
The Problem
Given a company's Employee table, we are tasked to write an SQL query to identify the employees who earn a higher salary than their managers. Each row in the Employee table provides the employee's ID, name, salary, and the ID of their manager.
Table: Employee
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| managerId | int |
The Solution
We'll be examining two SQL solutions to this problem. Each takes a slightly different approach to identify employees earning more than their managers.
Source Code 1
The first code snippet uses a nested SELECT statement in the WHERE clause. The subquery finds the salary of each employee's manager, and the main query compares this to the employee's salary:
SELECT e.name AS Employee
FROM Employee e
WHERE e.salary > (
SELECT m.salary
FROM Employee m
WHERE m.id = e.managerId
)
With a runtime of 746ms, this solution beats 76.97% of other solutions. This method can be a bit slower due to the nested subquery which executes for every employee.

Source Code 2
The second solution uses a JOIN clause to combine rows from the Employee table where the employee's managerId matches the manager's id. It then uses a WHERE clause to compare the salaries:
SELECT e1.name AS Employee
FROM Employee e1 JOIN Employee e2 ON e1.managerId = e2.id
WHERE e1.salary > e2.salary
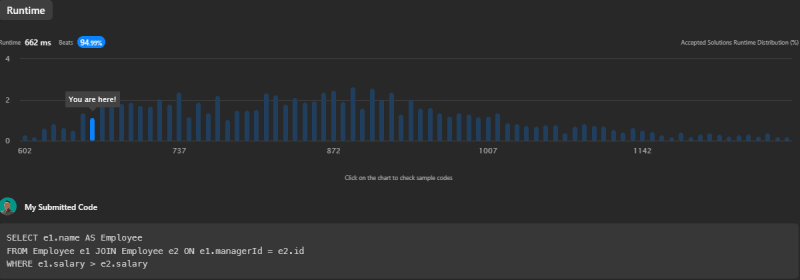
This solution has a faster runtime of 662ms, beating 94.99% of other solutions. By using JOIN, we effectively reduce the number of operations as we avoid executing a subquery for each row.
Conclusion
While both solutions provide the correct answer, the second one performs better due to its use of JOIN to avoid multiple subquery executions. However, it's essential to understand that the choice of method depends on the specific requirements and constraints of your database or problem scenario.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.

Top comments (0)