
🔰 Beginners new to AWS CDK, please do look at my previous articles one by one in this series.
If in case missed my previous article, do find it with the below links.
🔁 Original previous post at 🔗 Dev Post
🔁 Reposted previous post at 🔗 dev to @aravindvcyber
In this article, let us add a simple integration making use of dynamodb streams to perform batch delete objects in S3 which we have created in our earlier articles, and understand how it is more performant than a single S3 delete object call.
Benefits in this approach 💦
- Like TTL in dynamodb, we do have Lifecycle rules which can you to delete the Objects but this approach demonstrated below is for more deterministic and event-driven architecture where you need some post-processing while scavenging these records.
- While a single delete Object is also good, when we have a large number of records one after another, it will create too many API invocations and overhead in latency.
- Batch delete Objects help us hereby reduce the number of external API requests.
- Reducing losing the compute hours due to external I/O in a heavy memory instance for idle time.
- Avoid being throttled if we have reached the throughput set for the s3 prefix on very rare occasions
- And it is also possible that lambda may timeout if we are not ready to increase it
-
deleteObjectdoes not provide a full response for non-versioned buckets, whereasdeleteObjectsprovides a neat response with the errors as well.
Spoiler lifecycle methods to expire items automatically 🍁
Yes just like TTL in dynamodb, we could make use of the lifecycle methods to automatically expire or transition objects to other storage classes in s3. But well, this thought is the best strategy to do in these ways. Every time, we will end up getting a much longer window that is needed and forget about it and expect it to clean itself. But in the last two articles and this one, we are trying our best to configure a more event-driven means to do this cleanup once we are done processing the message.
This can also be used as our last option to delete some orphaned artifacts after a set period automatically. But it has some different purposes and we can cover them maybe in a later article.
const stgMsgBucket = new s3.Bucket(this, 'stg-msg-bucket',{
bucketName: envParams.bucket.BucketName,
encryption: s3.BucketEncryption.S3_MANAGED,
removalPolicy: RemovalPolicy.RETAIN,
lifecycleRules: [{
expiration: Duration.days(1),
prefix: "uploads",
id: "stg-msg-bucket-uploads-expiry-rule"
}]
});


putItem also returns a during object creation ☎️
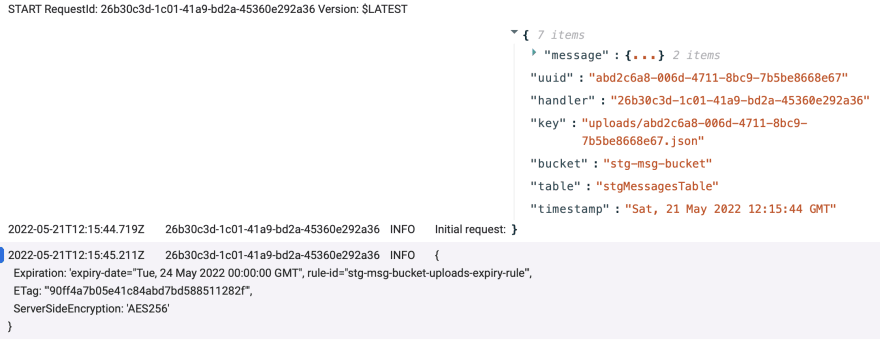
Enabling dynamodb streams in our stgMessages table 💽
This will be the source table that is supposed to generate dynamodb streams. But the difference here we have is that we will be targeting only streams which are generated when items are deleted. So we will try to remove the same key item from the s3 buckets which we have initially created.
const stgMessages = new dynamodb.Table(this, "stgMessagesTable", {
tableName: process.env.stgMessagesTable,
sortKey: { name: "createdAt", type: dynamodb.AttributeType.NUMBER },
partitionKey: { name: "messageId", type: dynamodb.AttributeType.STRING },
encryption: dynamodb.TableEncryption.AWS_MANAGED,
readCapacity: 5,
writeCapacity: 5,
stream: dynamodb.StreamViewType.KEYS_ONLY,
});
Handler function in our stack 📌
Here we have defined a handler function which we will be using our reference to grant privileges and configure to event source as shown below.
const stgMessageStreamFunc = new lambda.Function(this, "stgMessageStreamFunc", {
runtime: lambda.Runtime.NODEJS_14_X,
code: lambda.Code.fromAsset("lambda"),
handler: "stg-message-stream.deleted",
logRetention: logs.RetentionDays.ONE_MONTH,
tracing: Tracing.ACTIVE,
layers: [nodejsUtils,nodejsXray],
environment: {
STAGING_MESSAGES_BUCKET_NAME: stgMsgBucket.bucketName,
},
});
stgMessageStreamFunc.applyRemovalPolicy(RemovalPolicy.DESTROY);
Granting deleteObject privilege to handler function 📯
stgMsgBucket.grantDelete(stgMessageStreamFunc);

Configuring our dynamodb streams to handler function 🔧
stgMessageStreamFunc.addEventSource(new DynamoEventSource(stgMessages, {
startingPosition: lambda.StartingPosition.LATEST,
batchSize:100,
maxBatchingWindow: Duration.seconds(60)
}))

Coding the handler function ✂️
For this let us create a new file lambda/stg-message-stream.ts with an export method name deleted
Do note that will be targeting only the eventName like REMOVE. This will help us with the keys of the table items which are deleted and we could delete them using our handler as follow in two ways.
Single deleteObject Handler 🎺
Here will be using single Object deletion first and compare and contrast it with the batch Object deletion as shown below.
exports.deleted = async function (event: any) {
console.log("Received stream:", JSON.stringify(event, undefined, 2));
const bucketName = process.env.STAGING_MESSAGES_BUCKET_NAME || "";
const result = Promise.all(
await event.Records.map(async (Record: DynamoDBStreams.Record) => {
console.log(JSON.stringify(Record, undefined, 2));
if (Record.eventName === "REMOVE") {
const key = `uploads/${Record.dynamodb?.Keys?.messageId.S}.json`;
console.log("keyId: ", key);
const bucketParams: DeleteObjectRequest = {
Bucket: bucketName,
Key: key,
};
try {
console.log("Deleting : ", bucketParams);
const deleteObjectOutput: DeleteObjectOutput = await s3
.deleteObject(bucketParams)
.promise();
console.log("Deleted : ", bucketParams);
Object.entries(deleteObjectOutput).forEach((item) =>
console.log({ item })
);
console.log(await s3.deleteObject(bucketParams).promise());
} catch (err) {
console.log("Error", err);
}
}
})
);
Object.entries(result).forEach((item) => console.log({ item }));
};
Take away single deleteObject transaction 👜
It does not take more than 1 second to delete the s3 Object most of the time, the fact I want to highlight here is how the overhead is split among the various layers.


And this should explain how we are using a batch of 100 streams max to be processed from the same handler. The overhead is simply shared and full disclosure, we have our monitoring layers also embedded as layers and they do have some overhead.
Finally, let us find the real split up below. So you can see it takes around 50ms to 300ms to complete a single s3 Delete Object API request as highlighted below.
Notable sideeffects 🌂
If we don't batch them appropriately we will end up in the below adverse efforts and a few objects can be orphaned if we don't retry.
- loosing the compute hours due to external I/O
- maybe throttled if we have reached the throughput set for the s3 prefix on rare occasions
- And it is also possible that lambda may timeout if we are not ready to increase it
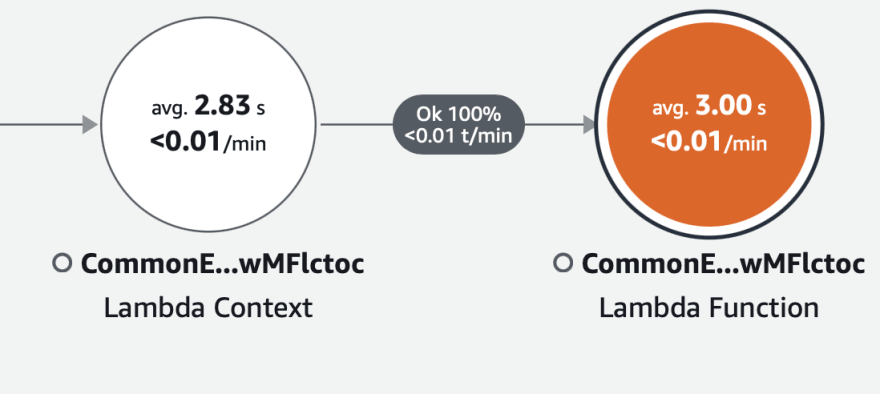

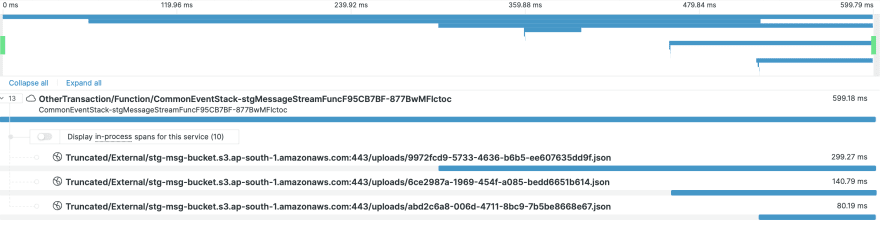
Analyzing the time taken single delete 🍝
You may find that in these newrelic traces the API request is made multiple times one after the another.
You can argue that I can make these in parallel, we will also end up throttling the API request to the s3 prefix when we create too many parallel requests when we perform many at a time in worst cases.
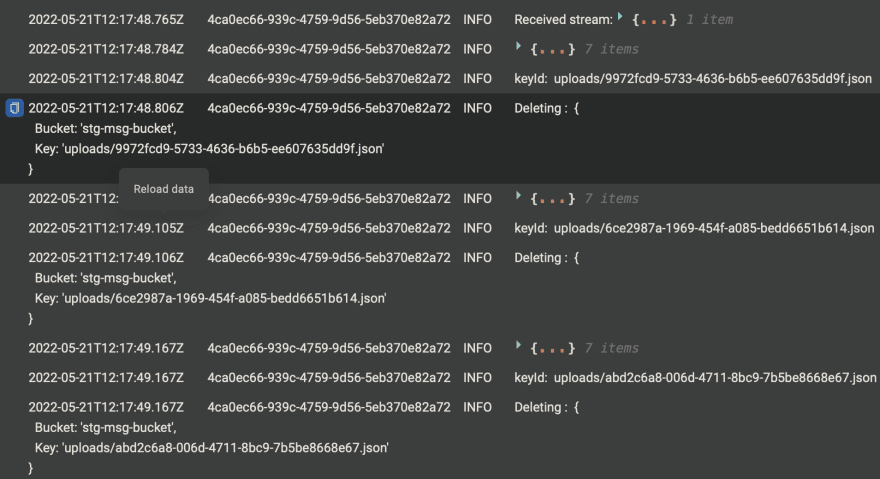
Batch deleteObjects handler 🚗
Since we are conscious of the above points, let us perform a batch request now and see the turnaround.
exports.deleted = async function (event: any) {
console.log("Received stream:", JSON.stringify(event, undefined, 2));
const bucketName = process.env.STAGING_MESSAGES_BUCKET_NAME || "";
const keyMap: any[] = [];
const result = Promise.all(
await event.Records.map((Record: DynamoDBStreams.Record) => {
console.log(JSON.stringify(Record, undefined, 2));
if (Record.eventName === "REMOVE") {
const key = `uploads/${Record.dynamodb?.Keys?.messageId.S}.json`;
console.log("keyId: ", key);
keyMap.push(key);
}
})
);
if (keyMap.length > 0) {
const bulkParams: DeleteObjectsRequest = {
Bucket: bucketName,
Delete: {
Objects: [],
Quiet: false,
},
};
keyMap.map((key) => {
const object: ObjectIdentifier = {
Key: key,
};
bulkParams.Delete?.Objects?.push(object);
});
try {
console.log("Deleting Batch : ", bulkParams);
const deleteObjectsOutput: DeleteObjectsOutput = await s3
.deleteObjects(bulkParams)
.promise();
console.log("Deleted Batch : ", bulkParams);
Object.entries(deleteObjectsOutput).forEach((item) =>
console.log({ item })
);
} catch (err) {
console.log("Error", err);
}
}
Object.entries(result).forEach((item) => console.log({ item }));
};
Sample batch generated from my k6 test 🚀
Here in this example, 26 items are taken into a single batch. But do note our batch size is 100 yet it is also possible that our items can be part of 2 successive runs as well, based on the polling window which we have set as the 60s.

Analyzing the time taken for single delete ✈️
The S3 batch delete call may take more time than the single delete, but the point to note here will be that we can avoid the overhead and latency involved exponentially when we scale this let's say up to 1000 Objects.

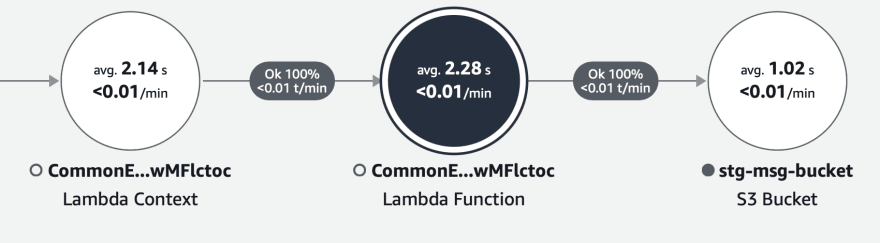
Removing the other monitoring layers causing overheads


This concludes this article.
We will be adding more connections to our stack and making it more usable in the upcoming articles by creating new constructs, so do consider following and subscribing to my newsletter.
⏭ We have our next article in serverless, do check out
https://dev.to/aravindvcyber/aws-cdk-101-event-source-mapping-with-cfn-property-override-3laa
🎉 Thanks for supporting! 🙏
Would be great if you like to ☕ Buy Me a Coffee, to help boost my efforts.


🔁 Original post at 🔗 Dev Post
🔁 Reposted at 🔗 dev to @aravindvcyber
☔️ AWS CDK 101 - ⛅️ Dynamodb streams triggering batch deleteObjects S3
— Aravind V (@Aravind_V7) May 21, 2022
@hashnode
Checkout more at my pagehttps://t.co/CuYxnKI3Kg#TheHashnodeWriteathon#typescript #awscdk #aws #serverless #thwcloud-computing https://t.co/3aoXjnp6lk

Top comments (0)