
Hey there,
In this lesson, we'll use a deep neural network that learns how to classify images from the fashion MNIST dataset. This is what our network will look like.
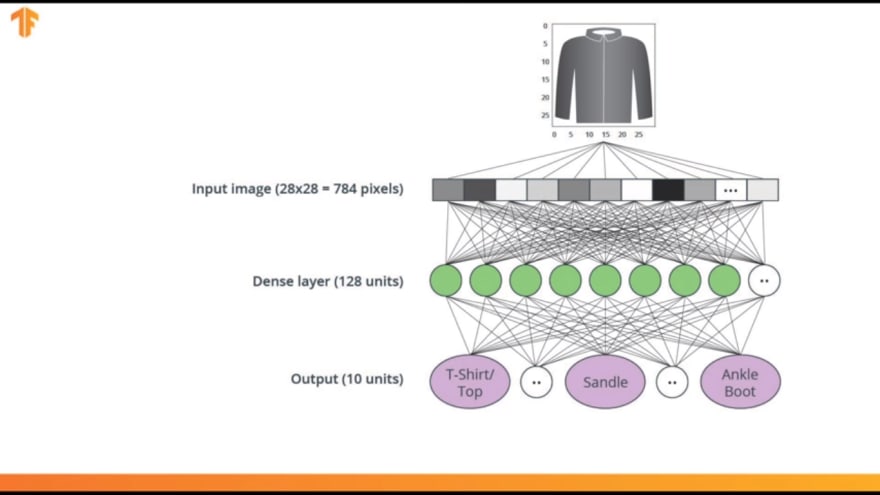
Let's go through this in detail. We can see that the input to our models, is an array of length 784. This is because, each image in our dataset is
- 28 pixels in height
- 28 pixels in width
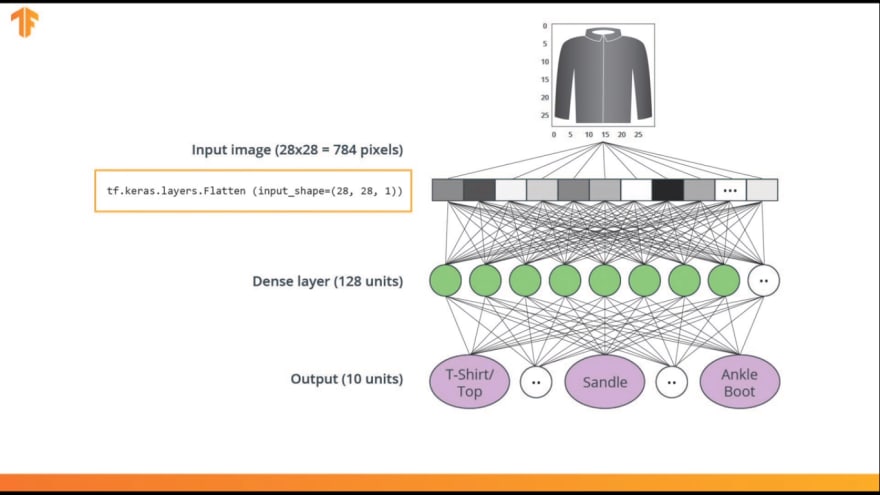
Since our neural network takes in a vector as input, these 28 by 28 images, are converted into a one dimensional array of 28 by 28, so 784 units. This process of converting a 2D image into a vector is called flattening and code, this is performed through a flattened layer
This layer transforms each image from a 2D array of 28 by 28 pixels, each having a single byte for the gray-scale, to a 1D array of 784 pixels.
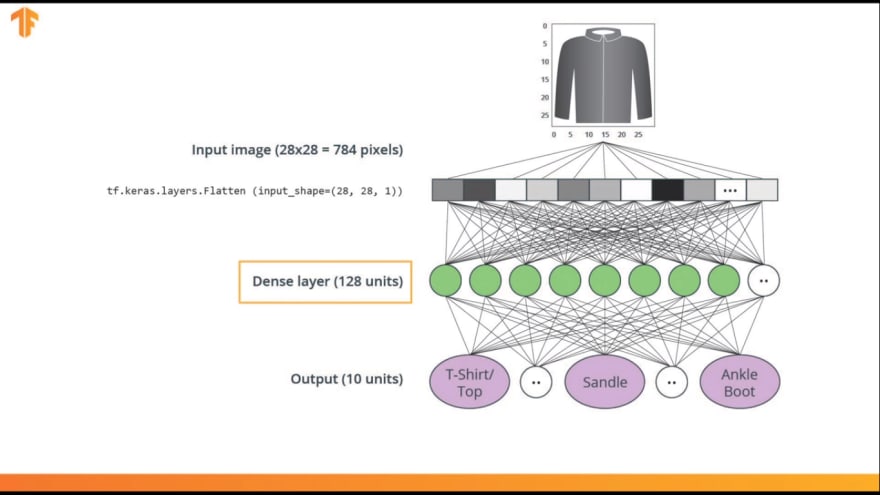
The input will be fully connected to the first dense layer of our network, where we've chosen to use 128 units.
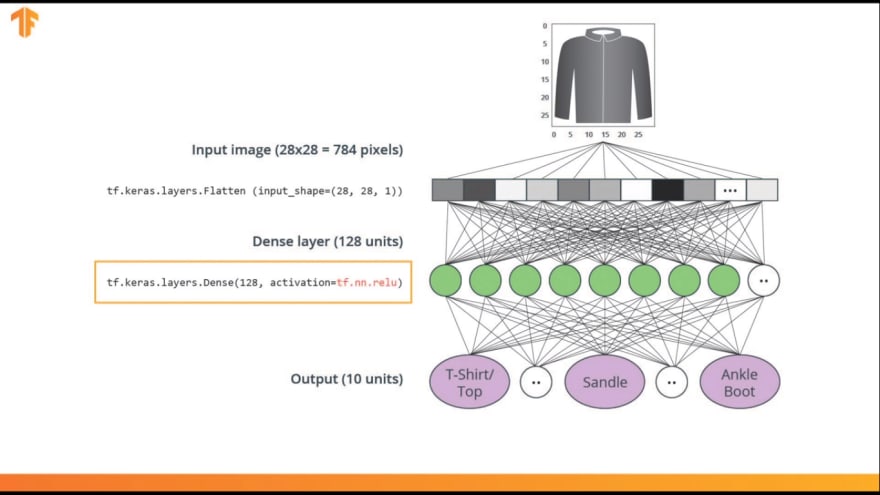
So this is what it looks like in the code.
But wait a minute, what is this relu thing here? We didn't have to do that in our Celsius Fahrenheit network. The thing is, this problem is more difficult to solve than the previous problem of converting Celsius to Fahrenheit. Relu is a mathematical function. We add to our dense layer, which gives it more power. In essence, it's a small mathematical extension to our dense layer that allows our network to solve more complex problems.
Finally, the last layer also known as the output layer, contains 10 units. This is because, our fashion MNIST dataset contains 10 types of articles of clothing. So just t-shirts or tops, sandals, ankle boots etc.
Each of these 10 output values will specify the probability that the images of that specific type of clothing.
So in other words, these numbers describe the confidence the model has, that an input image is one of the 10 different articles of clothing.
For example, the probability that the image is a t-shirt or a top, a sandal or an ankle boot. So given this image for example, the model could give us the following probabilities.

As you can see, the highest score 0.85, is given to the shirt label indicating that the model is 85% certain that this is a shirt. Anything that looks similar to a shirt, would also normally have high scores and things that look very different would get a low score. Since these 10 output values refer to probabilities, if you sum them up, the result will be one. Because, given an input image, our neural network must tell us which out of these 10 it predicts to this. These 10 numbers are also called the probability distribution or in other words, a distribution of probabilities for each of the output classes of clothing, all summing up to one.
So that's our network. Now we need the output layer to create these probability values for each of our classes. We'll tell our output dense layer to create these probabilities using the softmax statement. In fact, whenever we create a neural network that does classification, we always end the neural network with a dense layer that contains the same number of units as we always have classes and always has the softmax statement.
The Rectified Linear Unit (ReLU)
In this lesson we talked about ReLU and how it gives our Dense layer more power. ReLU stands for Rectified Linear Unit and it is a mathematical function that looks like this:
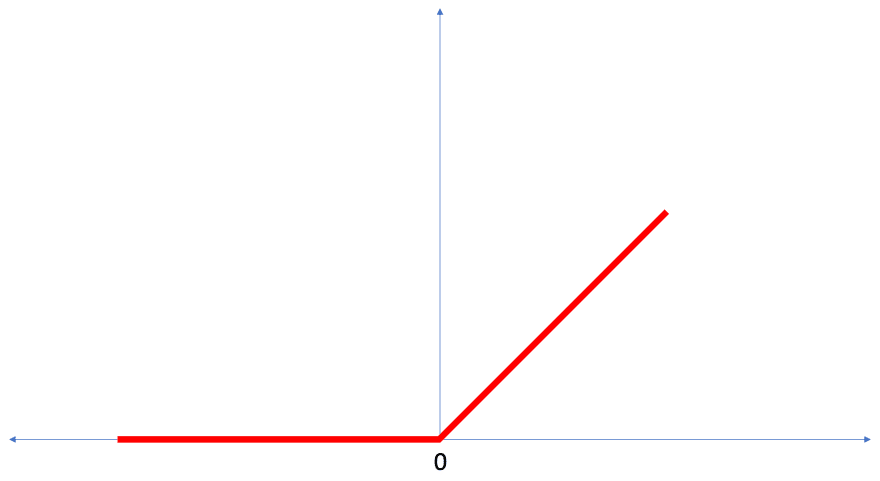
As we can see, the ReLU function gives an output of 0 if the input is negative or zero, and if input is positive, then the output will be equal to the input.
ReLU gives the network the ability to solve nonlinear problems.
Converting Celsius to Fahrenheit is a linear problem because f = 1.8*c + 32 is the same form as the equation for a line, y = m*x + b. But most problems we want to solve are nonlinear. In these cases, adding ReLU to our Dense layers can help solve the problem.
ReLU is a type of activation function. There several of these functions (ReLU, Sigmoid, tanh, ELU), but ReLU is used most commonly and serves as a good default. To build and use models that include ReLU, you don’t have to understand its internals. But, if you want to know more, see this article on ReLU in Deep Learning.
Let’s review some of the new terms that were introduced in this lesson:
-
Flattening: The process of converting a 2d image into 1d vector -
ReLU: An activation function that allows a model to solve nonlinear problems -
Softmax: A function that provides probabilities for each possible output class -
Classification: A machine learning model used for distinguishing among two or more output categories
Lets see the training and testing in the next part.

Top comments (0)