
The Problem
This problem stems from a coding challenge where Julia asked her students to create their own coding challenges. She would like to know who was the most active, and thus, the task is to write a query to print the hacker_id, name, and the total number of challenges created by each student. Results should be sorted by the total number of challenges in descending order. If more than one student created the same number of challenges, sort the result by hacker_id. However, if more than one student created the same number of challenges and the count is less than the maximum number of challenges created, exclude those students from the result.
The Input
The input consists of two tables:
Hackers Table: The hacker_id is the id of the hacker, and name is the name of the hacker.

Challenges Table: The challenge_id is the id of the challenge, and hacker_id is the id of the student who created the challenge.
Sample inputs and corresponding outputs are available for more in-depth understanding of the problem.
Sample Input 0
Hackers Table:
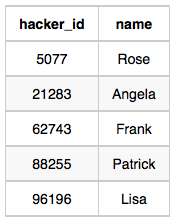
Challenges Table:

Sample Input 1
Hackers Table:
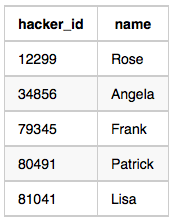
Challenges Table:

The Output
Sample Output 0:
21283 Angela 6
88255 Patrick 5
96196 Lisa 1
Sample Output 1
12299 Rose 6
34856 Angela 6
79345 Frank 4
80491 Patrick 3
81041 Lisa 1
Explanation
For Sample Case 0, we can get the following details:

Students 5077 and 62743 both created 4 challenges, but the maximum number of challenges created is 6 so these students are excluded from the result.
For Sample Case 1, we can get the following details:
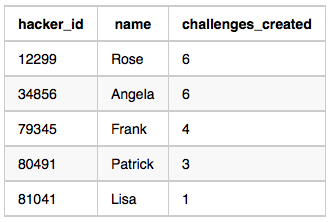
Students 12299 and 34856 both created 6 challenges. Because 6 is the maximum number of challenges created, these students are included in the result.
The Solution
There are multiple ways to tackle this problem. Here, we are going to discuss two solutions.
Source Code 1
This solution first calculates the number of challenges for each hacker using a window function, and then excludes those students who have created challenges count that is less than the maximum but still tied with other students. This solution is relatively straightforward and easy to understand but may not be the most efficient one in case of large datasets.
WITH challenge_counts AS (
SELECT DISTINCT
h.hacker_id,
h.name,
COUNT(c.challenge_id) OVER(PARTITION BY c.hacker_id) AS num_challenges
FROM
Hackers h JOIN Challenges c ON h.hacker_id = c.hacker_id
), max_challenge_count AS (
SELECT MAX(num_challenges) AS maxn
FROM challenge_counts
), duplicate AS (
SELECT num_challenges AS dups_num_chal
FROM challenge_counts
GROUP BY num_challenges
HAVING COUNT(*) > 1
)
SELECT
*
FROM
challenge_counts
WHERE
num_challenges = (SELECT maxn FROM max_challenge_count)
OR
num_challenges NOT IN (SELECT dups_num_chal FROM duplicate)
ORDER BY
num_challenges DESC,
hacker_id
Source Code 2
This solution also calculates the number of challenges for each hacker but it does so while also ranking them based on the number of challenges created. Then, it only includes the hackers with the highest rank or those who have a unique count of challenges. This approach could be more efficient than the first one in terms of execution speed.
WITH ChallengeCounts AS (
SELECT h.hacker_id, h.name, COUNT(*) AS num_challenges,
RANK() OVER (ORDER BY COUNT(*) DESC) AS rank,
COUNT(*) OVER (PARTITION BY COUNT(*)) AS count
FROM Hackers h
JOIN Challenges c ON h.hacker_id = c.hacker_id
GROUP BY h.hacker_id, h.name
)
SELECT hacker_id, name, num_challenges
FROM ChallengeCounts
WHERE rank = 1 OR count = 1
ORDER BY num_challenges DESC, hacker_id
Discussion of Solutions
Source Code 1 uses a combination of window functions, subqueries and conditional WHERE clause to retrieve the result. It first calculates the number of challenges for each hacker by counting over the partition of hacker_id, then determines the maximum number of challenges, and finally filters the hackers who have the maximum number of challenges or a unique number of challenges that is not tied with others. This approach is rather straightforward but could be less efficient when dealing with large datasets due to multiple subqueries and the DISTINCT keyword.
Source Code 2 is more optimized for performance. It uses a similar window function to calculate the number of challenges, but it also ranks the hackers based on their number of challenges in the same query. Then, it simply selects the hackers who have the highest rank (i.e., created the most challenges) or those who have a unique count of challenges. The advantage of this approach lies in its simplicity and efficiency. It reduces the number of subqueries and avoids using the DISTINCT keyword, making it potentially faster than the first solution for large datasets.
Conclusion
When dealing with database queries, particularly those involving ranking and partitioning, it's important to balance simplicity and performance. While the first solution can be easier to understand, the second solution could provide better performance for larger datasets due to fewer subqueries and the absence of the DISTINCT keyword. Understanding the underlying principles of window functions, ranking and partitioning can help you write more efficient and optimized SQL queries.
You can find the original problem at HackerRank.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

ranggakd - Link in Bio & Creator Tools | Beacons
@ranggakd | center details summary summary Oh hello there I m a an Programmer AI Tech Writer Data Practitioner Statistics Math Addict Open Source Contributor Quantum Computing Enthusiast details center.

Top comments (0)