
Problem Statement
The Scores table structure is:
| Column Name | Type |
|---|---|
| id | int |
| score | decimal |
The id is the primary key for this table. Each row contains the score of a game, represented as a decimal with two places of precision.
The objective is to write an SQL query to rank these scores:
- Scores should be ranked from the highest to the lowest.
- In case of a tie between two scores, both should have the same ranking.
- After a tie, the next ranking number should be the next consecutive integer value - there should be no "holes" between ranks.
The query result should be returned in descending order by score.
Example:
Input:
| id | score |
|---|---|
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
Output:
| score | rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
Solution Approaches
Let's look at two different approaches to solve this problem using MSSQL. Both solutions have their strengths and weaknesses.
Approach 1: Using Window Function DENSE_RANK()
The first approach uses the DENSE_RANK() window function to rank the scores in descending order. The DENSE_RANK() function ensures that in case of ties, both scores receive the same ranking and the next score gets the next consecutive rank.
SELECT
score,
DENSE_RANK() OVER (ORDER BY score DESC) [rank]
FROM Scores
ORDER BY score DESC
This approach is both concise and efficient. The performance is quite good, with a runtime of 624ms, beating 62.23% of LeetCode submissions.

Approach 2: Using Subquery for Counting Distinct Scores
The second approach uses a subquery to count the distinct scores greater than the current score. It then adds 1 to the count to compute the rank.
SELECT
S1.score,
(SELECT COUNT(DISTINCT S2.score)
FROM Scores S2
WHERE S2.score > S1.score
) + 1 [rank]
FROM Scores S1
ORDER BY S1.score DESC
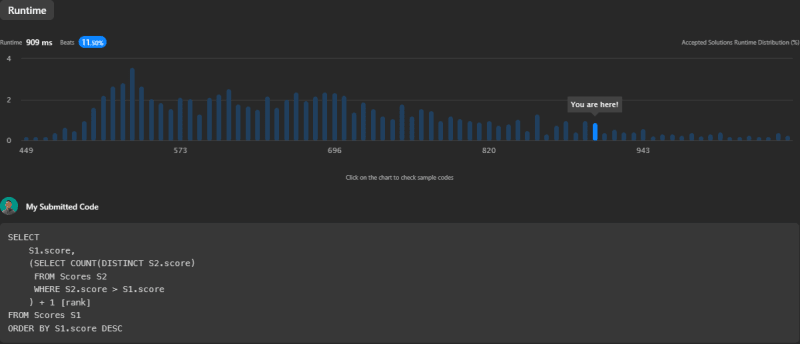
While this method also provides the correct rankings, it is less performant than the first approach due to the subquery. The runtime is 909ms, which only beats 11.50% of LeetCode submissions.
Conclusion
Both of these solutions correctly solve the problem, but they use different techniques and have different performance characteristics. The first approach using DENSE_RANK() is faster and more concise, making it the preferred solution for this problem. However, the second approach, using a subquery for distinct count, offers insight into alternative ways to solve the problem and could be better suited in environments where window functions are not supported or the data distribution is significantly different.
Remember that while these rankings are based on LeetCode's benchmark, performance may vary depending on the specific DBMS, hardware, and data distribution.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.

Top comments (0)