
Author: Dan Gural (Machine Learning Engineer at Voxel51)
A quick comparison of VQA vs Action Recognition for general understanding
Video Understanding is one of the more complex areas of study in Computer Vision. With its multiple modalities, time-series elements, as well as open ended questions and answers, it is hard to find a model that can deliver what you are looking for, and even harder to find one that does it well! Let’s take a quick look at some options you have today with the newly introduced to the public domain video, Steamboat Willie.
Why Understanding Our Videos is Important
Today more than ever, we are overwhelmed by the amount of data that we have. Looking at just YouTube as a source of video data, it is estimated that over 2500 Petabytes of data is stored. That is 2.5 BILLION gigabytes of data! That is only from YouTube as well! There are plenty of other troves of videos out there that are sitting in a database ready to be studied or applied to some problem. The issue is that much of these videos are unstructured or unorganized. Even videos themselves are unstructured to some extent! It is tough to tell what are the videos I am looking for and what is just noise if I just stare at the mp4 file name.
Using AI to be able to parse through millions of videos to understand if it falls into a set search criteria is a major advantage from a data science perspective. Immense amounts of data processing, training, or storage can be saved with video understanding. Ultimately, by understanding more about our video datasets, we will be able to train models to higher performance down the line.
Vision Question and Answering (VQA)
The first and easiest way to go about understanding your videos is with one of the top of the line VQA LLMs. These models have a vast knowledge of not just the human language, but the importance of context in images as well, allowing them to make nuanced discoveries between different frames. The only drawback is just that, it only works on frames or single image based prompts. The best models of today such as GPT 4, LLaVA, or ViLT, all cannot accept videos as an input. In FiftyOne, we can break up our dataset into frames and inference on each frame in order to get the idea of what is happening.
With VQA models, you can change the prompt to be whatever you like as well! Descriptions too long for you? Set a limit by prompting “Describe the image in X words or less.” You can also lean on the strengths of LLMs by prompting along the lines of “Describe this video as you would to a 5 year old” to get basic bare-bones descriptions that won’t get muddied by LLM filler text. By leveling up your prompting, you open up the possibilities for a much more robust video understanding pipeline.
We can add the answers from our VQA model of choice as a classification label and visualize the results. Let’s check them out using LLaVA-13B!
import replicate
prompt = "Describe this image in 7 words or less"
for sample in dataset:
filepath = sample.filepath
response = replicate.run( "yorickvp/llava-13b:2facb4a474a0462c15041b78b1ad70952ea46b5ec6ad29583c0b29dbd4249591",
input={"image": open(filepath, "rb"), "prompt": prompt},
)
resp_string = ""
for r in response:
resp_string += r
sample["llava-13b"] = fo.Classification(label=resp_string)
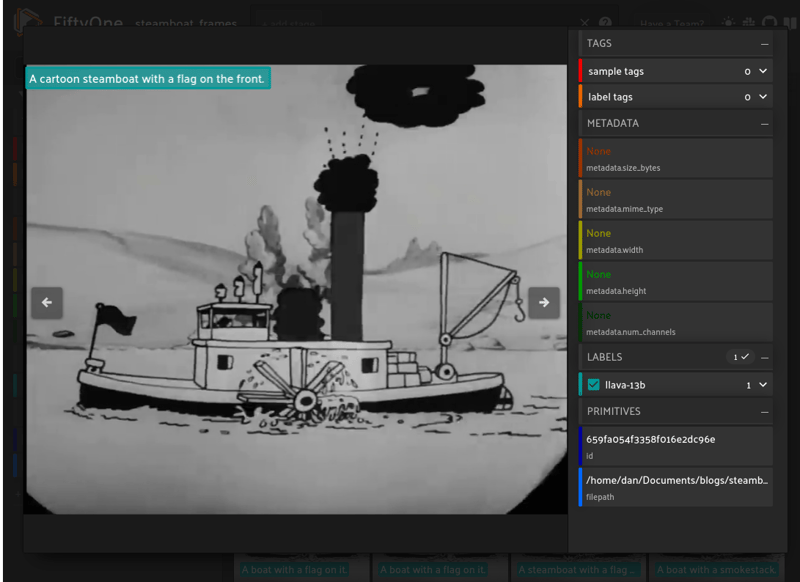
In the above example we can see LLaVA delivers the answer “A cartoon steamboat with a flag on the front” when prompted with “Describe the image in 7 words or less”. A great answer and summary of what is in the image!
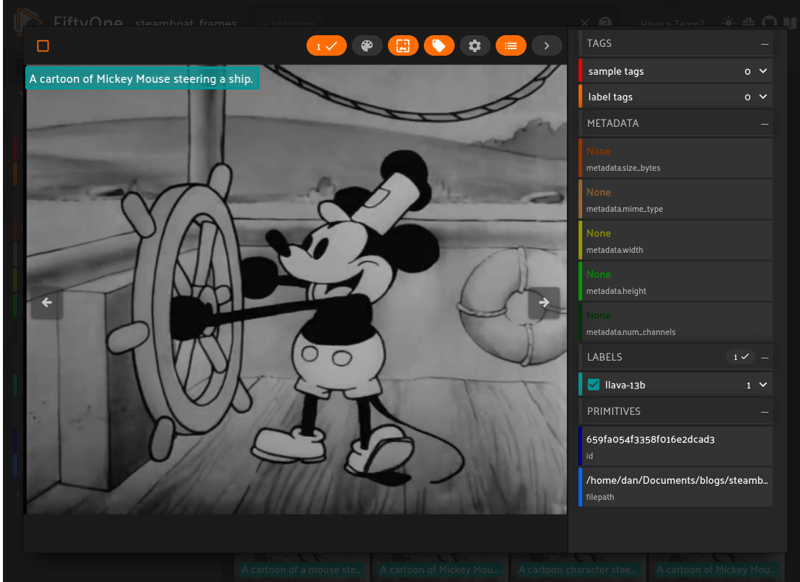
LLaVA even knows it's Mickey! It isn’t without its drawbacks, however. When Mickey goes to pull the horn for the steamboat, the whistle below blows out steam. LLaVA, since it can only see a frame at a time, misinterprets the action and gives incorrect answers.
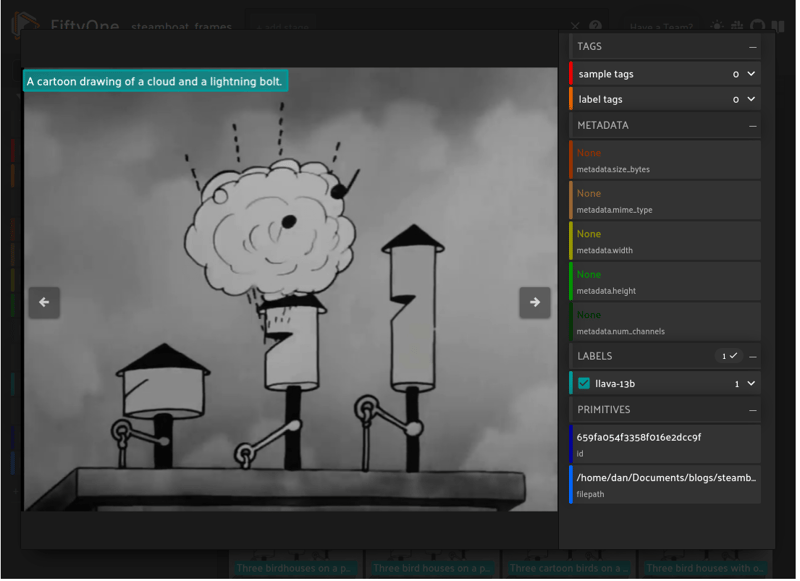
I am positive that one day models like LLaVA or GPT4 will be able to understand video as well, but until then, data curation and clever use of existing VQA can help fill the need for video understanding models for many use cases.
Action Recognition
The next suggested way to understand more about your dataset is using a large action recognition model to predict what is happening in your video. The action recognition models are almost like the opposite of VQA models when it comes to helping you with your datasets. While they are able to take in video and understand the time component of your data, they lack the broad depth of knowledge for responses and are limited to a set number of classified actions. Depending on what you are trying to find out about your dataset, this tradeoff could serve to be too costly for any meaningful analysis. Let’s look again at some examples. I will be using the mmaction2 repository to source my models.
The model I will be demonstrating is VideoMAE V2, an action recognition model from CVPR 2023.
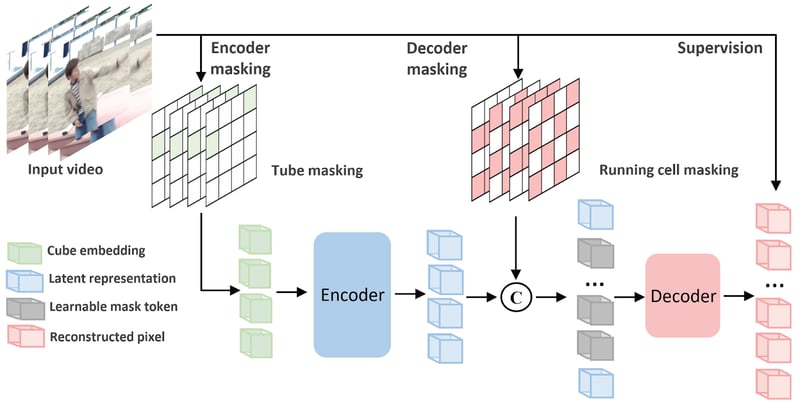
It features 400 different labels for actions and achieves state of the art performance on the Kinetics 400 and 600 datasets. It is easy to get started with the library, just follow below if interested after installing the library:
from mmaction.apis import inference_recognizer, init_recognizer
config_path = "mmaction2/configs/recognition/videomaev2/vit-base-p16_videomaev2-vit-g-dist-k710-pre_16x4x1_kinetics-400.py"
checkpoint_path = "https://download.openmmlab.com/mmaction/v1.0/recognition/videomaev2/vit-base-p16_videomaev2-vit-g-dist-k710-pre_16x4x1_kinetics-400/vit-base-p16_videomaev2-vit-g-dist-k710-pre_16x4x1_kinetics-400_20230510-3e7f93b2.pth"
model = init_recognizer(config_path, checkpoint_path, device="cuda") # device can be 'cuda:0'
for vid in dataset:
img_path = vid.filepath
result = inference_recognizer(model, img_path)
vid["maev2"] = fo.Classification(label = actions_data[result.pred_label.item()])
vid.save()
Some of the results on clips of our video perform alright like the one below:
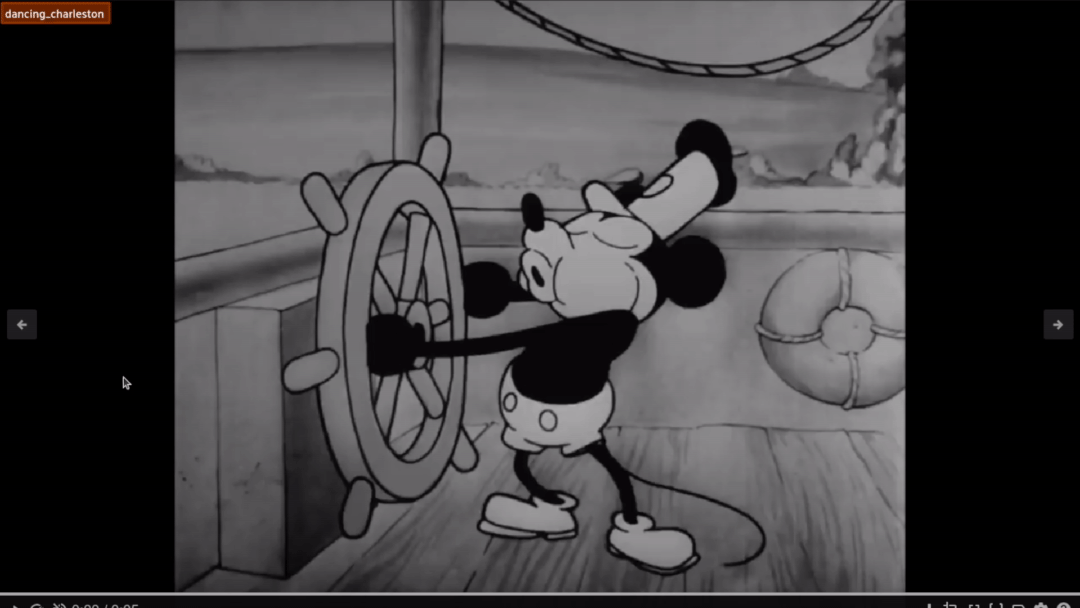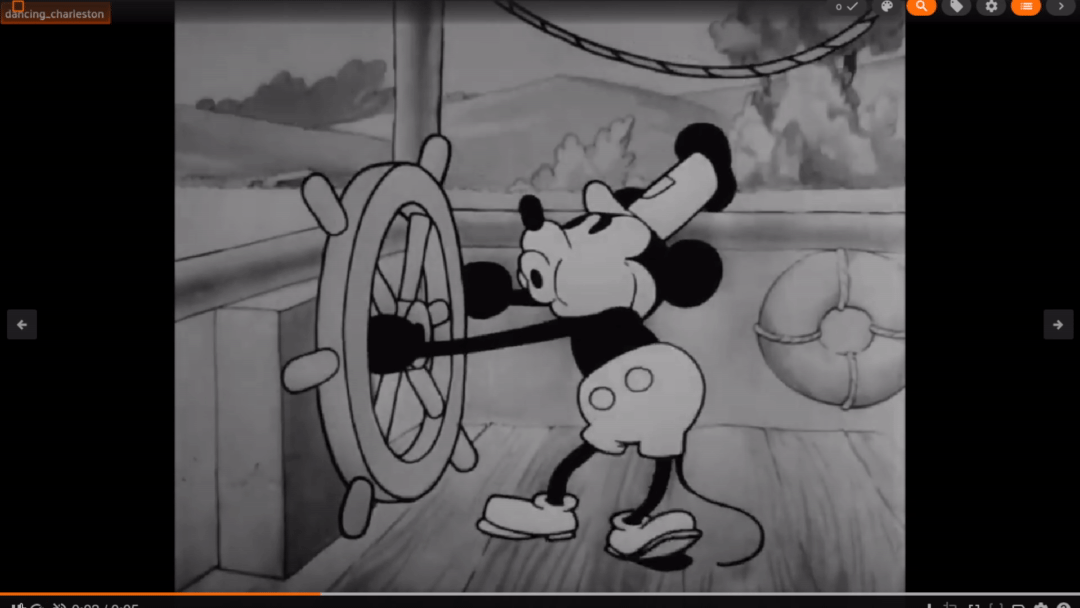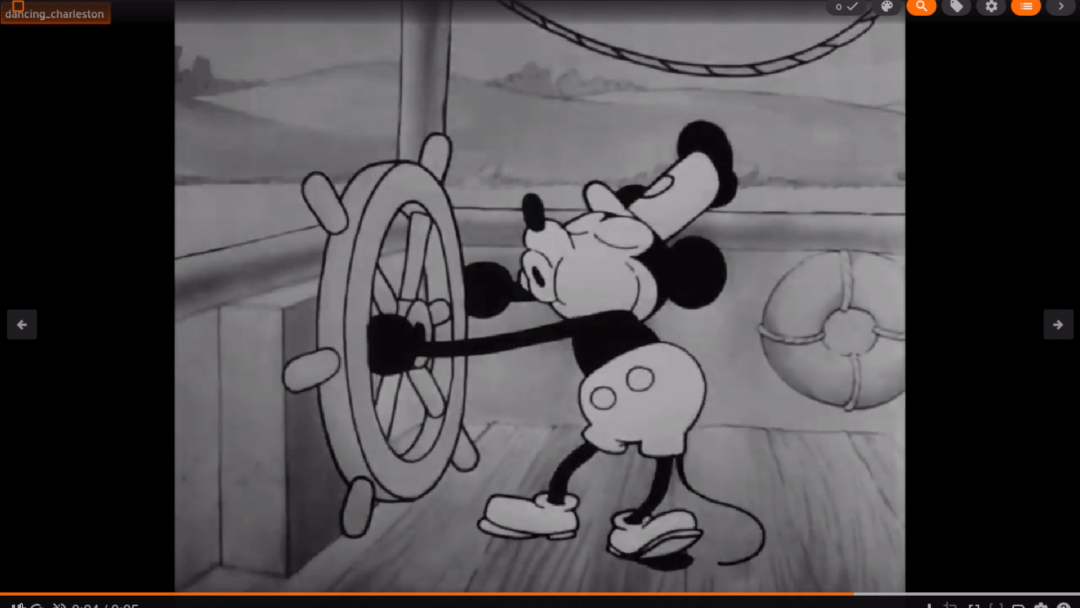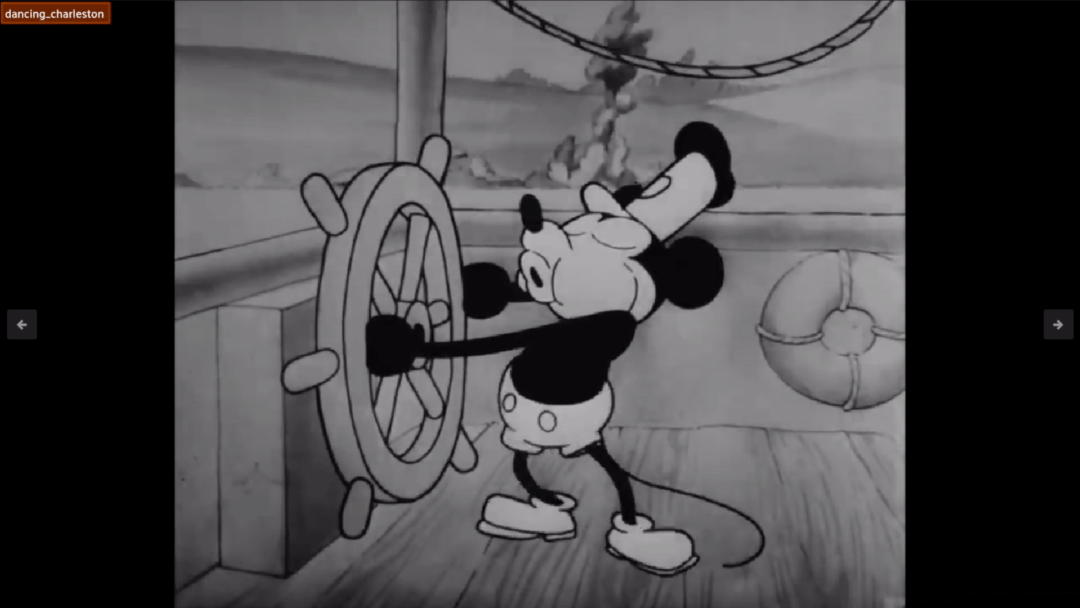
However, a lot of them miss the point like the following:
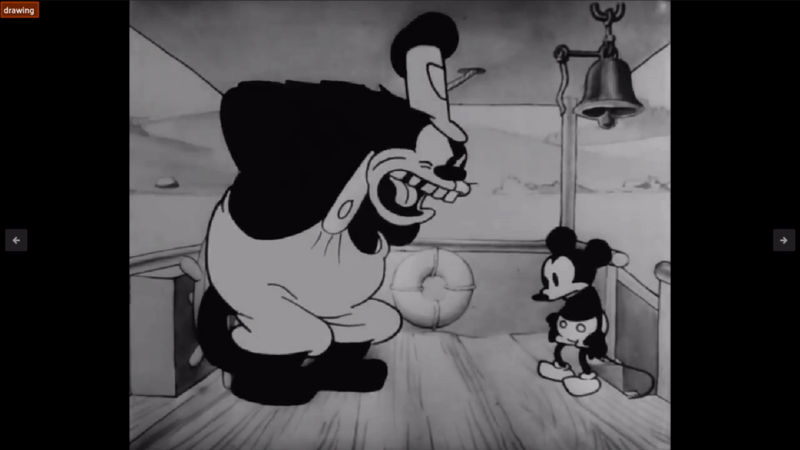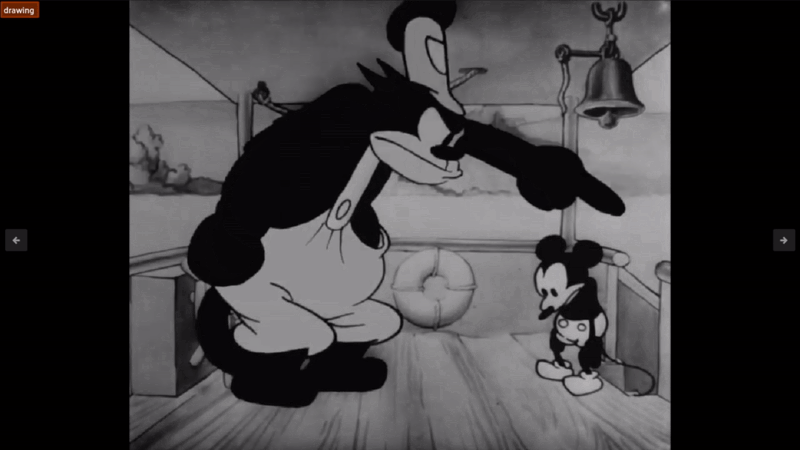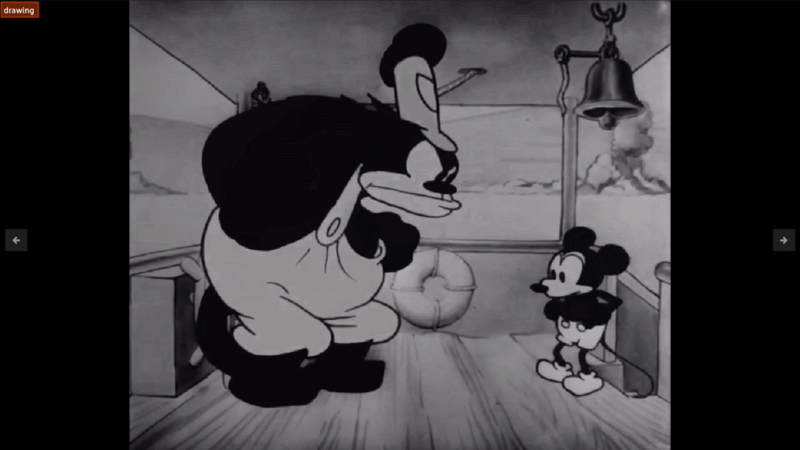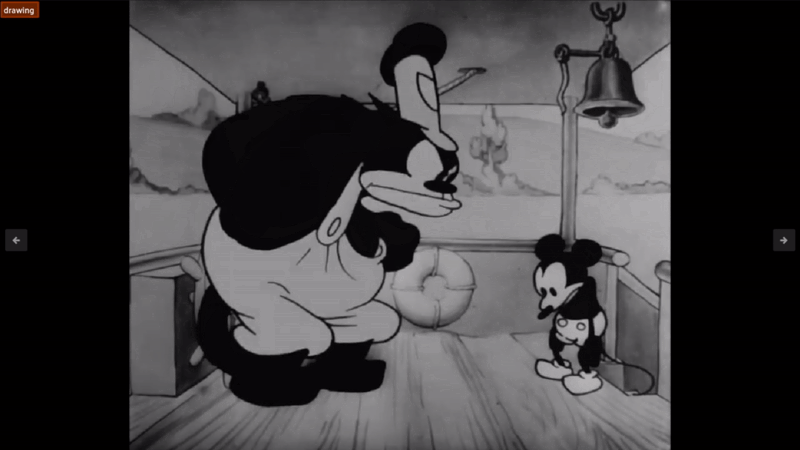
Sure, I guess it is a drawing. But it's not really the action of drawing. Also, I am concerned about what is happening inside the drawing, not just that it is a drawing! This best illustrates the issues with using an action recognition model, that it just doesn’t have the same depth as LLMs do. There are potential use cases that if you are looking for a specific one or two actions that a model like this may come in handy, but for general understanding of your video datasets, I would pass on such models and lean more towards VQA. I tried many different variants but was unable to get answers that made much sense, at least for ole Steamboat Willie here.
Conclusion
General Video Understanding is an unsolved problem today in computer vision. There are many attempts to break into space but definitely no dominant force yet. What is most interesting for me is what the evolution of Video Understanding will look like and what path will be set. There are many different approaches to conquer multimodality in computer vision, especially when it is a time-series based data like video frames. Will an old method be reinvented into a new application? Or will an entirely new algorithm be born to overcome this obstacle? Choosing what is important and what can be forgotten is a classic question machine learning engineers always iterate on and I am excited to see how they will conquer it here.
For the time being, I believe that VQA is the way to go to understanding what is happening inside your videos. If you are able to identify keyframes and efficiently generate prompts, the results should be lightyears ahead of what any other model architecture will get you.
If you are interested in trying VQA with FiftyOne, give it a shot with the VQA Plugin today! If you are interested in building your own plugins, hop into the community slack to join other developers and get access to tons of resources!
What’s Next?
If you like what you see on GitHub, give the project a star.
Get started! We’ve made it easy to get up and running in a few minutes.
Join the FiftyOne Slack community, we’re always happy to help.





Top comments (0)