Welcome to the SQL showdown series!
What is this and how does it work?
I'm committing to publishing a SQL challenge every day for 30 days. In each post I'll describe my solution to the last day's challenge. I'll follow that up with a full description of the challenge for the next day.
Write your own solution in the comments! Let's see who can come up with the most creative solutions.
Challenge #16: Dev Badges
If you post a lot on dev.to you might have received one of their nifty badges. I just got my 4 week streak badge! It wasn't long until I started thinking about how you could identify posting streaks in SQL.
The day16 schema contains a post table with a handful of columns:
- id
- user_id
- created_at
The challenge is this:
Can you write a query that will return all users that are currently eligible for the 4 week streak badge? (At least one post per week for the last 4 weeks.)
Sandbox Connection Details
I have a PostgreSQL database ready for you to play with.
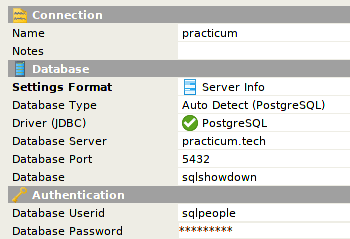
The password is the same as the username! To query the post table:
SELECT * FROM day16.post;
Solution to Challenge #15: Fuzzy Matching
Yesterday we dipped a toe into the world of fuzzy matching in databases. As a reminder, we had two tables full of info about movies, but from independent sources. We wanted to see what PostgreSQL and other databases offer when it comes to fuzzy matching.
This was the challenge from yesterday:
What fuzzy matching methods can be used to join the movie datasets together on keys such as the director name?
We have the movie and movie_plot tables that should contain quite a bit of overlapping data.
Let's try a naive approach first and join using strict equality:
SELECT count(*) from (
SELECT DISTINCT director FROM day15.movie
) AS d1
JOIN (
SELECT DISTINCT director FROM day15.movie_plot
) as d2
ON d1.director = d2.director;
Here I join the distinct set of directors from both tables together using a straightforward equality comparison. I get 478 directors in common using this technique.
What techniques can we try to discover more matches?
Levenshtein (Edit Distance)
Are we missing any potential matches due to small differences in spelling?
The Levenshtein distance between two strings defines the minimum number of insertions, substitutions, or deletions that would be required to make them equivalent. The Levenshtein function is also sometimes referred to as edit distance, because although there are other variations on edit distance, it is the most commonly used.
Before you can try out Levenshtein distance, however, you'll need to enable the fuzzystrmatch extension in PostgreSQL.
CREATE EXTENSION fuzzystrmatch;
Let's say we wanted to retry the query from above, but instead of requiring an exact match, we relax the comparison so that the strings can have an edit distance of 1.
SELECT count(*) FROM (
SELECT DISTINCT director FROM day15.movie
) AS d1
JOIN (
SELECT DISTINCT director FROM day15.movie_plot
) AS d2
ON levenshtein(d1.director, d2.director) <= 1;
This time I come up with 493 matches. Here are some of the extra matches that turned up with an edit distance of 1.
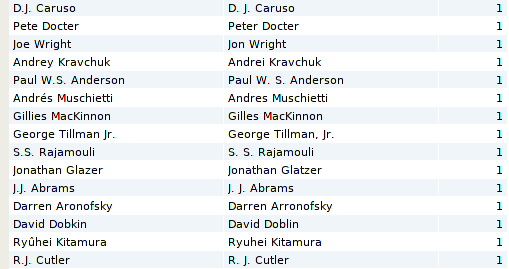
As a whole this seems to be a net improvement, but fuzzy matching is always a balancing act between improved accuracy and false positives. For example, it seems likely that Darren Aronofosky and Darren Arronofsky are the same person, while David Dobkin and David Doblin are probably not.
The usefulness of edit distance can depend on the data it is applied to. We can see with names, for example, that a single edit can be very important.
Soundex and Metaphone
Soundex belongs to a family of comparison functions that rely on the spoken sound of a word instead of comparing the characters themselves. Soundex was created almost a century ago to help with the U.S. census, and as a result, it doesn't handle non-English names very well.
The metaphone function is a more modern alternative. Let's take a look at an example:
SELECT
count(*)
FROM
(
SELECT
split_part(d.director, ' ', 1) AS first_name,
split_part(d.director, ' ', 2) AS last_name,
d.director
FROM
(
SELECT
DISTINCT director
FROM
day15.movie
) d
) AS d1
JOIN (
SELECT
split_part(d.director, ' ', 1) AS first_name,
split_part(d.director, ' ', 2) AS last_name,
d.director
FROM
(
SELECT
DISTINCT director
FROM
day15.movie_plot
) d
) AS d2 ON dmetaphone(d1.first_name) = dmetaphone(d2.first_name)
AND dmetaphone(d1.last_name) = dmetaphone(d2.last_name);
Most of the work here is involved in splitting up the director name so that I can run the metaphone function on first and last names separately.
Here's what I get back with the above query:

There are some good matches here, like Andrey and Andrei Gorlenko, but there are also a few inexplicable false positives, like Anna Biller and Wayne Blair.
PG_TRGM
PostgreSQL also supports trigram matching through the PG_TRGM extension. Trigrams are a simple, yet powerful, concept that involves breaking strings down to sets of 3 consecutive letters. The number of sets a pair of strings have in common determines their trigram score.
Getting started is pretty easy.
CREATE EXTENSION pg_trgm
The movie table has a comma delimited list of actors. Let's see if we can use trigrams to fuzzy match on a specific actor.
SELECT * FROM day15.movie WHERE 'Patrick Stewart' % ANY (string_to_array(actors, ','));
The % operator is used in place of the normal = to apply trigram matching. The ANY keyword means the expression is considered true if there is a trigram match on any of the actors in that movie.
Good luck!
Have fun, and I can't wait to see what you come up with! I'll be back tomorrow with a solution to this problem and a new challenge.

Top comments (0)