
When we talk about things going wrong, often the first question we want to answer is how exactly they went wrong. This is especially true in the world of software, but is also a good rule of thumb to generally follow in life, too. Understanding a problem better is what equips us to begin finding a solution for it.
In the realm of distributed systems, this is true to another level. The ways that we talk about a problem are the ways that help us better understand what the root cause of the problem might look like. In other words, when we find points of failure in a system, being able to identify those points can help us understand what part of the system is at fault, too.
Failure classification is an important part of understanding how to build and design for fault-tolerant systems. Of course, complete fault-tolerance isn’t really possible, but we do try and strive towards it! Similar to how we recently learned how to identify faults, we need to know how to talk about and point at failures, too! So let’s get right to and learn about the different modes of failure.
How we talk about failure
In our recent deep-dive into faults, we learned that faults can present themselves in different ways and come and go, or sometimes stay around permanently. We now know that there is a domino effect that occurs in a system with a fault that becomes active (rather than latent) — namely, things start to go very, very wrong!

A fault, which can originate in any part of a system, can cause unexpected behavior, which results in an unexpected result, or an error. If that error isn’t handled in some way or hidden from the rest of the system, the originating node — where the fault first presented itself — will return that error, which is what we also call a failure. When we talk about different kinds of failures in a system, which could come from different kinds of faults, we can categorize them in different ways.
The different classifications for the kinds of failures we see in a distributed system are also known as failure modes. Failure modes are how we can identify the exact way that a system has failed. Interestingly, failure modes are classified somewhat holistically; that is to say, when we try to identify what kind of failure we’re dealing with, we take the whole system into account.
We can classify failures based on how they are perceived by the rest of the system; the way that the other nodes in a system view or perceive a failure can help us understand what kind of failure it is.
This will make more sense as we look at some specific modes of failure. Between this post and the next one, we’ll take a closer look at crash failures, omission failures, timing failures, response failures, and arbitrary failures.

As we learn about each of these modes of failure between this post and the next, we’ll start to see how each of these failures have a significant impact on an entire system, and how the different nodes in a distributed system may perceive different failures in various ways.
So, let’s dig right in and see how fast we can…well, fail!
Waiting for an untimely response
While we know that having a ready and available distributed system is something that we all strive for, complete uptime is incredibly hard, especially as a system grows. One of the key hurdles that we have to face when trying to design an available system is dealing with things like network issues hardware failures.
Handling and accounting for unexpected slowdowns makes it trickier for us to ensure reliable communication between the different nodes in a system. Often times, one of the ways to account for potential communication delays is by setting an expected time interval , or a certain amount of time that you expect something to happen. For example, we could decide that the nodes in our system must respond between 5 and 15,000 milliseconds (equivalent to 0.005 and 15 seconds), so our expected time interval is the range of time between the lower and upper bound of that interval.
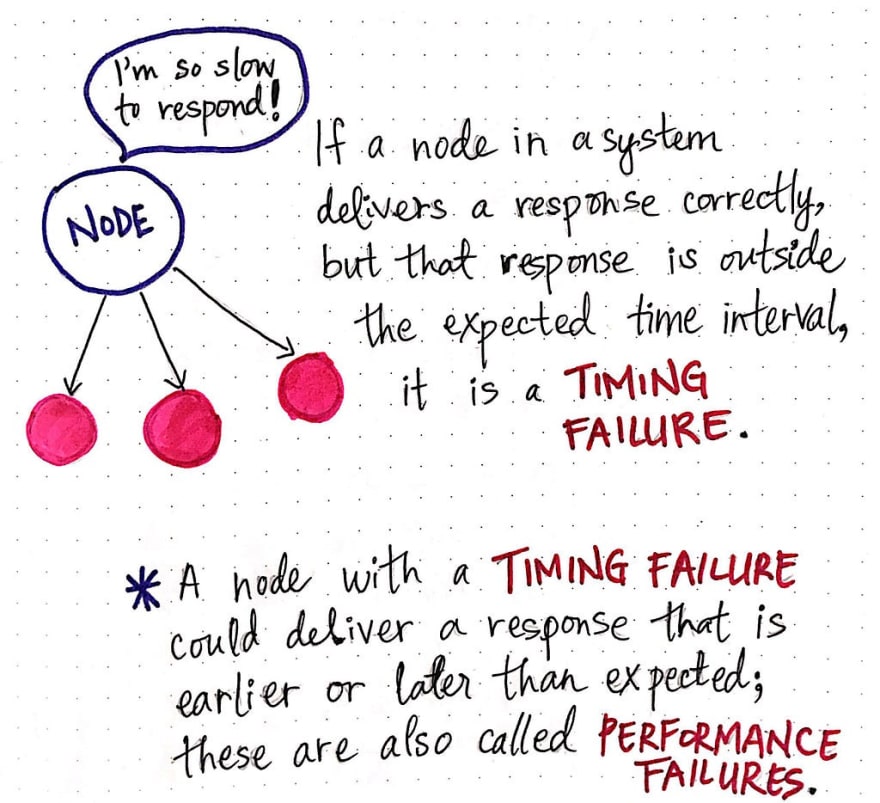
If a node is communicating with other nodes in a system and sends a response within that expected time interval, then all is well, and things are behaving in a way that we accounted for. However, what happens if a node sends a message that takes so long that it exceeds our expected time interval?
Well, we’ve now run into some unexpected behavior; we expected all the nodes in our system to be able to send and receive messages within a certain time interval, but a node exceeds that time interval, we may not have accounted for it! Seems bad.
This specific situation is known as a timing failure , which occurs when the amount of time that a node in a system takes to respond occurs outside of the expected time interval.
It’s important to note two things when it comes to timing failures:
- The node could take too long to deliver a response (exceeding the upper bound of the expected time interval), but it could also deliver a response earlier than expected, too (exceeding the lower bound of the expected time interval).
- The node is actually delivering the correct value — that’s not the unexpected part of the failure; what’s unexpected is the amount of time it took to deliver the correct value!
Timing failures are also known as performance failures , since they actually do respond with the correct message eventually, but the amount of time that they take to do indicates and issue with that node’s performance. The other nodes in the system will perceive performance failures as them having to wait around for a node that isn’t responding within the bounds of the expected time interval; they’ll view the failing node as being unexpectedly slow or fast to respond to a message in the system.
However, even timing failures can have their own subsets of failures, too. Take, for example, a node that isn’t just taking a long time to respond but actually just…doesn’t ever end up responding! What then? Well, in that case, a node basically is taking an “infinitely late” amount of time to respond, which is also known as an omission failure.

When a node seems to actually never get around to receiving or sending a message to the rest of the system, the other nodes perceive this as a kind of “special case” of a timing failure. If the node just fails to reply, it effectively omits any response, which is how omission failures get their name. Omissions failures in a node are particularly unique because, depending on how long a node neglects a response, bad things can happen.
But fear not — let’s find out exactly what those bad things are so that we know how to watch out for them!
Omitted replies (or, tfw things come crashing down)
Omission failures themselves come in two forms; if we really think about it, this starts to make sense since a node can both send a message or receive a message from somewhere else. Thus, a node could either fail to ever send a message (and be “infinitely late” in sending a response to elsewhere), or fail to ever receive a message (and be “infinitely late” in receiving a response from elsewhere).

By extension, we can further classify omission failures based on these two specific outcomes. When a node fails to send a response entirely, we refer to that as a send omission failure. Similarly, if a node fails to receive an incoming message from another node and doesn’t acknowledge the fact that it received another node’s response, we call that a receive omission failure.
As we might be able to imagine, in both of these instances, the rest of the system might start to get worried! Well, nodes can’t quite “worry_”_, but they can hopefully recognize problems. Ideally, the other nodes would see an omission failure in another node and mark it as an issue. Maybe — if we were smart when we designed this system — we have a plan for accounting for either of these omission failures, like resending the message, or asking another node for the whatever information the failing node didn’t provide us with.
But what happens if that node just keeps…ignoring everyone? Well, that’s when we say that things crashed! Or more specifically, that a crash failure occurred.

A crash failure occurs when a node suffers from an omission failure once, and then continues to not respond. To the rest of the system, that crashed node looks like it once was responding correctly, then omitted a response once, and subsequently stopped responding!
It might seem like crash failures are super scary, but sometimes the solution to dealing with this kind of failure could be as simple as just restarting the node. And, as we’ll soon learn, crash failures aren’t even the most mind-bending failures to deal with; there are some scarier failures out there that much more complicated contenders. But, I’ll save that for part two of this series.
Until then, happy failing!
Resources
Fault tolerance and failure are main topics in the world of distributed systems, especially since working within and building a distributed system requires us to consider potential causes of faults and how to deal with failure along the way. If you’d like to keep learning about different mode of failure, there are lots of resources out there; the ones below are, in my opinion, some of the best ones to start with.
- Fault Tolerance in Distributed Systems, Sumit Jain
- Failure Modes in Distributed Systems, Alvaro Videla
- Distributed Systems: Fault Tolerance, Professor Jussi Kangasharju
- Understanding Fault-Tolerant Distributed Systems, Flaviu Cristian
- Failure Modes and Models, Stefan Poledna
- Fault Tolerant Systems, László Böszörményi

Top comments (0)