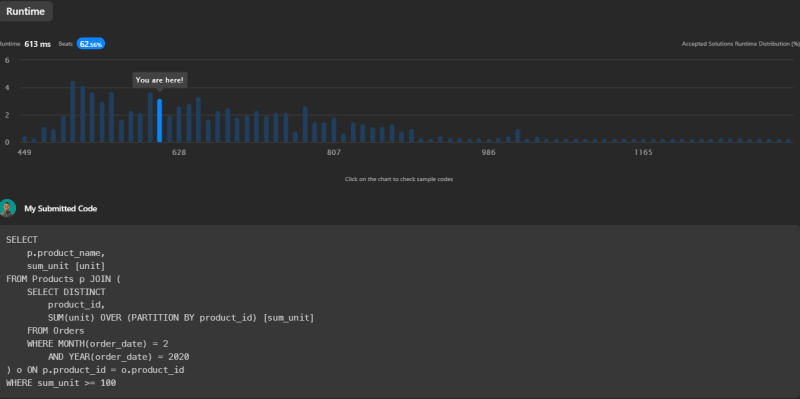
Source Code 3
The third approach uses a subquery in the JOIN operation. This method makes it easier to read and understand the code, but it can lead to slower execution in certain cases.
SELECT
p.product_name,
sum_unit [unit]
FROM Products p JOIN (
SELECT
product_id,
SUM(unit) [sum_unit]
FROM Orders
WHERE MONTH(order_date) = 2
AND YEAR(order_date) = 2020
GROUP BY product_id
) o ON p.product_id = o.product_id
WHERE sum_unit >= 100
This solution has a runtime of 1231ms, beating 7.42% of submissions on LeetCode.
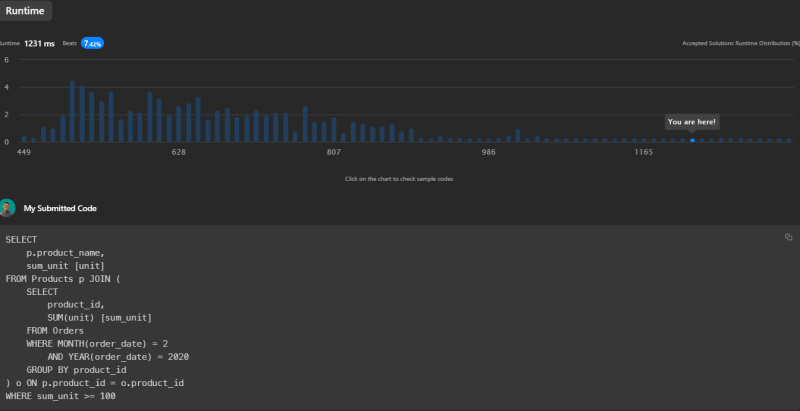
Conclusion
Each of the above solutions provides a valid answer to the problem, albeit with different performance results on LeetCode.
According to the LeetCode metrics, the second solution (Source Code 2) performs the best, followed by the first solution (Source Code 1), and then the third solution (Source Code 3). However, it's important to note that in real-world scenarios, the performance might vary based on the specific RDBMS and the database structure and data volume.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.

Top comments (0)