
🔰 Beginners new to AWS CDK, please do look at my previous articles one by one in this series.
If in case missed my previous article, do find it with the below links.
🔁 Original previous post at 🔗 Dev Post
🔁 Reposted previous post at 🔗 dev to @aravindvcyber
In this article, let us add a new async batch integration to our message dynamodb table which will help us to delete the processed records from the staging dynamodb table.
Benefits in this approach 💦
- In this approach we tried to clear the staging table data, asynchronously using the dynamodb stream directly invoking a lambda.
- So we can use this in systems where we may not directly do the scavenging synchronous in a compute-intensive workload. Saving compute by avoiding wait time for these I/O.
- Again, some may argue that anyway I am making a lambda call elsewhere separately, which could be thought of as a good decoupling strategy as well.
- But invocation charges and compute still apply there. Yet, we need no one more thing that the streams can be ready in batches by our lambda and the default is 100, so one invocation.
- At the same time, the handler can do a batch request to delete the data from the dynamodb in a single request.
- So not only you can read a batch of streams, but you can also perform batch delete which, is fast as well as we get this delete operation into chunks of 25 max limit which gives a great reduction in the number of I/O operations from lambda.
- Maybe I will write a separate article later about it, for now, it is not limited to the 1:1 delete operation here.


Planning 🐞
Here we will be making use of the dynamodb streams to trigger the deleteItem action by invoking a new lambda handler function which achieves our objective.
Construction 💮
We need a new lambda function code that has a fresh handler to receive the dynamodb stream event object and process it as shown below.
Create a new lambda function in the file lambda/message-stream.ts.
Here you may find that we are targeting an event name to be INSERT, likewise we can have finer control over our desired outcome during these stream invocations as shown below.
New handler function logic 🥙
exports.created = async function (event: any) {
console.log("Received stream:", JSON.stringify(event, undefined, 2));
const results: any[] = [];
await Promise.all(
event.Records.map(async (Record: any) => {
console.log(JSON.stringify(Record, undefined, 2));
if (Record.eventName === "INSERT") {
results.push(await deleteDbItem(Record.dynamodb.Keys));
}
})
);
results.map((res) => console.log(res));
};
Helper function dynamodb deleteItem 💐
Simple helper function to perform deleteItem from a dynamodb table.
const deleteDbItem: any = async (keys: any) => {
console.log("Deleting: ", { keys });
const deleteData: DeleteItemInput = {
TableName: process.env.STAGING_MESSAGES_TABLE_NAME || "",
Key: keys,
ReturnConsumedCapacity: "TOTAL",
};
console.log("deleteItem: ", JSON.stringify(deleteData, undefined, 2));
return await dynamo.deleteItem(deleteData).promise();
};
Minor changes to the dynamodb table definition 🍊
I have highlighted the necessary changes, we need to perform dynamodb stream generation for our table.
Most importantly, I have requested both the new and old images, which will have all the necessary data, however, we are not going to use all of the data. This is only for demonstration purposes.
const messages = new dynamodb.Table(this, "MessagesTable", {
tableName: process.env.messagesTable,
sortKey: { name: "createdAt", type: dynamodb.AttributeType.NUMBER },
partitionKey: { name: "messageId", type: dynamodb.AttributeType.STRING },
encryption: dynamodb.TableEncryption.AWS_MANAGED,
readCapacity: 5,
writeCapacity: 5,
//New item added below
stream: dynamodb.StreamViewType.NEW_AND_OLD_IMAGES
});

Defining the new lambda 🍇
Here we will use the code bloc used above to provision our lambda as shown below inside our master stack.
const messageStreamFunc = new lambda.Function(this, "messageStreamFunc", {
runtime: lambda.Runtime.NODEJS_14_X,
code: lambda.Code.fromAsset("lambda"),
handler: "message-stream.created",
logRetention: logs.RetentionDays.ONE_MONTH,
tracing: Tracing.ACTIVE,
layers: [nodejsUtils,nodejsXray],
environment: {
STAGING_MESSAGES_TABLE_NAME: envParams.messages.stgTableName || "",
},
});
messageStreamFunc.applyRemovalPolicy(RemovalPolicy.DESTROY);

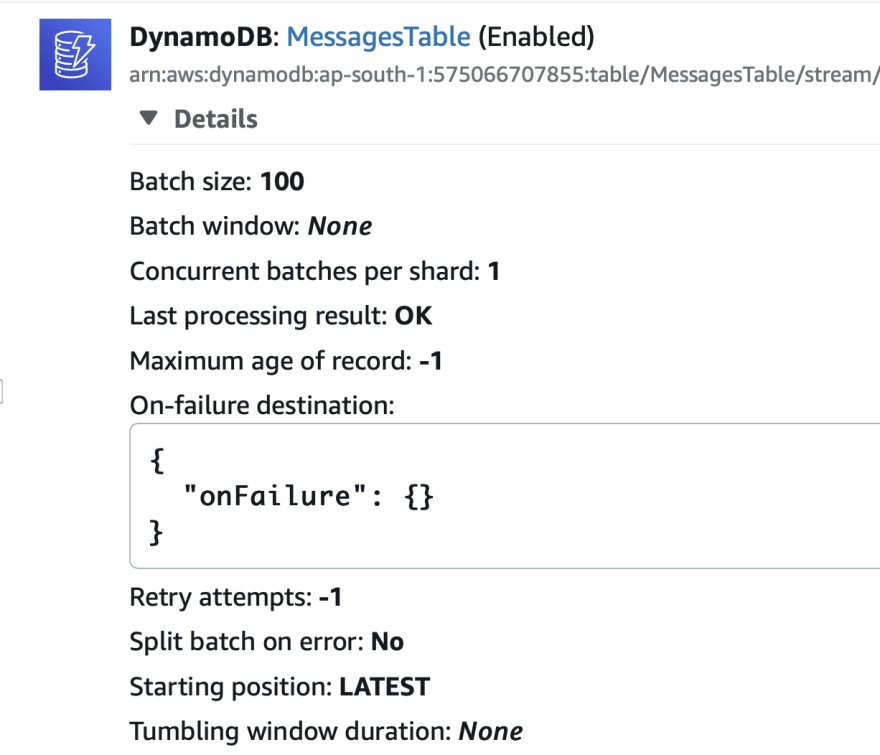
Grant permission for the handler to write to the table 💨
Also, our handler must have sufficient access to delete from the other dynamodb table stgMessages.
stgMessages.grantWriteData(messageStreamFunc);

Adding Event source to the lambda function 🌽
It is time not to connect the handler function to the dynamodb event source as follows.
messageStreamFunc.addEventSource(
new DynamoEventSource(messages, {
startingPosition: lambda.StartingPosition.LATEST,
})
)
or you can improve the batch-size and window in seconds for long polling as follows.
messageStreamFunc.addEventSource(new DynamoEventSource(messages, {
startingPosition: lambda.StartingPosition.LATEST,
batchSize:100,
maxBatchingWindow: Duration.seconds(60)
}))
Sample dynamodb stream object 🥣
I have shared the dynamodb stream object used as payload to invoke our handler lambda below.
{
"Records": [
{
"eventID": "5c9aa5395f970324e088a32578ee0a66",
"eventName": "INSERT",
"eventVersion": "1.1",
"eventSource": "aws:dynamodb",
"awsRegion": "ap-south-1",
"dynamodb": {
"ApproximateCreationDateTime": 1652355068,
"Keys": {
"createdAt": {
"N": "1652355039000"
},
"messageId": {
"S": "47d97141-01e7-42a1-b6b3-0c59a6a3827e"
}
},
"NewImage": {
"createdAt": {
"N": "1652355039000"
},
"messageId": {
"S": "47d97141-01e7-42a1-b6b3-0c59a6a3827e"
},
"event": {
"S": "{\n \"message\": {\"new\": \"A secret message\"}\n}"
}
},
"SequenceNumber": "20927100000000035334874026",
"SizeBytes": 173,
"StreamViewType": "NEW_AND_OLD_IMAGES"
},
"eventSourceARN": "arn:aws:dynamodb:ap-south-1:8888888:table/MessagesTable/stream/2022-05-*****"
}
]
}
Console log during execution 🍿
Finally post-execution, we could find the above JSON payload we have received in the event object and which is then used to delete from our staging table you may find the results below in cloud watch logs.

In the next article, we will demonstrate how we will use a similar approach to delete Object from S3, which we have previously created.
We will be adding more connections to our stack and making it more usable in the upcoming articles by creating new constructs, so do consider following and subscribing to my newsletter.
⏭ We have our next article in serverless, do check out
🎉 Thanks for supporting! 🙏
Would be great if you like to ☕ Buy Me a Coffee, to help boost my efforts.


🔁 Original post at 🔗 Dev Post
🔁 Reposted at 🔗 dev to @aravindvcyber
🐉 AWS CDK 101 - 🏇 Using batched dynamodb stream to delete item on another dynamodb table
— Aravind V (@Aravind_V7) May 14, 2022
@hashnode
Checkout more like this in my pagehttps://t.co/CuYxnKr0Ig#TheHashnodeWriteathon#awscdk #aws #awslambda #thwcloud-computing https://t.co/RlrahA0wrI

Top comments (3)
Cool article but what I am missing what business case / use case are you trying to solve? Why do you need to chunk together stream and to delete items from another table.
@mmuller88 Thanks for your question. Please find my thoughts.
Frankly there is no business case. But functionally we have two tables one raw staging table which is supposed to have some raw content ingested from the api gateway and we contain them inside staging table.
Second we do some processing, let us image some validation or pre-processing or transformation. By then we made use of the data in staging table and we have created our record in main table. Now we need to scavenge the data in the staging table, usual way is simply setting TTL in staging table, since it is dynamo. So went it comes to scavenging 60 seconds or aggregation and delete is not a matter.
But when you need to scavenge the raw data with some post processing stuff say for some business logic we will end up in making use of dynamodb stream with lambda. Rather than doing 1-1 deleteItem, you can do a long polling by aggregating stream items and trigger delete for a single time.
(Batch delete is in my next article to achieve the second half optimisation of this and then you will have much clarity what difference it makes 100K dynamodb api invocations again ).
When you have a 100K records in dynamodb under 60 seconds you will theoretically have 1K lambda invocations for scavenging in 60s. This could be further throttled not to raise any concurrency run off in production.
Here we did some sort of long polling with window size 60s and batch size 100, so less overhead when we achieve reduction in lambda invocations, and compute hours eventually and also we can avoid unnecessary usage lambda concurrency by repeated invocations. Also the lambda executes consistently in repeated intervals.
Tracking and tracing less events is much more clear and can avoid some cost when you have deep monitoring pushing metrics for such simple workloads without sampling like in my sandbox
@mmuller88
Second part of this article which demonstrates how I make use of batch deleteItem on dynamodb table to
This will help convert my example which is expected to generate 100K deleteItem api requests downstream to only 4K batchWrite dynamodb api requests.
dev.to/aravindvcyber/aws-cdk-101-d...