Intro
In this blog post, we'll go through the process of extracting all the data that appears in Bing organic search results using the Bing Search Engine Results API and other APIs contained in the dropdown below.
Used APIs:
- Bing Search Engine Results API
- Bing Ad Results API
- Bing Answer Box API
- Bing Inline Images API
- Bing Inline Videos API
- Bing Knowledge Graph API
- Bing Local Pack API
- Bing Organic Results API
- Bing Recipes Results API
- Bing Related Questions API
- Bing Related Searches API
You can look at the complete code in the online IDE (Replit).
What will be scraped
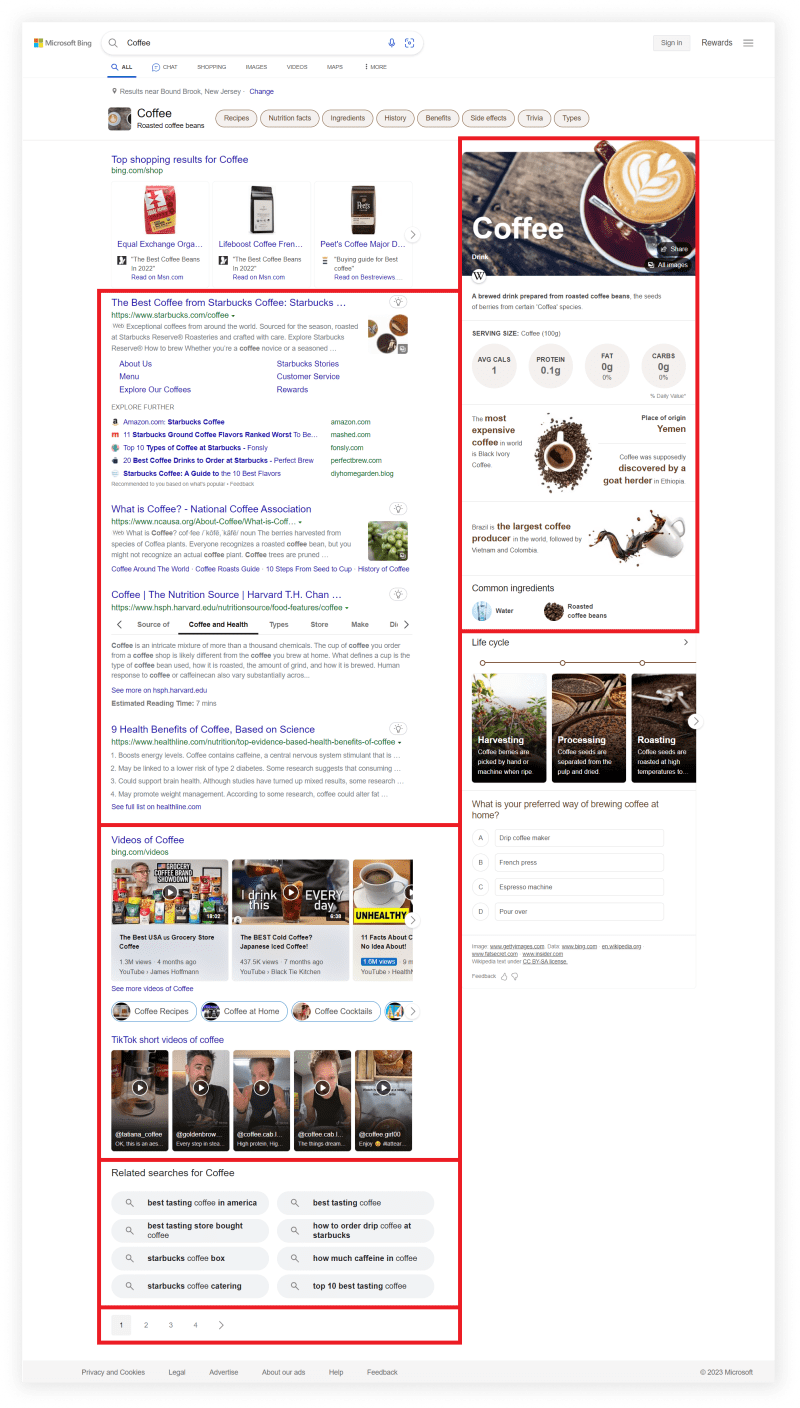
📌Note: Search results may vary depending on the parameters passed.
Why using API?
There're a couple of reasons that may use API, ours in particular:
- No need to create a parser from scratch and maintain it.
- Bypass blocks from Google: solve CAPTCHA or solve IP blocks.
- Pay for proxies, and CAPTCHA solvers.
- Figure out the legal part of scraping data.
SerpApi handles everything on the backend with fast response times under ~2.1 seconds (~1.4 seconds with Ludicrous speed) per request and without browser automation, which becomes much faster. Response times and status rates are shown under SerpApi Status page.

Full Code
This code retrieves all the data with pagination:
from serpapi import BingSearch
import json
params = {
'api_key': '...', # https://serpapi.com/manage-api-key
'q': 'Coffee', # search query
'engine': 'bing', # search engine
'cc': 'US', # country of the search
'location': 'New York,United States', # location of the search
'first': 1, # pagination
'count': 10 # number of results per page
}
search = BingSearch(params) # data extraction on the SerpApi backend
results = search.get_dict() # JSON -> Python dict
bing_results = {
'ads': [],
'organic_results': [],
'local_map': results.get('local_map', {}),
'local_results': results.get('local_results', {}),
'inline_images': results.get('inline_images', {}),
'inline_videos': results.get('inline_videos', {}),
'knowledge_graph': results.get('knowledge_graph', {}),
'answer_box': results.get('answer_box', {}),
'recipes_results': results.get('recipes_results', {}),
'related_questions': results.get('related_questions', []),
'related_searches': []
}
page_count = 0
page_limit = 10
while 'error' not in results and page_count < page_limit:
bing_results['ads'].extend(results.get('ads', []))
bing_results['organic_results'].extend(results.get('organic_results', []))
bing_results['related_searches'].extend(results.get('related_searches', []))
params['first'] += params['count']
page_count += 1
results = search.get_dict()
print(json.dumps(bing_results, indent=2, ensure_ascii=False))
Preparation
Install library:
pip install google-search-results
google-search-results is a SerpApi API package.
Code Explanation
Import libraries:
from serpapi import BingSearch
import json
| Library | Purpose |
|---|---|
BingSearch |
to scrape and parse Bing results using SerpApi web scraping library. |
json |
to convert extracted data to a JSON object. |
The parameters are defined for generating the URL. If you want to pass other parameters to the URL, you can do so using the params dictionary:
params = {
'api_key': '...', # https://serpapi.com/manage-api-key
'q': 'Coffee', # search query
'engine': 'bing', # search engine
'cc': 'US', # country of the search
'location': 'New York,United States', # location of the search
'first': 1, # pagination
'count': 10 # number of results per page
}
| Parameters | Explanation |
|---|---|
api_key |
Parameter defines the SerpApi private key to use. |
q |
Parameter defines the search query. You can use anything that you would use in a regular Bing search. (e.g., 'query', NOT, OR, site:, filetype:, near:, ip:, loc:, feed: etc.). |
engine |
Set parameter to bing to use the Bing API engine. |
cc |
Parameter defines the country to search from. It follows the 2-character ISO_3166-1 format. (e.g., us for United States, de for Germany, gb for United Kingdom, etc.). |
location |
Parameter defines from where you want the search to originate. If several locations match the location requested, we'll pick the most popular one. Head to the /locations.json API if you need more precise control. |
first |
Parameter controls the offset of the organic results. This parameter defaults to 1. (e.g., first=10 will move the 10th organic result to the first position). |
count |
Parameter controls the number of results per page. Minimum: 1, Maximum: 50. This parameter is only a suggestion and might not reflect actual results returned. |
📌Note: You can also add other API Parameters.
Then, we create a search object where the data is retrieved from the SerpApi backend. In the results dictionary we get data from JSON:
search = BingSearch(params) # data extraction on the SerpApi backend
results = search.get_dict() # JSON -> Python dict
At the moment, the results dictionary only stores data from 1 page. Before extracting data, the bing_results dictionary is created where this data will be added later. Since some of the data is only displayed on the first page, you can extract them immediately:
bing_results = {
'ads': [],
'organic_results': [],
'local_map': results.get('local_map', {}),
'local_results': results.get('local_results', {}),
'inline_images': results.get('inline_images', {}),
'inline_videos': results.get('inline_videos', {}),
'knowledge_graph': results.get('knowledge_graph', {}),
'answer_box': results.get('answer_box', {}),
'recipes_results': results.get('recipes_results', {}),
'related_questions': results.get('related_questions', []),
'related_searches': []
}
The page_limit variable defines the page limit. If you want to extract data from a different number of pages, then simply write the required number into this variable.
page_limit = 10
To get all results, you need to apply pagination. This is achieved by the following check: while there is no error in the results and the current page_count value is less than the specified page_limit value, we extract the data, increase the first parameter by the value of the count parameter to get the results from next page and update the results object with the new page data:
page_count = 0
while 'error' not in results and page_count < page_limit:
# data extraction from current page will be here
params['first'] += params['count']
page_count += 1
results = search.get_dict()
Lists by corresponding keys are extended with new data from each page:
bing_results['ads'].extend(results.get('ads', []))
bing_results['organic_results'].extend(results.get('organic_results', []))
bing_results['related_searches'].extend(results.get('related_searches', []))
# price= results['ads'][0]['price']
# title = results['organic_results'][0]['title']
# link = results['organic_results'][0]['link']
# snippet = results['organic_results'][0]['snippet']
# query = results['related_searches'][0]['query']
📌Note: In the comments above, I showed how to extract specific fields. You may have noticed the results['organic_results'][0]. This is the index of a organic result, which means that we are extracting data from the first organic result. The results['organic_results'][1] is from the second organic result and so on.
After the all data is retrieved, it is output in JSON format:
print(json.dumps(bing_results, indent=2, ensure_ascii=False))
Output
{
"ads": [
{
"position": 1,
"block_position": "inline-top",
"title": {
"visible": "Flavored Coffee Of",
"hidden": "The Month Club - 6 Months"
},
"price": "$124.49",
"store": "Boca Java",
"link": "https://www.bing.com/aclk?ld=e8Hfu6ijJpE-SJ-E2odZFsDTVUCUxXbdrWFM3S-7j7JLeWi1v3bGHZ1Aq1nJuIVz7RC0o_fJsYZoqFE5atgN0ii6xA7uv4-LyWrc0C835nImKbzlaakp2M2WSjk05bxpnSTJV6iYyYtnq9k0tlEkln_uSMu7wmP_YZy8Q8HPwa6Z9yIZNbR5YIQshvvzEykwkqwXTdew&u=aHR0cHMlM2ElMmYlMmZ3d3cuYm9jYWphdmEuY29tJTJmcHJvZHVjdCUyZjk5NTQlM2Ztc2Nsa2lkJTNkZTRmYmE4MzAxNGQ1MWMxNjVmYjJjYzJiZTY1OWIzOTQlMjZ1dG1fc291cmNlJTNkYmluZyUyNnV0bV9tZWRpdW0lM2RjcGMlMjZ1dG1fY2FtcGFpZ24lM2RTaG9wcGluZyUyNTIwLSUyNTIwTmV3JTI2dXRtX3Rlcm0lM2Q0NTg1NTEzMjQzOTA4ODEyJTI2dXRtX2NvbnRlbnQlM2RUb3Vycw&rlid=e4fba83014d51c165fb2cc2be659b394",
"thumbnail": "https://www.bing.com/th?id=OP.D7DcGzD8CA5qcQ474C474&w=94&h=94&c=17&o=5&pid=21.1"
},
... other ads results
],
"organic_results": [
{
"position": 1,
"title": "27 Outstanding Coffee Shops Open Right Now in NYC",
"link": "https://ny.eater.com/maps/best-cafe-coffee-shop-new-york-city-brooklyn-queens",
"displayed_link": "https://ny.eater.com/maps/best-cafe-coffee-shop...",
"rich_snippet": {
"extensions": [
"Estimated Reading Time: 6 mins"
]
},
"thumbnail": "https://serpapi.com/searches/641bf28a37014c25c6bae18a/images/00dad7eafb7da3761aec6080896f69f20ece50ab3511be0312fb414fc343556c.gif",
"snippet": "Variety first started roasting coffee in 2014, and is known for its nutty, chocolatey roasts. Open in Google Maps. 1269 Lexington Ave, …",
"cached_page_link": "https://cc.bingj.com/cache.aspx?q=Coffee&d=4691689351434387&w=zDQ1K8HqZ2VViOImKdoLD7jCQPkb1BtF"
},
... other organic results
],
"local_map": {
"link": "https://www.bing.com/maps/geoplat/REST/v1/Imagery/Map/RoadVibrant/40.687304,-73.976673/15?ms=646,200&pp=40.689369,-73.980797;S518;Starbucks&pp=40.689491,-73.972549;S518;Bittersweet&pp=40.685116,-73.976021;S518;Starbucks&ppsc=dpss,cfp&ml=Basemap,Landmarks,OsmBuildings&key=AnTcaqBi2ypp0xI-OZNi4W_ik2KhjgpqioTAtXLC8GzkMBQRMlyxvxyTnd5b73im&c=en-US&fmt=jpeg&od=1&logo=n&da=ro",
"image": "https://www.bing.com/maps/geoplat/REST/v1/Imagery/Map/RoadVibrant/40.687304,-73.976673/15?ms=646,200&pp=40.689369,-73.980797;S518;Starbucks&pp=40.689491,-73.972549;S518;Bittersweet&pp=40.685116,-73.976021;S518;Starbucks&ppsc=dpss,cfp&ml=Basemap,Landmarks,OsmBuildings&key=AnTcaqBi2ypp0xI-OZNi4W_ik2KhjgpqioTAtXLC8GzkMBQRMlyxvxyTnd5b73im&c=en-US&fmt=jpeg&od=1&logo=n&da=ro",
"gps_coordinates": {
"latitude": "40.689491271972656",
"longitude": "-73.98079681396484"
}
},
"local_results": {
"places": [
{
"position": 1,
"place_id": "YN873x133137763",
"title": "Starbucks",
"rating": 4.0,
"reviews": 60,
"hours": "Closed · Opens 5:30 AM",
"address": "395 Flatbush Avenue Ext, Brooklyn",
"mention": "Delivery • Takeout",
"links": {
"directions": "https://www.bing.com/maps/directions?rtp=adr.~pos.40.689369201660156_-73.98079681396484_395+Flatbush+Avenue+Ext%2c+Brooklyn%2c+NY+11201_Starbucks_(718)+858-8070",
"website": "https://www.bing.com/alink/link?url=https%3a%2f%2fwww.starbucks.com%2fstore-locator%2fstore%2f1005807%2f&source=serp-local&h=F2sOrXCeAlgbx8McGSutCp9gvyBDYDU6w4WmuoOg9YM%3d&p=localwebsitelistingentitycard&ig=DC3B1BE012E2422F8DEA1C8F86AAB99B&ypid=YN873x133137763"
},
"gps_coordinates": {
"latitude": "40.68937",
"longitude": "-73.9808"
}
},
... other local places
]
},
"inline_images": {},
"inline_videos": {
"title": "Videos of Coffee",
"displayed_link": "bing.com/videos",
"see_more_link": "https://www.bing.com/videos/search?q=Coffee&FORM=VDRESM",
"items": [
{
"position": 1,
"link": "https://www.bing.com/videos/search?q=coffee&docid=608034461997991710&mid=0A195DA22867D85A814A0A195DA22867D85A814A&view=detail&FORM=VIRE",
"thumbnail": "https://www.bing.com/th?id=OVP.r2hQaGFwkWYBsPgw_CbqWwEsDh&w=236&h=132&c=7&rs=1&qlt=90&o=6&pid=1.7",
"duration": "7:52",
"title": "How to Make the 3 Most Popular Milk Coffees #barista #coffee",
"views": "239.9K views",
"date": "6 months ago",
"platform": "YouTube",
"channel": "Artisti Coffee Roasters."
},
... other inline videos
]
},
"knowledge_graph": {
"title": "Coffee",
"type": "Drink",
"description": "A brewed drink prepared from roasted coffee beans, the seeds of berries from certain 'Coffea' species.",
"thumbnails": [
{
"image": "https://www.bing.com/th?id=ALSTU1C05162DF22F2C2E8EF4206C8DBBEA9FA785433DDD73D0BBEB59978C47020D96&w=296&h=176&rs=2&o=6&oif=webp&pid=SANGAM",
"source": "https://www.bing.com/images/search?q=coffee&cbn=KnowledgeCard&stid=e7f69601-fd37-6560-319a-6bd7037a3cf1&FORM=KCHIMM"
}
],
"nutrition_facts": {
"serving_size": "Coffee (100g)",
"serving_facts": [
{
"avg_cals": {
"ratio": "1"
}
},
{
"protein": {
"ratio": "0.1g"
}
},
{
"fat": {
"ratio": "0g",
"percentage": "0%"
}
},
{
"carbs": {
"ratio": "0g",
"percentage": "0%"
}
}
]
},
"facts": [
{
"title": "The most expensive coffee in world is Black Ivory Coffee.",
"link": "https://en.wikipedia.org/wiki/Black_Ivory_Coffee"
},
{
"title": "Place of origin Yemen",
"link": "http://en.wikipedia.org/wiki/Coffee"
},
{
"title": "Coffee was supposedly discovered by a goat herder in Ethiopia.",
"link": "https://www.insider.com/coffee-facts-you-didnt-know-2018-12#coffee-was-supposedly-discovered-by-a-goat-herder-in-ethiopia-1"
},
{
"title": "Brazil is the largest coffee producer in the world, followed by Vietnam and Colombia.",
"link": "https://www.insider.com/coffee-facts-you-didnt-know-2018-12#brazil-is-the-largest-coffee-producer-in-the-world-followed-by-vietnam-and-colombia-5",
"thumbnail": "https://www.bing.com/th?id=ALSTU18E12B038F083FF3EBF5C20DDBC4667D3C2D9C0C33ED0C72F89309B8AA54A77A&w=124&h=73&o=6&oif=webp&pid=SANGAM"
}
],
"profiles": [
{
"title": "Wikipedia",
"link": "https://en.wikipedia.org/wiki/Coffee"
}
],
"common_ingredients": [
{
"title": "Water",
"link": "https://www.bing.com/search?q=Water",
"thumbnail": "https://www.bing.com/th?id=ALSTU17F805D3AED894E8E9AE96144DD06EBD1C6AC45E9451BB5A0C6C7B14AF960BE2&w=40&h=40&o=6&pid=SANGAM"
},
{
"title": "Roasted coffee beans",
"link": "https://www.bing.com/search?q=Roasted+coffee+beans",
"thumbnail": "https://www.bing.com/th?id=ALSTUB0B37AFC3D8E307EACBFE8F6487BF02B27069B6E49309A8117A98653F56D0CA9&w=40&h=40&o=6&pid=SANGAM"
}
],
"life_cycle": [
{
"link": "https://www.bing.com/search?FORM=SNAPST&q=coffee+harvesting+methods&filters=fcid:\"0-9fc66bf7-b836-d612-71d6-44c649d20f6f\"+itemid:\"0\"",
"thumbnail": "https://www.bing.com/th?id=OSK.TMLNVBRWzFmoZAQSp2N0WZzCNqvBKsl8VOaADH9cw3cfd4k&w=150&h=220&c=7&o=6&pid=SANGAM"
},
{
"link": "https://www.bing.com/search?FORM=SNAPST&q=coffee+processing+methods&filters=fcid:\"0-9fc66bf7-b836-d612-71d6-44c649d20f6f\"+itemid:\"1\"",
"thumbnail": "https://www.bing.com/th?id=OSK.TMLNaqLBMSDvjyLkQy5TBEc7r3otnt1Qe6KSft9h7e56yTw&w=150&h=220&c=7&o=6&pid=SANGAM"
},
{
"link": "https://www.bing.com/search?FORM=SNAPST&q=coffee+roasting+process&filters=fcid:\"0-9fc66bf7-b836-d612-71d6-44c649d20f6f\"+itemid:\"2\"",
"thumbnail": "https://www.bing.com/th?id=OSK.TMLNhtdA7jtVcEjyF_T3ekW4hShQWZVSbdVUV1NyHF5QLT4&w=150&h=220&c=7&o=6&pid=SANGAM"
},
{
"link": "https://www.bing.com/search?FORM=SNAPST&q=coffee+grinding+levels&filters=fcid:\"0-9fc66bf7-b836-d612-71d6-44c649d20f6f\"+itemid:\"3\"",
"thumbnail": "https://www.bing.com/th?id=OSK.TMLNW_2cWIzfYJ9gLZlvpYxWx37CKCsPJh5HXdpEnSVGQTE&w=150&h=220&c=7&o=6&pid=SANGAM"
}
]
},
"answer_box": {},
"recipes_results": {},
"related_questions": [],
"related_searches": [
{
"query": "best tasting coffee in america",
"link": "https://www.bing.com/search?q=best+tasting+coffee+in+america&FORM=QSRE1"
},
{
"query": "best tasting coffee",
"link": "https://www.bing.com/search?q=best+tasting+coffee&FORM=QSRE2"
},
{
"query": "best tasting store bought coffee",
"link": "https://www.bing.com/search?q=best+tasting+store+bought+coffee&FORM=QSRE3"
},
{
"query": "how to order drip coffee at starbucks",
"link": "https://www.bing.com/search?q=how+to+order+drip+coffee+at+starbucks&FORM=QSRE4"
},
{
"query": "starbucks coffee box",
"link": "https://www.bing.com/search?q=starbucks+coffee+box&FORM=QSRE5"
},
{
"query": "how much caffeine in coffee",
"link": "https://www.bing.com/search?q=how+much+caffeine+in+coffee&FORM=QSRE6"
},
{
"query": "starbucks coffee catering",
"link": "https://www.bing.com/search?q=starbucks+coffee+catering&FORM=QSRE7"
},
{
"query": "top 10 best tasting coffee",
"link": "https://www.bing.com/search?q=top+10+best+tasting+coffee&FORM=QSRE8"
}
]
}
📌Note: Head to the playground for a live and interactive demo.
Add a Feature Request💫 or a Bug🐞

Top comments (0)