This is the third post in a series about property-based testing. This post completes the design and implementation of the original property-based testing library, QuickCheck. The first and introductory post is What is it anyway?, followed by The Essentials of Vintage QuickCheck.
The complete code for this post can be found on GitHub - in particular example.py and vintage_shrink.py.
In the first two posts we created a reference implementation that allows users to generate random values, specify properties using for_all, and run tests. An excellent start, but modern PBT libraries have one more very nifty (and helpful) feature called shrinking. Shrinking starts after we have generated an input for which a property fails, and aims to make the failing test input easier to understand by removing parts that have no effect on whether the property fails.
Legend has it that if you keep walking down this gallery, you eventually shrink to the quantum realm. Photo by Elizabeth Villalta on Unsplash

Let's take a sneak peek ahead at what we'll implement in this post.
As a reminder, we were testing a function sort_by_age which takes as input a list of Person objects and is simply supposed to sort them by their age field. Now let's see what happens when we inject a bug in the implementation:
def wrong_sort_by_age(people: list[Person]) -> list[Person]:
# whoops, forgot the sort key
return sorted(people)
prop_wrong_sort_by_age = for_all(
lists_of_person,
lambda persons_in: is_valid(persons_in, wrong_sort_by_age(persons_in))
)
This bug means the result is sorted by name first, then by age. Our implementation dutifully finds a list for which this property fails:
> test(prop_wrong_sort_by_age)
Fail: at test 0 with arguments ([Person(name='bwnbaz', age=21), Person(name='jdmzns', age=98), Person(name='nhyvan', age=90), Person(name='gmtwqx', age=68), Person(name='odapqz', age=49)],).
That's a good start, but it doesn't really give us any idea of where the problem is. We could try and see what wrong_sort_by_age's output is on the randomly generated input:
> wrong_sort_by_age([Person(name='bwnbaz', age=21), Person(name='jdmzns', age=98), Person(name='nhyvan', age=90), Person(name='gmtwqx', age=68), Person(name='odapqz', age=49)])
[Person(name='bwnbaz', age=21),
Person(name='gmtwqx', age=68),
Person(name='jdmzns', age=98),
Person(name='nhyvan', age=90),
Person(name='odapqz', age=49)]
Still it's not clear what the problem is - besides that the result is not sorted by age. We could debug with this input value, but it's quite unwieldy, even for this toy example. Imagine Person is a more realistic class with more than a handful of fields, some of which may be other classes with their own fields as well.
This is where shrinking comes in. Shrinking starts when we find a failing random test input. To make the test input smaller, we repeatedly re-run the test with "smaller" input values, and check if the test still fails. Here's what that process looks like after we're through with this post:
> test(prop_wrong_sort_by_age)
Fail: at test 0 with arguments ([Person(name='bwnbaz', age=21), Person(name='jdmzns', age=98), Person(name='nhyvan', age=90), Person(name='gmtwqx', age=68), Person(name='odapqz', age=49)],).
Shrinking: found smaller arguments ([Person(name='nhyvan', age=90), Person(name='gmtwqx', age=68), Person(name='odapqz', age=49)],)
Shrinking: found smaller arguments ([Person(name='gmtwqx', age=68), Person(name='odapqz', age=49)],)
Shrinking: found smaller arguments ([Person(name='gmtwqx', age=51), Person(name='odapqz', age=49)],)
Shrinking: found smaller arguments ([Person(name='gmtwqx', age=50), Person(name='odapqz', age=49)],)
Shrinking: found smaller arguments ([Person(name='', age=50), Person(name='odapqz', age=49)],)
Shrinking: found smaller arguments ([Person(name='', age=50), Person(name='odapqz', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=25), Person(name='odapqz', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=13), Person(name='odapqz', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=7), Person(name='odapqz', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=4), Person(name='odapqz', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=2), Person(name='odapqz', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=1), Person(name='odapqz', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=1), Person(name='oda', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=1), Person(name='o', age=0)],)
Shrinking: found smaller arguments ([Person(name='', age=1), Person(name='a', age=0)],)
Shrinking: gave up - smallest arguments found ([Person(name='', age=1), Person(name='a', age=0)],)
Usually, real PBT libraries will present the original randomly generated argument, and the final smallest value, but I've printed all the intermediate "shrinks" here for reference. The approach for shrinking we'll implement in this post is methodical: first the number of elements in the list is reduced to two, then the remaining Person values are individually shrunk by making their fields smaller.
The end result is a perfect shrink - there's no way to make the value smaller while still failing the test! Indeed, the number of elements must be at least two, the names must be minimally different, and the ages must be minimally different as well. Shrinking won't always work this well, but nonetheless is surprisingly effective in practice.
There are quite a few different approaches to shrinking in various PBT libraries, each with their own trade-offs. Here we'll look at the original proposal first implemented in QuickCheck, and we'll cover others in following posts.
Not the kind of shrink you pour your heart out to
QuickCheck's approach is relatively easy to explain, but can be tricky to understand.
The strategy is, in a nutshell, iterative improvement. Since we have randomly found an input for which the test fails, we can re-run the test with candidate input values that are in some way smaller than the failing input value. If the test still fails with the smaller value, we have succeeded in shrinking the input, and can try to shrink that smaller input further. Lather, rinse, repeat until we can't come up with candidate smaller values.
We'll assume we'll have an oracle available that for any given value comes up with candidate smaller values. For lists of Persons that function looks like this:
def shrink_list_of_person(value: list[Person]) -> Iterable[list[Person]]:
...
The argument value is the value we're trying to shrink - so all returned candidates must be smaller than value. We'll assume we have such a function available for everything that we can generate randomly - in other words this function needs to be user-provided, like generators. We'll look at the effect this decision has on the API later.
What "smaller" means in this context is in the eye of the beholder - for lists "smaller" normally means lists shorter than the original list. For letters it might mean lexicographically earlier. For integers it might mean closer to 0. We'll look at some examples soon.
In more detail, shrinking works as follows.
We start out with a randomly generated failing input.
Get shrink candidates for the failing input by running
shrink.Run the test on the candidate.
If there are no more candidates, give up and report the smallest failing input.
We can visualise this as a search process on a candidate tree - an n-ary tree defined as follows:
@dataclass(frozen=True)
class CandidateTree(Generic[T]):
value: T
candidates: Iterable[CandidateTree[T]]
The root of the tree has as value the randomly generated failing input, and the result of an appropriate shrink call on that value as children in candidates.
For example, let's assume our value is a simple int and we have a shrink function for it:
def shrink_int(value: int) -> Iterable[int]:
if value != 0:
yield 0
current = abs(value) // 2
while current != 0:
yield abs(value) - current
current = current // 2
> list(shrink_int(15))
[0, 8, 12, 14]
The idea is to try to shrink to 0 first, as that is the smallest possible integer, and then try one half, three quarters etc of the input value. Here's the candidate tree for shrink_int with an initial failing value of 6:
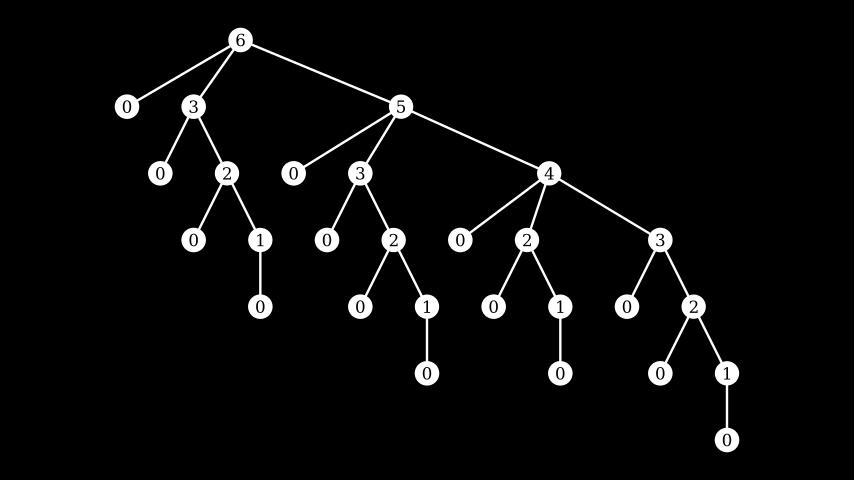
At the top we see the initial value, 6. On the next level down are all the candidates generated by shrink_int(6), and this continues recursively - each node's children are the candidate smaller values for that node's value.
Here's how the search process detailed above would work for a test which fails if value > 3:

What happens when a powerful tool like Manin Community is put in the hands of a graphically challenged person
I'll call a shrink candidate "successful" if it still makes the test fail. As the animation indicates, as long as shrinking a candidate is not successful (indicated by a red cross) we simply move on to the next candidate. If shrinking a candidate is successful, we move one level deeper in the tree. If at some point all the candidates are unsuccessful, the process ends.
In this case we find the smallest value 4 that still fails the test. It's possible to come up with a test that doesn't shrink that perfectly - depending on the implementation of the shrink candidate generating function. Before we discuss that, let's complete the picture above by writing a function that turns a function like shrink_int into a CandidateTree.
First let's make the general shape of functions like shrink_int explicit:
class Shrink(Protocol[T]):
def __call__ (self, value: T) -> Iterable[T]:
...
In case you're not familiar with Mypy's protocols the details are not that important - Shrink[T] means: a function that takes a value of type T and generates an Iterable of smaller candidate values T. The shrink_int function satisfies this protocol and is a Shrink[int]. The Shrink class is just here for Mypy's benefit, and as documentation for readers - it has no effect at runtime. If that didn't make sense, feel free to ignore it, like all the other types. I find them useful for understanding and documentation so I will keep adding them.
Creating a CandidateTree from a shrink function is relatively straightforward:
def tree_from_shrink(value: T, shrink: Shrink[T]) -> CandidateTree[T]:
return CandidateTree(
value = value,
candidates = (
tree_from_shrink(v, shrink)
for v in shrink(value)
)
)
We create the CandidateTree recursively by calling tree_from_shrink lazily in a generator expression - we only create children of a node as we iterate through candidates. Creating the entire tree when we're only exploring a small part of it would be a waste, especially since for more complex shrink functions the tree can become big.
That's the basics of shrinking under your belt! Now relax for a bit with a calming camomile tea with honey.
Photo by Catia Climovich on Unsplash

Putting it all together
We'll come back to writing more interesting shrink functions for lists of Person objects, but first let's try to put everything we have so far together.
Remember how last time we started out with a generator Random[T] and turned that into a simple property, by mapping it to a Random[bool] which generates True if the test passes. Then we mapped bool to TestResult:
@dataclass(frozen=True)
class TestResult:
is_success: bool
arguments: Tuple[Any,...]
So that we could capture the generated arguments as well. We ended up with Property = Random[TestResult] and running tests was simply calling generate 100 times and checking is_success on the resulting TestResult objects. This way we were able to piggy-back on the Random class - which is quite useful because we could keep using our map, mapN and bind functions for implementing the test runner itself.
We'll play this trick again by re-defining a property as a random generator of candidate trees of test results:
Property = Random[CandidateTree[TestResult]]
This looks like a nicely layered type, but what does it mean in practice? Let's see by implementing a new for_all. for_all will have to change because it needs to produce this new Property type. To do so, it now needs an appropriate shrink function as an additional user-provided argument:
def for_all(
gen: Random[T],
shrink: Shrink[T],
property: Callable[[T], bool]
) -> Property:
...
I've simplified property again to just return a bool, which means we won't be able to nest for_all. We'll lift that restriction in a later post.
Our task is now to take a Random[T] and somehow turn it into a Random[CandidateTree[TestResult]]. We should be able to do something by using map - if we can implement a function that takes a T to a CandidateTree[TestResult], we'll have what we need:
def for_all(
gen: Random[T],
shrink: Shrink[T],
property: Callable[[T], bool]
) -> Property:
def property_wrapper(value: T) -> CandidateTree[TestResult]:
...
return map(property_wrapper, gen)
It turns out we already have most of what we need to implement property_wrapper:
def for_all(
gen: Random[T],
shrink: Shrink[T],
property: Callable[[T], bool]
) -> Property:
def property_wrapper(value: T) -> CandidateTree[TestResult]:
tree_value = tree_from_shrink(value, shrink)
tree_test_result = tree_map(
lambda v: TestResult(is_success=property(v), arguments=(v,)),
tree_value
)
return tree_test_result
return map(property_wrapper, gen)
We use tree_from_shrink on the value to create a CandidateTree[T]. We're almost there now because we know from before how to turn a T in a TestResult, by invoking property on value and capturing the arguments. We just need to do that on every element of CandidateTree - which means we also need a map-like function on CandidateTree, just like we created one for Random in the previous post:
def tree_map(f: Callable[[T], U], tree: CandidateTree[T]) -> CandidateTree[U]:
value_u = f(tree.value)
branches_u = (
tree_map(f, branch)
for branch in tree.candidates
)
return CandidateTree(
value = value_u,
candidates = branches_u
)
Applying a function f to each value in a tree is easily expressed recursively - apply f to the value in the current node, and then recurse to all of the node's children.
With all that, we can finally write a new test function:
def test(property: Property):
def do_shrink(tree: CandidateTree[TestResult]) -> None:
for smaller in tree.candidates:
if not smaller.value.is_success:
# cool, found a smaller value that still fails - keep shrinking
print(f"Shrinking: found smaller arguments {smaller.value.arguments}")
do_shrink(smaller)
return
print(f"Shrinking: gave up - smallest arguments found {tree.value.arguments}")
for test_number in range(100):
result = property.generate()
if not result.value.is_success:
print(f"Fail: at test {test_number} with arguments {result.value.arguments}.")
do_shrink(result)
return
print("Success: 100 tests passed.")
The new part is the inner function do_shrink which is called if a randomly generated test case fails. do_shrink executes the search discussed above - it keeps trying candidates until it finds a smaller input. If so, it recursively continues shrinking the smaller value.
We can now run a simple example that corresponds to the shrinking animation above:
wrong_shrink_1 = for_all(
int_between(0, 20),
shrink_int,
lambda l: l <= 3
)
> test(wrong_shrink_1)
Fail: at test 0 with arguments (10,).
Shrinking: found smaller arguments (5,)
Shrinking: found smaller arguments (4,)
Shrinking: gave up - smallest arguments found (4,)
Quick recap of where we are.
Our test library so far is nicely described by the type Random[CandidateTree[TestResult]]. We can read this type outside-in as a pipeline of sorts. The pipeline starts with a random value generator Random[T] which produces a T value every time we call generate(). Next in the pipeline we take that T value and turn it into a tree of T values, with the original T at the root. We now have a Random[CandidateTree[T]]. In the last step in the pipeline each T in the tree is turned into a TestResult.
That seems like a lot of objects to create, but since nodes in the tree are created only as we search it, in practice this works out OK. Undeniably shrinking does add some overhead though.
Some more shrink functions
Let's now look at a few shrinking functions, to get a feel of how to write them.
The first one is shrink_letter. It just generates up to three candidates a,b or c, if the input value is not already one of those:
def shrink_letter(value: str) -> Iterable[str]:
for candidate in ('a', 'b', 'c'):
if candidate < value:
yield candidate
This illustrates that even for simple values, we have to take care that the generated candidates are strictly smaller than the root value - if not the shrinking process will get stuck in an infinite loop.
When shrinking containers like lists and dictionaries it's good to not only shrink the container itself by removing elements, but also call a shrink function for the individual elements. For example, a shrink function for lists:
def shrink_list(value: list[T], shrink_element: Shrink[T]) -> Iterable[list[T]]:
length = len(value)
if length > 0:
yield []
half_length = length // 2
while half_length != 0:
yield value[:half_length]
yield value[half_length:]
half_length = half_length // 2
for i,elem in enumerate(value):
for smaller_elem in shrink_element(elem):
smaller_list = list(value)
smaller_list[i] = smaller_elem
yield smaller_list
Somewhat similar to shrinking integers, we first try the empty list. Then we do a bisect of sorts - trying each half of the list. If none of those yield a successful shrink, we shrink each element of the list successively using shrink_element. So, in a way, we can compose shrink functions with others to generate more candidates for the search to try. If we wouldn't shrink the elements, we'd only be able to reduce the length of the list.
Now we have all the ingredients to write shrink functions for lists of Person objects:
def shrink_name(name: str) -> Iterable[str]:
name_as_list = list(name)
for smaller_list in shrink_list(name_as_list, shrink_letter):
yield "".join(smaller_list)
def shrink_person(value: Person) -> Iterable[Person]:
for smaller_age in shrink_int(value.age):
yield Person(value.name, smaller_age)
for smaller_name in shrink_name(value.name):
yield Person(smaller_name, value.age)
def shrink_list_of_person(value: list[Person]) -> Iterable[list[Person]]:
return shrink_list(value, shrink_person)
We shrink names by converting them to a list of letters, and using shrink_list; we shrink Person objects by first shrinking the age field, and then the name field.
Our property for sort_by_age now becomes:
prop_wrong_sort_by_age = for_all(
lists_of_person,
shrink_list_of_person,
lambda persons_in: is_valid(persons_in, wrong_sort_by_age(persons_in))
)
The only difference from before is that for_all now also needs the shrink function.
Conclusion and Onwards
Shrinking is a useful part of property-based testing libraries, expanding their practicality significantly. Without shrinking we'd still find bugs but reproducing and understanding the randomly generated examples would be unnecessarily hard.
When you first see shrinking in action it can feel magical, and indeed it works very well in practice. This is a great example of a feature that turns a weakness into a core strength.
However, you may have noticed that shrinking requires a lot of additional work on the part of the user - all those shrink functions must be implemented. If for some reason you need to write a custom Random generator, now that also needs a shrink function. Worse, these are two separate bits of code that need to be kept in sync - for example, if the random generator for age only generates positive values, then the shrink function for age should not try to shrink to negative values either.
Actual property-based testing libraries wrap up the Random generators and the Shrink functions into a single type typically called Arbitrary. This helps somewhat to define a set of convenient randomly generated and shrink-able types, but it doesn't help all that much with writing your own, because both need to be separately written.
Also, while the Random API is very nice to use thanks to map, mapN and bind, shrink functions are not so easily composed. In fact, try to write a function like def map(f: Callable[[T], U], shrink: Shrink[T]) -> Shrink[U] - you won't be able to do it! Implementing mapN and bind on Shrink is out of the question as well. These issues impact the ease of use of the API, and in practice people often don't bother with writing shrink functions until they really, really need them.
A final problem with this approach is mutable values. I've already mentioned in the previous post that mutability is problematic when capturing the arguments in TestResult, but shrinking also captures the generated value in the root of the tree - so if it's mutated in place all kinds of shenanigans ensue, and shrinking gives very unexpected and confusing results.
We won't solve the mutability problem just yet, but next post we'll look into how we can regain a nice, compositional, integrated generation and shrinking API. As it turns out, this post already contains most of the answer!
As usual, comment below or discuss on Twitter @kurt2001.
Until next time!

Top comments (0)