
So much of what makes distributed systems hard to contend with is the fact that, as a system grows, it changes. Furthermore, the things around the system — parts of the system itself, its dependencies, and the people who maintain it — are also each capable of changing as well.
In part one of this series, we looked into the first four of the famous eight fallacies of distributed computing. Conveniently, those four fallacies all centered around the network, and the misconceptions and falsehoods that many developers can fall prey to when they are dealing with a distributed system. But in part two of this series, we’re going to zoom out a bit and look at the remaining four fallacies, which feel far more abstract in nature, in my opinion.
What’s interesting to me about the second half of the fallacies is the fact that they almost seem obvious to us at first glance. You may even read them and think to yourself, “how could anyone ever assume this fallacy to be true?”. But as we’ll soon see as we dig into each of them, there’s more to each fallacy than meets the eye. And keeping these big-picture truths in check as we design a simple system or a complex one is harder to do than we might think. So let’s dive right in and finish up our foraging for fallacies!
Rearranging the network
As we already know, nodes in a distributed system must communicate via messages, which are sent through a network. However, that network is a changing, fluctuating entity. If a node is added to network, it inherently will look a little different, right? We have a new character on the stage, and the way that the network looks or how it is arranged differs depending on which nodes are involved.

As it turns out, there’s a term for this concept, and it’s high time that we familiarized ourselves with it: topology. A network’s topology is the way that the elements in the network are laid out or arranged.
Topology illustrates the way that the nodes in our distributed system relate or connect to one another, and more importantly, how they communicate with one another.
For example, we could have a set of nodes in a network that are connected and communicate with one another in a ring shape, or we could have all the nodes connected in a line. Or, like in the example above, the nodes could be connected in star shape, or perhaps they could be arranged in a tree shape. All of these different examples are valid ways to lay out the nodes in a network, and each of them are different topologies.
Understanding the concept of a topology is essential to us grappling with fallacy five: Topology doesn’t change. Remember that this is a fallacy, which means that it is a misconception; in other words, this statement is untrue, and the topology of a network does, in fact, change.

At the surface, this statement might seem obvious; any time that we add, replace, or remove a node from our network, the way that the elements (nodes) of that network are arranged and how they relate to one another is invariably going to have to be flexible and move around to be able to handle these changes. Given what we know about how nodes can be flawed and how they will fail, we also can be sure that the frequency with which a new node might be added or an old node might be removed or replaced is going to be fairly consistent and high. In other words, the network’s topology is always going to be in flux and fluid!
So why is this otherwise obvious fallacy something worth noting here? Well, what makes this fallacy tricker than it seems is the fact that most of us just don’t think about the obviousness of it on a day-to-day basis. We often depend on the network behaving a certain way and doing certain things. Sometimes, we explicitly depend on the topology of the network being arranged in a certain way. For example, if our system sent messages every 30 seconds to a node in the system, and expects that node to exist at a certain location in the network, what happens if that node disappears? Or what if it moves?
If we depend on our network always “looking” a certain way, and if we expect for its nodes to always be arranged a certain way, we fall into the trap of this fallacy. And this can be an easy assumption to make, especially if we don’t take this fallacy into to account in our daily interactions as designers and maintainers of a distributed system! So, it’s up to us to consider the ways that we might be relying — even if inadvertently — on the topology of our system’s network.
System management realities
Assumptions are very easy things to make — we make them all the time! Not only can we make bad assumptions about our system and what it looks like and how it will behave in certain circumstances, but we can also make bad assumptions about who will be maintaining and dealing with that system at any given time.

This is brings us to fallacy six: There is one administrator. In nearly all real-life scenarios, there is usually more than one administrator of a distributed system. With the exception of very small applications — or perhaps a system that is a toy/hobby project that only has one person building and maintaining it — most systems end up with many people involved in the maintenance of the system.
Assuming that only one administrator exists to maintain a distributed system can have long term side-effects. For example, imagine a system where three administrators are helping to keep the system up and afloat. What happens if one of those administrators — who just so happens to be an expert in one of the aspect of the system — leaves the team? Or, what if one of the parts of the system is actually a dependency and part of an external service?
In both of these situations, one part of the system is likely under the control of someone else, and we have to consider what we’ll do if that section of the system needs maintenance, or what will happen (and who will fix the problem, not to mention how quickly) if that section of the system goes down!
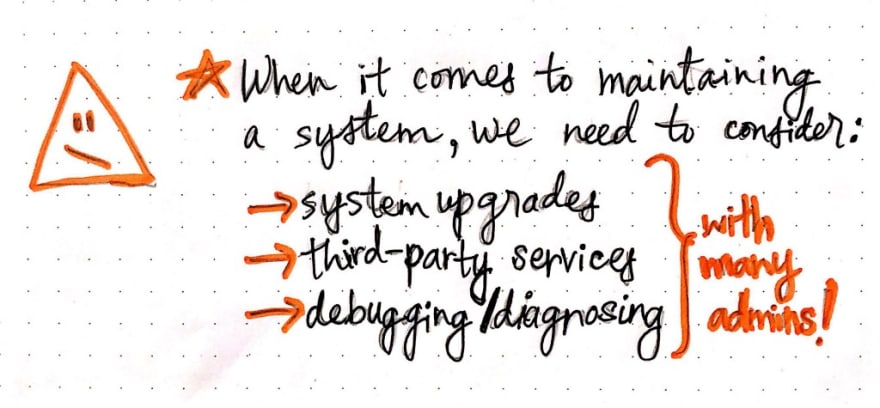
The sixth fallacy is really important to keep in mind (and it’s so easy to forget about entirely!). We already know that regular tasks like maintaining and upgrading a system are responsible for causing a great deal of software bugs. So when a system has many administrators, it’s our responsibility to make sure that the system can still be easily upgraded and maintained as more and more admins are added to the mix. Similarly, if our system depends on a third-party service, we need to consider who those external administrators are, and how we’ll handle an external dependency that needs attention.
We also need to be sure to have a way to empower all administrators of a system to debug and diagnose different parts of the system. This last piece of the puzzle is especially important, because administrators can make important decisions — like restarting a node, limiting a quantity of data, or deciding what protocols to use — and those decisions are crucial to managing a system and keeping it running correctly.

Another “easy to dismiss” assumption is the reality of the cost of running a system. This leads us right to fallacy seven: Transport cost is zero. As we learned with fallacy two, it takes time for data to travel from one place to another; another name for this amount of time is latency. Similarly, the cost of sending data from one place to another also has other costs, too!
For example, it takes resources to be able to transport any data from one place to another within a distributed system. These resources have a price tag attached to them, and these resources cost money.
Additionally, sending data from one place to another also takes some effort and time to turn the data into a machine-readable code (and subsequently, back out of machine-readable code into data again). These processes are known as serialization and deserialization , and all data that is passed around in the system needs to be serialized and deserialized from a byte stream into some object in memory that is used to represent that data. Many developers are familiar with serialization and deserialization and use it every day; however, not all of us are necessarily considering the time and effort that these two processes take whenever they happen!
The fact that it costs time, effort, and resources remind us that it is not free to send data through our system and transport information back and forth. However, it can be easy to forget this until we get an unexpected bill from AWS or Heroku, at which point we suddenly remember this reality. Keeping this fallacy in mind is especially important as our system scales and our transport costs start to creep up on us.
Standardization of a system
The final fallacy is one that many of us may not have ever thought about, particularly if we have been working with frameworks and systems that have already been around for some time. The eighth fallacy brings us back to our good old friend, the network: The network is not homogeneous. Many of us probably know this fallacy to inherently be false: the nodes in a network can be anything, so there is no guarantee that they will all be the same!
In fact, most distributed systems may integrate with different kinds of devices, perhaps different protocols, and almost certainly will adapt to work with various operating systems and browsers. And because the nodes of our network(s) aren’t going to all look the same, it’s not always safe to assume that they will all be configured the same, either.

Indeed, most networks are heterogenous, but the nodes in a system’s network still need to work together and be interoperable. Conveniently, however, most of us don’t need to fear this fallacy; this is where standardization comes in to save the day! Most systems these days are architected to rely upon and utilize standardized formats that are created to create a shared language amongst different elements in a system, even if they perhaps aren’t all configured the same.
Many of us use these standards — like HTTP protocols, REST APIs, and JSON-formatted data — on a daily basis, and these standards make it much easier to deal with a heterogeneous network. But it’s still important to remember this fallacy in the off chance that one day, we find ourselves building a part of a system that isn’t using a standardized format! Rolling a proprietary protocol of one’s own means that, down the road, there will most likely be another node that will be incompatible with our non-standard format.
In fact, I think it’s worth thinking about all eight fallacies, even if we are working with systems that have been built so that we don’t need to consider these issues. Just because we don’t run into these fallacies on a daily basis doesn’t mean that they’re not powerful! In fact, they can sneak up on us just when we’re not looking, and prove that even the most experienced distributed systems engineers can make bad assumptions.
Resources
The fallacies of distributed computing have been fairly well-written about, and you can find some good resources on different interpretations of them, for different technologies. If you’re curious to learn more, check out the resources below!
- Fallacies of Distributed Computing Explained, Arnon Rotem-Gal-Oz
- Understanding the 8 fallacies of Distributed Systems, Victor Chircu
- Debunking the 8 Fallacies of Distributed Systems, Ramil Alfonso
- Fallacies of Distributed Systems, Udi Dahan
- The Fallacies of Distributed Computing Reborn: The Cloud Era, Brian Doll

Top comments (0)