The issue with the last devlog
While reviewing the previous devlog I had one of those "Oh c**p" moments... my direction changes did not account for the way the player was currently facing, if the player turned around 180° then the left and right would be reversed to what you'd expect, as would the forward and backwards controls.
Fixing this and refactoring the code
While fixing this I decided to perform the following code changes at the same time.
- Create a game loop thread which will process the controller inputs and render the scene at 40 frames per second.
- Create a player vision class which will process the look rotation and adjust the two
GameCamera's accordingly - Create a player class which will hold the players position and an instance of the new vision class.
Accounting for the rotation when moving
when moving in any direction (forward, backwards, left, right) we need to know what way the player is looking to know what direction forward etc is.
To do this we create a translation matrix for the player movement, then create a rotation matrix from the Yaw component of the look rotation and multiply the two.
This will rotate the direction the player wants to move to the direction the player is looking.
A bit more Kotlin
As part of these changes I made significant use of Kotlin's also scoped function.
This allowed me to declare a FloatArray for a matrix and perform actions on the Matrix, all within the scope of the declaration, this is probably not the intended use of this function but I found it much cleaner when there are multiple steps to set a variables value e.g.

Reformatting the code
During the previous developments I always thought it was a bit odd, passing the GameControlHub to the VrRenderer.
Therefore, as part of this stage, I decided to create a GameLoop class which implements the Runnable interface and processes any game controller input, adjusts the Player and then requests the scene is rendered.
Initially I have added a 25mS delay after the scene is rendered to limit the frame rate to < 40fps, going forward I shall make this a more accurate refresh rate.
The PlayerVision
This new class holds the two GameCamera instances that were previously in the VrRenderer class.
An instance of the the class is created in the MainActivity's onCreate method. this instance is then passed to the an instance of the Player class which updates the camera location and look/up directions, and it is also passed to the VrRenderer via the VrGlSurfaceView which uses the each of the GameCamera's to render the scene as before.
Each loop of the GameLoop updates the Player which in turn updates the PlayerVision.
First a rotation matrix is generated using the pitch and yaw rotations

Then this rotation is then applied to the look direction, up direction, left camera position and right camera position e.g.
Finally we update the two GameCamera's position, look direction and up directions which the resulting matrices.
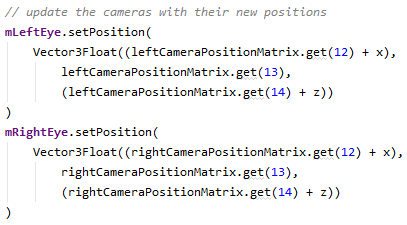
One thing to note is that the up and look direction components are direction vectors but the GameCamera's position is a position vector, therefore the players position (x and z) is applied to the calculated camera positions.
Until next time, the source code at this point in the process can be found in pre-release B1.4 on my github.

Top comments (0)