Intro
In this blog post, we'll go through the process of extracting data from Google Maps Place results using Python. You can look at the complete code in the online IDE (Replit).
In order to successfully extract Google Maps Reviews, you will need to pass the data_id parameter, this parameter is responsible for reviews from a specific place. You can extract this parameter from local results. Have a look at the Using Google Maps Local Results API from SerpApi blog post, in which I described in detail how to extract all the needed data.
If you prefer video format, we have a dedicated video that shows how to do that: Web Scraping all Google Maps Place Reviews with SerpApi and Python.
What will be scraped
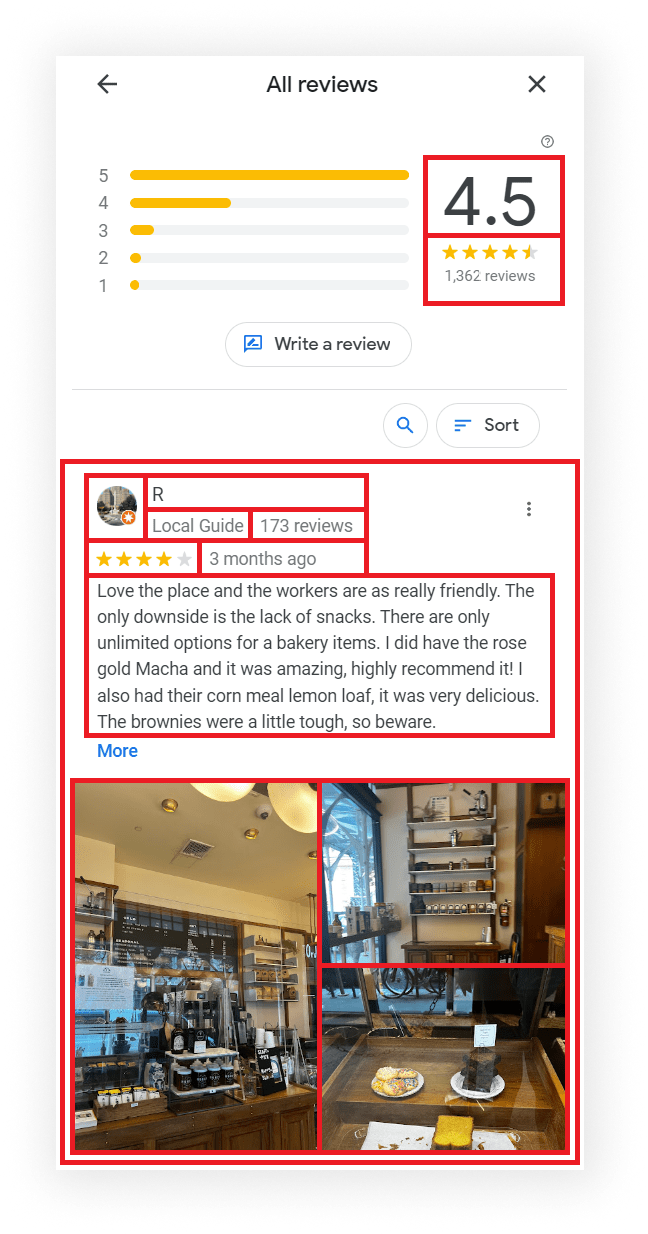
Why using API?
There're a couple of reasons that may use API, ours in particular:
- No need to create a parser from scratch and maintain it.
- Bypass blocks from Google: solve CAPTCHA or solve IP blocks.
- Pay for proxies, and CAPTCHA solvers.
- Don't need to use browser automation.
SerpApi handles everything on the backend with fast response times under ~2.5 seconds (~1.2 seconds with Ludicrous speed) per request and without browser automation, which becomes much faster. Response times and status rates are shown under SerpApi Status page.

Full Code
If you just need to extract all available data about the place, then we can create an empty list and then append extracted data to it:
from serpapi import GoogleSearch
from urllib.parse import urlsplit, parse_qsl
import os, json
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_maps', # SerpApi search engine
'q': 'coffee', # query
'll': '@40.7455096,-74.0083012,15.1z', # GPS coordinates
'type': 'search', # list of results for the query
'hl': 'en', # language
'start': 0, # pagination
}
search = GoogleSearch(params) # where data extraction happens on the backend
results = search.get_dict() # JSON -> Python dict
local_results_data = [
(result['title'], result['data_id'])
for result in results['local_results']
]
reviews_results = []
for title, data_id in local_results_data:
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_maps_reviews', # SerpApi search engine
'sort_by': 'qualityScore', # most relevant reviews
'hl': 'en', # language
'data_id': data_id # place result
}
search = GoogleSearch(params)
reviews = []
# pagination
while True:
new_reviews_page_result = search.get_dict()
reviews.extend(new_reviews_page_result['reviews'])
if new_reviews_page_result.get('serpapi_pagination').get('next') and new_reviews_page_result.get('serpapi_pagination').get('next_page_token'):
search.params_dict.update(dict(parse_qsl(urlsplit(new_reviews_page_result.get('serpapi_pagination', {}).get('next')).query)))
else:
break
reviews_results.append({
'title': title,
'reviews': reviews
})
print(json.dumps(reviews_results, indent=2, ensure_ascii=False))
Preparation
Install library:
pip install google-search-results
google-search-results is a SerpApi API package.
Code Explanation
Import libraries:
from serpapi import GoogleSearch
from urllib.parse import urlsplit, parse_qsl
import os, json
| Library | Purpose |
|---|---|
GoogleSearch |
to scrape and parse Google results using SerpApi web scraping library. |
urlsplit |
this should generally be used instead of urlparse() if the more recent URL syntax allowing parameters to be applied to each segment of the path portion of the URL (see RFC 2396) is wanted. |
parse_qsl |
to parse a query string given as a string argument. |
os |
to return environment variable (SerpApi API key) value. |
json |
to convert extracted data to a JSON object. |
At the beginning of the code, you need to make the request in order to get local results. Then place results will be extracted from them.
The parameters are defined for generating the URL. If you want to pass other parameters to the URL, you can do so using the params dictionary:
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_maps', # SerpApi search engine
'q': 'coffee', # query
'll': '@40.7455096,-74.0083012,15.1z', # GPS coordinates
'type': 'search', # list of results for the query
'hl': 'en', # language
'start': 0, # pagination
}
Then, we create a search object where the data is retrieved from the SerpApi backend. In the results dictionary we get data from JSON:
search = GoogleSearch(params) # where data extraction happens on the backend
results = search.get_dict() # JSON -> Python dict
At the moment, the first 20 local results are stored in the results dictionary. If you are interested in all local results with pagination, then check out the Using Google Maps Local Results API from SerpApi blog post.
Data such as title and data_id are extracted from each local result. These data will be needed later:
local_results_data = [
(result['title'], result['data_id'])
for result in results['local_results']
]
Declaring the reviews_results list where the extracted data will be added:
reviews_results = []
Next, you need to access each place's reviews separately by iterating the local_results_data list:
for title, data_id in local_results_data:
# data extraction will be here
These parameters are defined for generating the URL for place results:
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_maps_reviews', # SerpApi search engine
'sort_by': 'qualityScore', # most relevant reviews
'hl': 'en', # language
'data_id': data_id # place result
}
| Parameters | Explanation |
|---|---|
api_key |
Parameter defines the SerpApi private key to use. |
engine |
Set parameter to google_maps_reviews to use the Google Maps Reviews API engine. |
sort_by |
Parameter is used for sorting and refining results. qualityScore - the most relevant reviews. |
hl |
Parameter defines the language to use for the Google Maps Reviews search. It's a two-letter language code, for example, en for English (default), es for Spanish, or fr for French). Head to the Google languages page for a full list of supported Google languages. |
data_id |
Parameter defines the Google Maps data ID. Find the data ID of a place using our Google Maps API. |
Then, we create a search object where the data is retrieved from the SerpApi backend:
search = GoogleSearch(params)
Declaring the reviews list where the extracted data from the current place will be added:
reviews = []
In order to get all reviews from a specific location, you need to apply pagination while the next_page_token is present. Therefore, an endless loop is created:
while True:
# pagination from current page
In the new_reviews_page_result dictionary we get a new package of the data in JSON format:
new_reviews_page_result = search.get_dict()
Expanding the reviews list with new data from this page:
reviews.extend(new_reviews_page_result['reviews'])
# place_rating = new_reviews_page_result['place_info']['rating']
# place_reviews = new_reviews_page_result['place_info']['reviews']
# user_name = new_reviews_page_result['reviews'][0]['user']['name']
# user_thumbnail = new_reviews_page_result['reviews'][0]['user']['thumbnail']
# date = new_reviews_page_result['reviews'][0]['date']
📌Note: In the comments above, I showed how to extract specific fields. You may have noticed the new_reviews_page_result['reviews'][0]. This is the index of a review, which means that we are extracting data from the first review. The new_reviews_page_result['reviews'][1] is from the second review and so on.
There is a condition inside the loop. If the next_page_token is present, then the search object is updated. Else, the loop is stopped:
if new_reviews_page_result.get('serpapi_pagination').get('next') and new_reviews_page_result.get('serpapi_pagination').get('next_page_token'):
search.params_dict.update(dict(parse_qsl(urlsplit(new_reviews_page_result.get('serpapi_pagination', {}).get('next')).query)))
else:
break
After pagination, we append title and reviews from this place in the reviews_results list:
reviews_results.append({
'title': title,
'reviews': reviews
})
After the all data is retrieved, it is output in JSON format:
print(json.dumps(reviews_results, indent=2, ensure_ascii=False))
Output
[
{
"title": "Stumptown Coffee Roasters",
"reviews": [
{
"link": "https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sChZDSUhNMG9nS0VJQ0FnSUR1cV9qRlNBEAE!2m1!1s0x0:0x79d31adb123348d2!3m1!1s2@1:CIHM0ogKEICAgIDuq_jFSA%7CCgwIwo-0mAYQ0NDVjgI%7C?hl=en-US",
"user": {
"name": "R",
"link": "https://www.google.com/maps/contrib/103419305671938156693?hl=en-US&sa=X&ved=2ahUKEwiuzP-93eH7AhX8CTQIHa7rDQIQvvQBegQIARBB",
"thumbnail": "https://lh3.googleusercontent.com/a-/ACNPEu835-47-Efj2vFl3OshpYVrCZ9OJuM1EoPf7ddsRA=s40-c-c0x00000000-cc-rp-mo-ba5-br100",
"local_guide": true,
"reviews": 173,
"photos": 631
},
"rating": 4.0,
"date": "3 months ago",
"snippet": "Love the place and the workers are as really friendly. The only downside is the lack of snacks. There are only unlimited options for a bakery items. I did have the rose gold Macha and it was amazing, highly recommend it! I also had their corn meal lemon loaf, it was very delicious. The brownies were a little tough, so beware.",
"likes": 1,
"images": [
"https://lh5.googleusercontent.com/p/AF1QipPuq2-phPjiUCRQNKvm9TiWRymo99F98n-6v6Rx=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPFfVtTCFKV9n-uOBqTTOHuRemFBg0PWN7xdVxp=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPS83odNnZfdhZo-jNyVSMFrkwvjS2sxoiOZuB7=w100-h100-p-n-k-no"
]
},
... other reviews
]
},
... other places
]
📌Note: You can view playground or check the output. This way you will be able to understand what keys you can use in this JSON structure to get the data you need.
Links
Add a Feature Request💫 or a Bug🐞

Top comments (0)