
The Problem
Consider a table Followers with the following schema:
| Column Name | Type |
|---|---|
| user_id | int |
| follower_id | int |
(user_id, follower_id) is the primary key for this table. This table contains the IDs of a user and a follower in a social media app where the follower follows the user. The task is to write an SQL query that will, for each user, return the number of followers. The result table should be ordered by user_id in ascending order.
Explanation
Consider the following Followers table:
| user_id | follower_id |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 2 | 1 |
For this input, the expected output would be:
| user_id | followers_count |
|---|---|
| 0 | 1 |
| 1 | 1 |
| 2 | 2 |
Here, each row represents a distinct user_id, and the count of followers for each user.
The Solution
We will discuss two different approaches to solve this problem, highlight their strengths and weaknesses, and explain their underlying structures.
Using GROUP BY
This approach directly counts the follower_id for each user_id using GROUP BY clause.
SELECT
user_id,
COUNT(follower_id) [followers_count]
FROM Followers
GROUP BY user_id
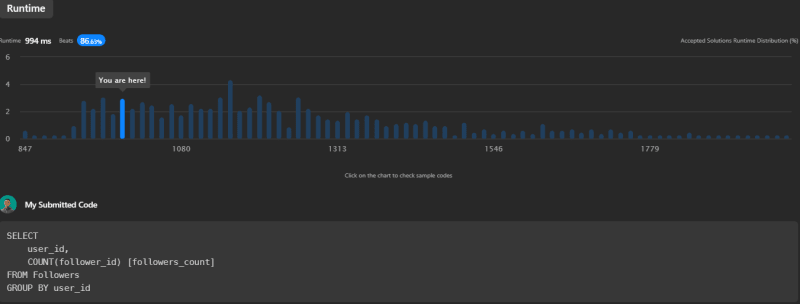
This query is fairly straightforward and easy to understand. It works by grouping the data by user_id, and then it counts the followers within each group. The advantage of this method is its simplicity and directness. However, GROUP BY clause can be slow on large data sets. This query runtime is 994ms, beating 86.63% of other submissions on LeetCode.
Using COUNT() with PARTITION BY
This approach counts follower_id for each user_id using window function.
SELECT DISTINCT
user_id,
COUNT(follower_id) OVER(PARTITION BY user_id) [followers_count]
FROM Followers
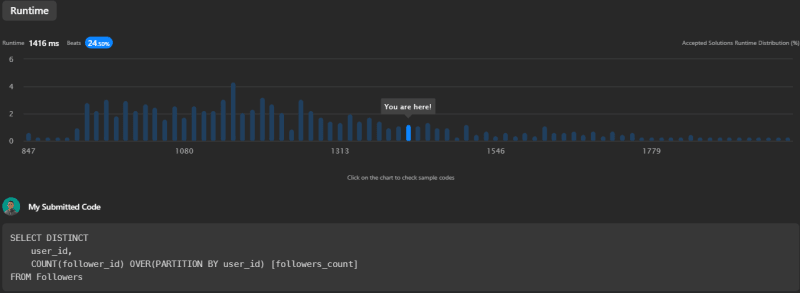
This query, while similar to the first, leverages the power of window functions to achieve the same result. The PARTITION BY clause essentially creates a "window" of rows with the same user_id, and the COUNT function then operates on this window. This approach can sometimes offer performance improvements over the GROUP BY method, especially when dealing with larger data sets. However, in this case, the performance was slightly less, with a runtime of 1416ms, beating 24.50% of other submissions on LeetCode.
Conclusion
Both methods solve the problem, but their performances can vary based on the size and distribution of the data set. While the first solution using GROUP BY clause performed better on LeetCode, in a real-world scenario with a larger data set and a well-tuned database, the second method using window function might perform better. This example serves to illustrate the importance of understanding different methods and when each can be advantageous. Performance in LeetCode and real-world applications may not align perfectly, but practicing with various techniques helps us better prepare for different scenarios.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

Top comments (0)