
The Problem
Given the Employee table with the following schema:
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
| department | varchar |
| managerId | int |
where id is the primary key. Each row represents an employee with their name, department, and the id of their manager (managerId). If managerId is NULL, then the employee doesn't have a manager and no employee is the manager of themselves.
Our task is to write an SQL query to report the managers who have at least five direct reports. The query result can be returned in any order.
Here is the given example:
Input:
Employee table:
| id | name | department | managerId |
|---|---|---|---|
| 101 | John | A | NULL |
| 102 | Dan | A | 101 |
| 103 | James | A | 101 |
| 104 | Amy | A | 101 |
| 105 | Anne | A | 101 |
| 106 | Ron | B | 101 |
Output:
| name |
|---|
| John |
The Solution
Let's dive into four different approaches to solving this problem, highlighting their strengths and weaknesses, and their overall performance in a LeetCode benchmark.
Source Code 1: Using subquery in WHERE clause
This approach involves using a subquery to find the managerIds with at least five reports. This subquery is then used in the WHERE clause of the main query to find the names of these managers.
SELECT name
FROM Employee
WHERE id in (
SELECT managerId
FROM Employee
GROUP BY managerId
HAVING COUNT(managerId) >= 5
)
Runtime: 1279ms, beats 28.31% of submissions on LeetCode.

Source Code 2: Using WITH clause
This approach refines the previous one by introducing the WITH clause to create a temporary result set manager that includes managerIds with at least five reports. This is more readable but has a slight performance drop.
WITH manager AS (
SELECT managerId
FROM Employee
GROUP BY managerId
HAVING COUNT(managerId) >= 5
)
SELECT name
FROM Employee
WHERE id in (SELECT managerId FROM manager)
Runtime: 1322ms, beats 23.80% of submissions on LeetCode.

Source Code 3: Using JOIN and Window Function
This method uses a window function COUNT() OVER(PARTITION BY managerId) to count the number of reports for each manager. It then joins this with the original Employee table to output the manager names. This approach provides a clearer expression of the problem, but the performance is in the middle range.
WITH manager AS (
SELECT DISTINCT
managerId,
COUNT(managerId) OVER (PARTITION BY managerId) [manager5]
FROM Employee
)
SELECT e.name
FROM manager m JOIN Employee e ON e.id = m.managerId
WHERE m.manager5 >= 5
Runtime: 1309ms, beats 25.14% of submissions on LeetCode.

Source Code 4: Direct JOIN and GROUP BY
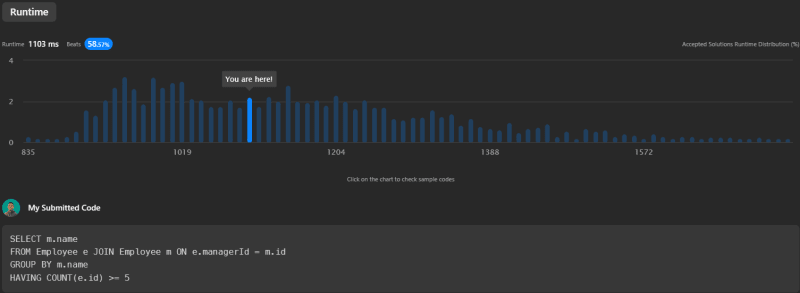
This approach is the simplest and most straightforward. It directly joins the Employee table on itself and groups by the manager's name. It uses the HAVING clause to filter out those with fewer than five reports. This solution shows the highest performance among the four.
SELECT m.name
FROM Employee e JOIN Employee m ON e.managerId = m.id
GROUP BY m.name
HAVING COUNT(e.id) >= 5
Runtime: 1103ms, beats 58.57% of submissions on LeetCode.
Conclusion
All the above solutions provide different ways of solving the problem. However, the fourth solution outperforms the others, indicating that sometimes, straightforward solutions can yield better performance. Still, it's important to understand that these results were obtained in a LeetCode environment. The performances may vary on real-world RDBMS depending on the data distribution, indexes, and other factors.
Ranked from the best to worst based on the LeetCode benchmark:
- Source Code 4
- Source Code 1
- Source Code 3
- Source Code 2
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.

Top comments (1)
I guess in the 4th solution it would be
group by e.managerId