
The Problem
Table: Users
| Column Name | Type |
|---|---|
| account | int |
| name | varchar |
account is the primary key for this table. Each row of this table contains the account number of each user in the bank. There will be no two users having the same name in the table.
Table: Transactions
| Column Name | Type |
|---|---|
| trans_id | int |
| account | int |
| amount | int |
| transacted_on | date |
trans_id is the primary key for this table. Each row of this table contains all changes made to all accounts. amount is positive if the user received money and negative if they transferred money. All accounts start with a balance of 0.
Problem: Write an SQL query to report the name and balance of users with a balance higher than 10000. The balance of an account is equal to the sum of the amounts of all transactions involving that account.
Sample Input and Output
Users table:
| account | name |
|---|---|
| 900001 | Alice |
| 900002 | Bob |
| 900003 | Charlie |
Transactions table:
| trans_id | account | amount | transacted_on |
|---|---|---|---|
| 1 | 900001 | 7000 | 2020-08-01 |
| 2 | 900001 | 7000 | 2020-09-01 |
| 3 | 900001 | -3000 | 2020-09-02 |
| 4 | 900002 | 1000 | 2020-09-12 |
| 5 | 900003 | 6000 | 2020-08-07 |
| 6 | 900003 | 6000 | 2020-09-07 |
| 7 | 900003 | -4000 | 2020-09-11 |
Output:
| name | balance |
|---|---|
| Alice | 11000 |
Explanation: Alice's balance is (7000 + 7000 - 3000) = 11000. Bob's balance is 1000. Charlie's balance is (6000 + 6000 - 4000) = 8000.
The Solution
We present three different SQL queries to solve the problem. Each of them uses different SQL concepts, like aggregate functions, subqueries, and Common Table Expressions (CTE).
Source Code 1
This code is the simplest. It joins Users with Transactions on account, groups by name, and sums the amount for each group. The HAVING clause filters out the groups with a balance not greater than 10000.
SELECT
u.name,
SUM(t.amount) [balance]
FROM Users u JOIN Transactions t ON u.account = t.account
GROUP BY u.name
HAVING SUM(t.amount) > 10000
The runtime of this code is 683ms, beating 51.44% of submissions.

Source Code 2
This code uses window function SUM() OVER(PARTITION BY u.name) to calculate the balance for each user. Then it filters the users with balance greater than 10000.
SELECT
name,
balance
FROM
(
SELECT DISTINCT
u.name,
SUM(t.amount) OVER(PARTITION BY u.name) [balance]
FROM Users u JOIN Transactions t ON u.account = t.account
) a
WHERE balance > 10000
This code runs in 1262ms, beating 5.10% of submissions.

Source Code 3
This code does the same as Source Code 2, but with a CTE to improve readability.
WITH result AS (
SELECT DISTINCT
u.name,
SUM(t.amount) OVER(PARTITION BY u.name) [balance]
FROM Users u JOIN Transactions t ON u.account = t.account
)
SELECT
name,
balance
FROM result
WHERE balance > 10000
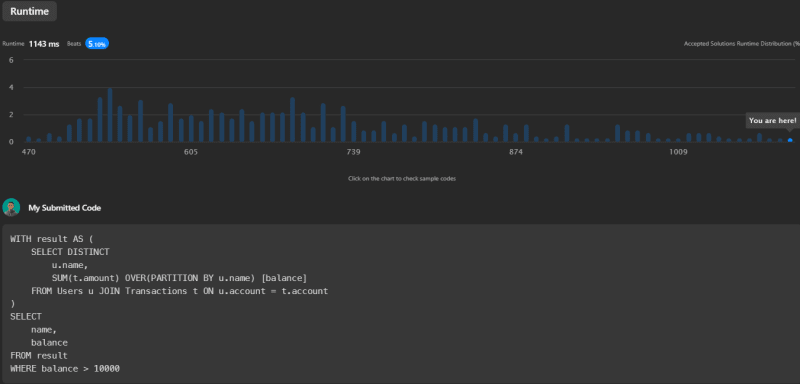
The runtime of this code is 1143ms, beating 5.10% of submissions.
Conclusion
These solutions illustrate different approaches to the problem. However, based on the LeetCode metrics, the first solution seems to be the most efficient, likely because it doesn't rely on window functions which could add overhead in certain SQL engines.
From best to worst in terms of LeetCode performance, we rank the solutions as follows:
- Source Code 1
- Source Code 3
- Source Code 2
Please note, the performance on LeetCode might not always translate directly to performance in a real-world RDBMS. Factors such as database engine optimizations, hardware, and the distribution of data can affect performance in ways that may not be reflected in these rankings.
You can find the original problem at LeetCode.
For more insightful solutions and tech-related content, feel free to connect with me on my Beacons page.

Top comments (0)