
Checkout UltraAI.app — AI command center for your product.
Semantic caching, model fallbacks, rate limiting user, logging & analytics, A/B testing — all in one place, in minutes.
What's semantic caching?
Semantic caching in large language models (LLMs) is a technique that stores the meaning of a query or request, rather than just the raw data, to reduce the number of queries a server needs to process. It works by recalling previous queries and their results based on their meaning.
Why not regular caching?
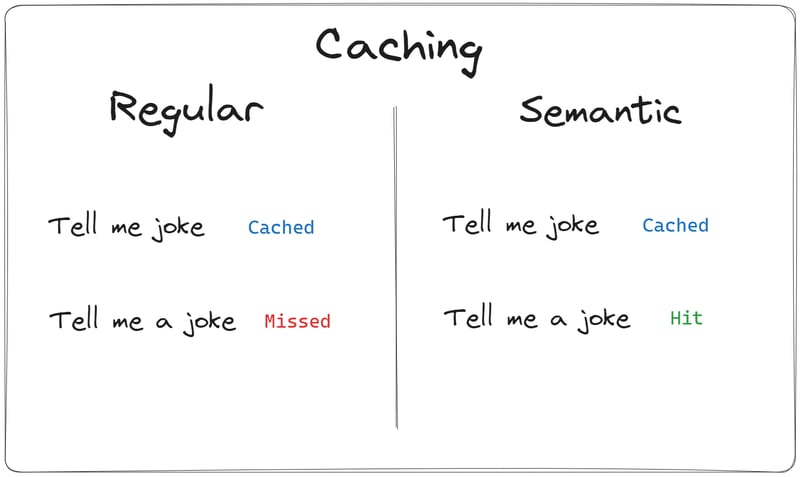
Using an exact match approach for LLM caches is less effective due to the complexity and variability of LLM queries, resulting in a low cache hit rate.
Semantic caching significantly reduce server load, shorten data retrieval time, lower API call expenses, and improve scalability
How does it work?
When a new query is received, the system searches for a similar meaning in the cache and returns the stored result if it finds a match, thus reducing the need for processing the new query. This approach can be particularly useful for complex queries involving multiple tables or data sources.
By using vector embeddings and advanced text manipulation, semantic caching can identify the core query and provide the answer in a fraction of the initial time, thus enhancing the efficiency of LLMs.
Overall, semantic caching in LLMs is a powerful tool that can enhance the efficiency of servers and application user experiences by storing query and request meaning, decreasing the number of queries that need to be processed, and allowing results to be served quickly and accurately.





Top comments (0)