
Hey there,
So far this going to be the 15th post in the series.
Have a motivational story to make your mind clear.
One day, an old man was having a stroll in the forest when he suddenly saw a little cat stuck in a hole. The poor animal was struggling to get out. So, he gave him his hand to get him out. But the cat scratched his hand with fear. The man pulled his hand screaming with pain. But he did not stop; he tried to give a hand to the cat again and again.
Another man was watching the scene, screamed with surprise, “For god sakes! Stop helping this cat! He’s going to get himself out of there”.
The other man did not care about him, he just continued saving that animal until he finally succeeded, And then he walked to that man and said, “Son, it is cat’s Instincts that makes him scratch and to hurt, and it is my job to love and care”.
Moral of the Story:
Always treat everyone with respect and kindness but do not expect other people to treat you the way you want to be treated. We cannot control how others react to certain situations but you can certainly control your own.
Main Content from here
In the previous lessons, we checked how well our neural networks were performing by looking at the accuracy on the test sets. When we use a CNN-based model to classify the images from the fashion MNIST dataset, we got 97 % accuracy on the training set, but only 92 % accuracy on the test set.
This was because our CNN was overfitting. In other words, it was memorizing the training set.
But we only became aware of this big difference after we finished training our CNN, because it was only after we finished training our CNN that we were able to compare the accuracy on the test set with the accuracy achieved at the end of training. To avoid this issue, we often introduce a validation set.
Let's see how this works.

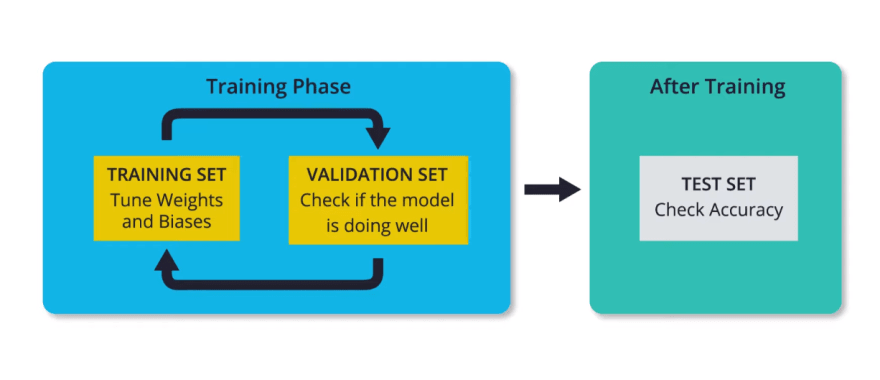
- During training, the neural network will only look at the training set in order to decide how to modify its weights and biases.
- Then after every training epoch, we check how the model is doing by looking at the training loss and the loss in the validation set.
It's important to note that the model does not use any part of the validation set to tune the weights and biases.
- The validation step only tells us if that model is doing well on the validation set.
- In this way, it gives us an idea of how well the model generalizes to a new set of data that is separate from the training set.
- The idea is that since the neural network doesn't use the validation set for deciding its weights and biases, then it can tell us if we're overfitting the training set.
Let's see an example.

If we look at the training and validation accuracies achieved on epochs 15,
- we see that we got a very high accuracy on the training set, and a much lower on the validation set. This is a clear sign of overfitting. The network has memorized the training set, so it performs really well on it. But when tested on the validation dataset which it has not been trained on, it performs poorly.
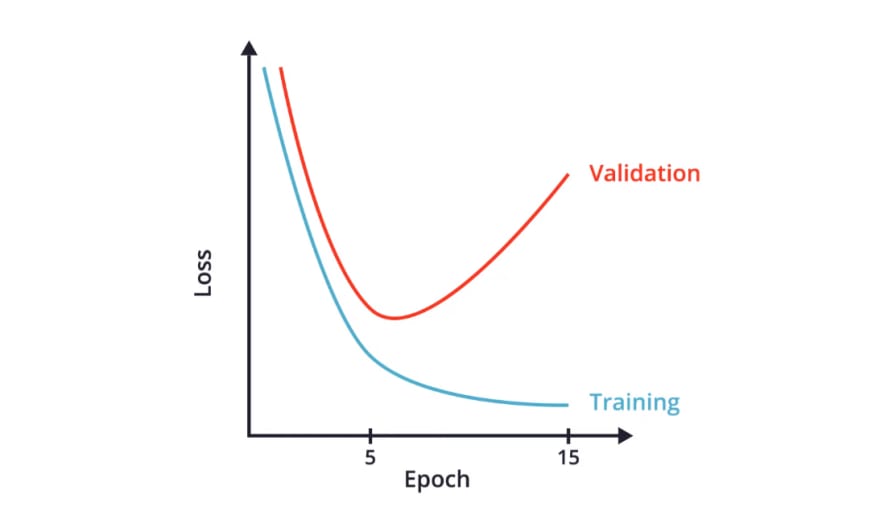
- One way to avoid overfitting is by taking a look at the plot of the training and validation loss as a function of epochs.
- We can see that after some epochs, the validation loss starts to increase, while the training loss keeps decreasing.
- We also see that when we finish training, the validation loss is very high, and the training loss is very small.
- This is actually an indication that the neural network is overfitting the training data, because it's not generalizing well enough to also perform well on the validation set.
- In other words, this plot is telling us that after just a few epochs, our neural network is just memorizing the training data, and it's not generalizing well to the data in the validation set.
- As we can see, the validation set can help us determine the number of epochs we should train our CNN for, such that our network is accurate, but it's not overfitting.

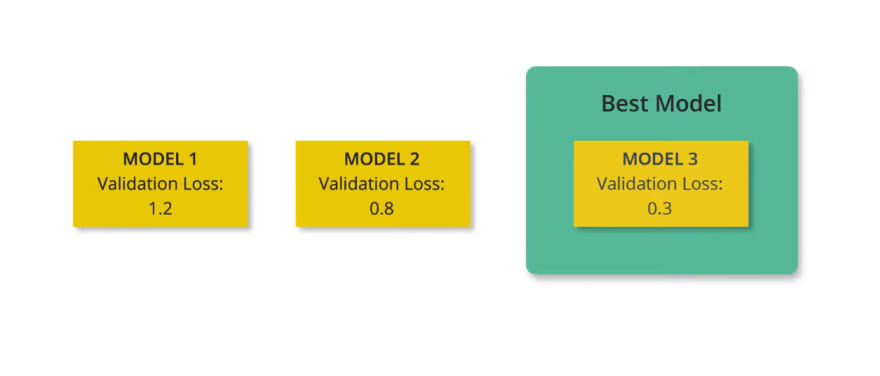
This kind of process can also prove useful if we have multiple potential architectures to choose from.
For example,
- if you're deciding on the number of layers to put in your neural network, you can create various models with different architectures, and then compare them using the validation set.
- The architecture that gives you the lowest validation loss will be the best model.
You might also be wondering why we must create a validation set after all if we have the test set.
Couldn't we just use the test set for validation?
The problem is that even though we don't use the validation set to tune the weights and biases during training, we ultimately end up tuning our models such that it performs well on both the validation set and the training set.
Therefore, our neural network will end up being biased in favor of the validation set. We need a separate test set to really see how our model generalizes and performs when given new data it has never seen before. We just saw how we can use a validation to prevent overfitting.
In the following lessons, we'll talk about data augmentation and dropout two very popular techniques that can also help us mitigate overfitting.

Top comments (0)