Resources:
- MIT video explaining topological sort
- Video explanation and walkthrough
- Video explanation and implementation
Takeaways:
- Topological sort is an algorithm that produces a linear ordering of a graph's vertices such that for every directed edge
v -> u, vertexvcomes before vertexuin the ordering. - There can be more than one valid topological ordering of a graph's vertices.
- Topological sort only works for Directed Acyclic Graphs (DAGs)
- Undirected graphs, or graphs with cycles (cyclic graphs), have edges where there is no clear start and end. Think of
v -> u, in an undirected graph this edge would bev <--> u. The same is true for a graph with a back edge (cycle) - we do not know what the order should be as it is ambiguous as to which vertex comes before the other. - Here is a visualization of what a topological sort might produce:
DAG before topological sort

Three valid topological orderings of the DAG's vertices
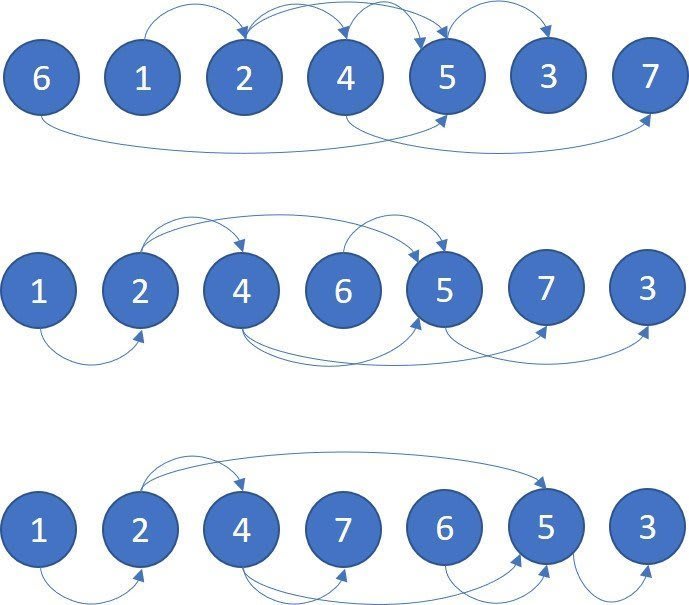
- One important thing to consider when thinking about topological ordering is the in-degree and out-degree of each vertex.
- In-degree is how many edges point to a vertex (incoming edges).
- Out-degree is how many edges point from a vertex (outgoing edges).
- Vertices with an in-degree of 0 will tend to be towards the beginning of a topological ordering, because no other vertex points to them.
- Vertices with an out-degree of 0 will be towards the end of a topological ordering, because they don't point to any vertices - they are solely destination vertices in directed edges.
- There are two main ways to perform topological sort: Kahn's Algorithm & Depth-First Search (DFS).
- Roberet Tarjan is credited with being the first to write about using DFS for topological sorting.
- Kahn's algorithm relies on pre-calculating the in-degree of each vertex.
- Tarjan's approach uses DFS to a achieve a topological ordering of a graph's vertices.
- In this post I will be covering DFS and not Kahn's algorithm.
- If you wish to learn more about Kahn's algorithm see this explanation.
- Using DFS for topological sorting is actually almost identical to vanilla DFS, the main difference is that we keep track of a collection of vertices to return (which will be the topological ordering of vertices).
- In Tarjan's approach we loop through each vertex of the graph
- If we haven't visited the vertex before we run DFS on that vertex.
- We mark each vertex in the DFS routine as visited before exploring each of the vertex's neighbours.
- If a neighbour has already been visited, it is skipped.
- Before each DFS execution completes, it will add the current vertex to a
Stackor prepend it to aList. - The
ListorStackrepresents the topological ordering of vertices. - If we use a
Stackwe can pop each vertex from the stack, and the order in which they are popped will be the topological order. - For
List, if we always prepend (add new vertices at the start), then the list will represent our topological ordering at completion of the algorithm. -
Stackhas cost after adding all vertices to it.Listhas a cost each time we add to it (can't append, have to prepend). - We could also append to a collection (like
List) and then reverse it after adding all vertices. - Either way we choose will incur an
O(v)cost - so it is a matter of preference.
- Run time of DFS for topological sort of an adjacency list is linear
O(v + e)- wherevis number of vertices andeis number of edges. Space complexity isO(v). For an adjacency matrix, both areO(v^2). - Some applications of topological sort:
- Can be used to detect cycles and find strongly connected components in graphs.
- School: class prerequisites & what order you have to take the classes in.
- Build systems: What order should the dependencies get built in? Also helps to enforce that there are no circular dependencies (as topological sort detects cycles).
Below are implementations of DFS for topological sorting of adjacency list & adjacency matrix representations of graphs:
As always, if you found any errors in this post please let me know!

Top comments (0)