
My newest interest is Redis, an in-memory data store for key-value pairs, streaming, message brokering and a database.
In this post I’ll give you an introduction into using Redis as a normal database. The code snippets will use C# and the final result will look very familiar to anyone who used Entity Framework.
What you’re not getting is a spoon-feeding, instead you’re going to see the relevant parts of Visualizer, a pet project of mine, where I’m using Redis to ingest and query tweets from Twitter’s sample steam.
Tools
Setting up all the tools is beyond the scope of this post, but I still want to mention the most essential things.
Redis Stack: a suite of multiple components, that includes a Redis instance, multiple Redis modules and RedisInsight. Two modules, RediSearch and RedisJSON are essential here, as they allow us to use Redis as a proper DB. The simplest way to get going is to use the official Docker container.
Redis OM .NET: an official .NET library that offers (CLR) object mapping and query translation. I can recommend it wholeheartedly, even though it isn’t perfect. The excellent community and maintainers go above and beyond the call of duty. Ask them anything on the official Discord server.
A good .NET IDE: like VS Code, Visual Studio Proper or Rider.
And finally, a few spare minutes.
Data Modeling
In Visualizer, I’m receiving a stream of tweets, including their many properties and nested data, which represent 1% of the “real-time” tweets.
The fields are described in the official Twitter API documentation, look for Response Fields.
To store and retrieve the data, I’m using Redis OM, which wants a normal C# class whose properties are annotated.
The data model for a single tweet looks like this
You can find the full file here.
Notice that the class is annotated as a Document *with *StorageType JSON. This lets Redis OM know that we want to store instances of this class in a searchable way and in JSON format. The Prefixes is just for our convenience, to make it easier to distinguish the data in Redis, in case that we have multiple document types.
Each property is also annotated, to instruct Redis OM (and indirectly RediSearch and RedisJSON) which fields should be searchable and how exactly.
The attribute RedisIdField is manadatory and you can interpret it as the primary key of a tweet.
Indexed does exactly what you’d expect.
Searchable is powerful, because it allows full text search in the string property.
CascadeDepth tells Redis OM how deep it should look for annotated properties. My TweetModel class has an array of ReferencedTweet instance. The ReferencedTweet class is not marked as a Document because it is nested inside the TweetModel. It will however contain its own annotated properties. That’s why I set the depth to 1.
All attributes are described here.
Create the Index
After the data is modelled, a so-called index needs to be created in Redis.
First, create a RedisConnectionProvider. In my Visualizer project I’m adding one to the DI container with an extension method
Then, let Redis OM send the command that instructs RediSearch/RedisJSON which field is searchable and how. I’m doing it when one of my microservices starts up.
In Redis, the index will have the name tweetmodel-idx. You can list them all by issuing FT._LIST in the Redis CLI or get a detailed explanation of an index with FT.INFO tweetmodel-idx.
Data Storing
After you have a few tweets (I’m using a library called Tweetinvi) you want to store them.
Redis OM makes this easy by offering us a RedisCollection, where T is our data model, e.g. TweetModel. If it helps, this is analogous to a DbSet in Entity Framework,
To get a hold of such a collection, you make use of the RedisConnectionProvider that you registered previously
On it you call InsertAsync() *and provide your *TweetModel instance
That’s it, your tweet is now stored in Redis. You can now have a look at your data with RedisInsight. This is how it looks for me
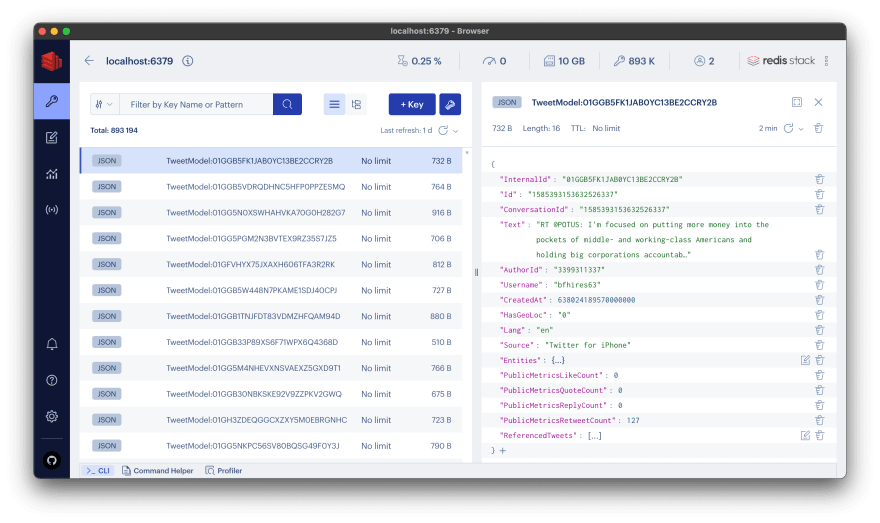
Filter, Sort and Paginate Tweets
I usually work with relational DBs (mostly Postgres), where filtering, sorting and paginating results is as common as it gets.
In Redis, especially using Redis OM, this is as easy as we’re used to as Entity Framework users.
First, we need a DTO that defines all the necessary filtering, sorting and pagination fields.
Visualizer offers a GraphQL API, hence the “Input” in the DTOs name.
Next, we have to formulate a query based on the DTO and retrieve the tweets that match that query.
First, get a new RedisCollection instance like you saw in the previous section
Then you can start filtering, e.g. by a tweet’s ID
Remember that TweetModel.Text was annotated as Searchable, which allows for full text searches. To filter only tweets that contain a certain word in their text you’d write something like this
Note that there’s no call to Contains() or anything like that, just a simple ==.
The TweetModel.CreatedAt property is Indexed and Searchable
Tweets can be filtered by date like so
A cool feature of Redis is its native support for the geolocation data type. Tweets can include geolocation information and to filter the tweets that are at a certain distance from a location you’d write something like this
Sorting and pagination are nothing special
Finally, you’d want to materialize the query and get your tweets
Visualizer has a simple React frontend that allows to query for tweets
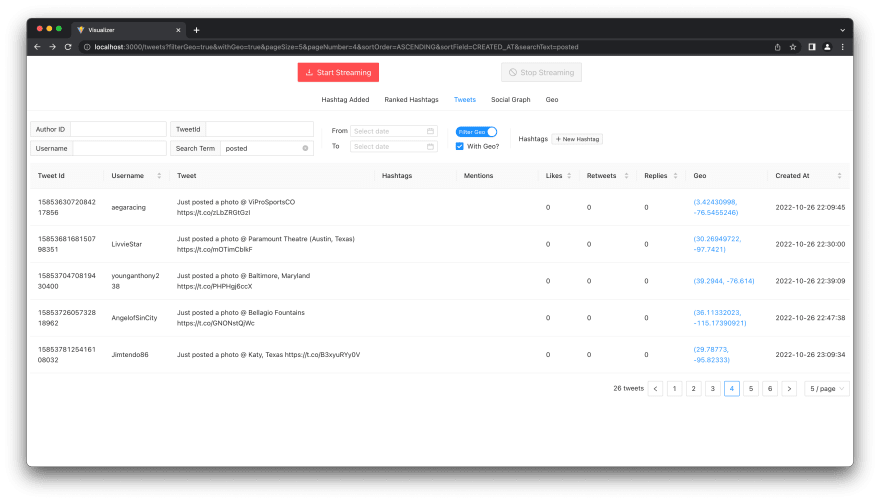
And even to filter them by location
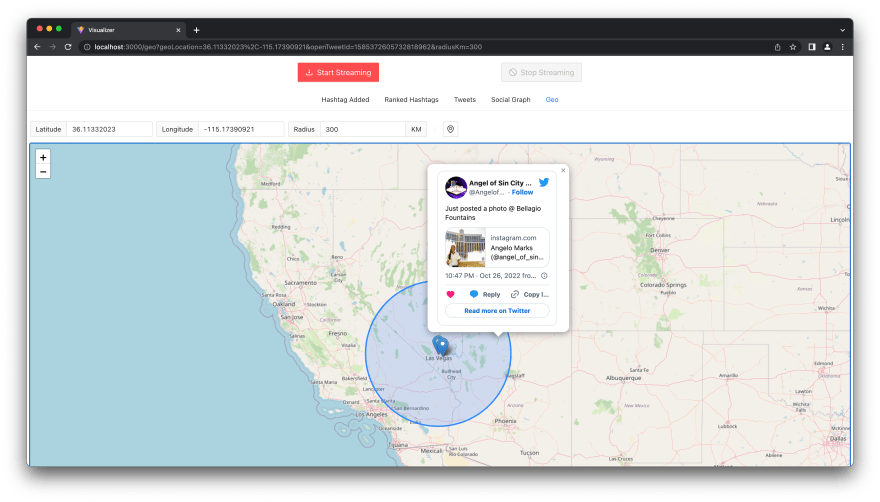
There's More to Come
I’m planning to write a few more posts about Visualizer, where I show Redis’ PubSub, quick ranking with SortedSets and GraphQL subscriptions.
If you liked this post let me know on Twitter 😉 (@MunteanMarius), give it a ❤️ and follow me to get more content on Redis, Azure, MAUI and other cool stuff.
Other content on this topic
Hussein Nasser — Can Redis be used as a Primary database?
Redis — Redis as a Primary Database
DevTalk 83: The hidden features of Redis. With Marius Muntean

Top comments (0)