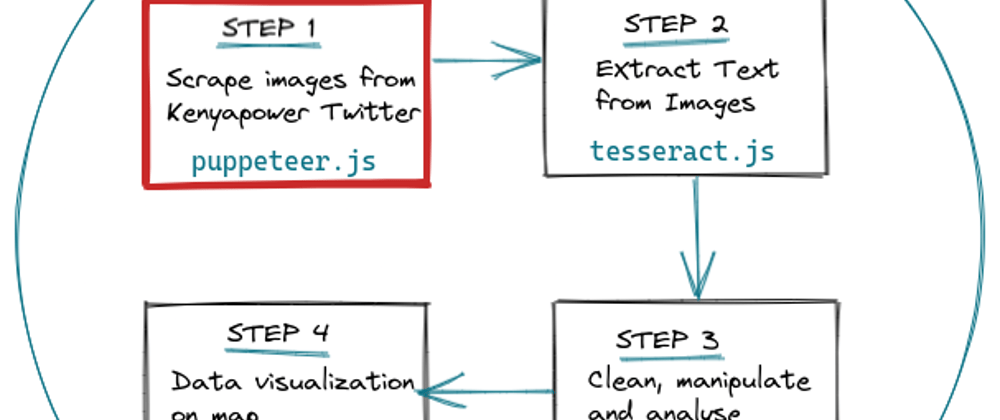

This is the first part of my Analyzing Kenya Power Interruption Data project. In this part we build a Twitter Image Downloader using Puppeteer.js.
Over the past 2 years Puppeteer has become my go to choice for web scraping and automation because it is JavaScript which is my main stack among other advantages in my opinion:
- It is easy to configure and execute
- Puppeteer is really fast, it uses headless Chrome.
- It is easy to take screenshots and PDFs of pages for UI testing
Tool
Twitter Image Downloader is the tool I built to be able to scrap images from Twitter accounts, of course for educational purposes. I know several such tools exist but I decided to expand my Puppeteer and JS skills by building one myself.
The main libraries I used to build this tool are:
- Puppeteer - Node.js library which provides a high-level API to control headless Chrome or Chromium or to interact with the DevTools protocol. I use it for web crawling and scarping in this project.
- Request - Simplified http request client
- Inquirer - An easily embeddable and beautiful command line interface for Node.js
- Chalk - Chalk is a library that provides a simple and easy to use interface for applying ANSI colors and styles to your command-line output.
Puppeteer Launch
This article is not a step by step guide to building the tool rather an unofficial documentation of my thought process while building it. The instructions for running the tool can be found in the README.md here
The code below is my puppeteer config. I set headless to false in my normal developer environment so that I can be able to see what is happening especially if the scroll is effective.
const browser = await puppeteer.launch({
headless: false,
args: ["--disable-notifications"],
});
const page = await browser.newPage();
await page.setViewport({
width: 1366,
height: 768,
});
args: ["--disable-notifications"] is used to disable any notifications which may overlay and hide elements we probably want to click or get data from.
The main file is the twitter.js
The url accessed to scrape the images is found on line 67 where username is the Twitter account username entered when running the script
const pageUrl = `https://twitter.com/${username.replace("@", "")}`;
The script opens a new tab on the Chrome based browser that Puppeteer opens and gets the url of all images :
if (response.request().resourceType() === "image") {
/**
* Filter to only collect tweet images and ignore profile pictures and banners.
*/
if (url.match("(https://pbs.twimg.com/media/(.*))")) {
/**
* Convert twitter image urls to high quality
*/
const urlcleaner = /(&name=([a-zA-Z0-9_]*$))\b/;
let cleanurl = url.replace(urlcleaner, "&name=large");
try {
const imageDetails = cleanurl.match(
"https://pbs.twimg.com/media/(.*)?format=(.*)&name=(.*)"
);
const imageName = imageDetails[1];
const imageExtension = imageDetails[2];
console.log(chalk.magenta("Downloading..."));
await downloader(cleanurl, imageName, imageExtension, username);
} catch (error) {}
}
}
The response.request().resourceType() === "image" part is responsible for only checking for images because that is what we are currently interested in.
Regex
We see a lot of regex matching and I am going to explain what is going on.
1.
url.match("(https://pbs.twimg.com/media/(.*))")
A normal Twitter user profile contains many types of images:
- Their profile picture and header
- Images posted/retweeted
- Other retweeted users' profile pictures.
Each of these images have urls and one of my main headaches when starting out was being able to filter out only images in the 2nd category.
Luckily I found out that images posted by tweeting follow the pattern https://pbs.twimg.com/media/.. and that is what we are doing with the url.match function. We ignore all other types of images and only work with posted images.
2.
const urlcleaner = /(&name=([a-zA-Z0-9_]*$))\b/;
let cleanurl = url.replace(urlcleaner, "&name=large");
Posted images all follow the same pattern except the &name= part which specifies the dimensions of the image, for example, https://pbs.twimg.com/media/FDSOZT9XMAIo6Sv?format=jpg&name=900x900 900x900 is the dimension of the image.
I needed high quality images because my use case involves extracting data from text which is why I replace the &name=... part of all image urls with &name=large to get the best quality using the urlcleaner regex to match all possibilities.
3.
const imageDetails = cleanurl.match(
"https://pbs.twimg.com/media/(.*)?format=(.*)&name=(.*)"
);
const imageName = imageDetails[1];
const imageExtension = imageDetails[2];
The 3rd part retrieves the results of matching the clean modified string and returns results an array where I can be able to access the image name and the extension.
Array ["https://pbs.twimg.com/media/FDSOZT9XMAIo6Sv?format=jpg&name=large", "FDSOZT9XMAIo6Sv?", "jpg", "large"]
This is what the typical imageDetails will look like.
Autoscroll
Twitter uses infinite Scroll where tweets in current page view are loaded and to load more tweets you have to keep scrolling. This is why I needed an autoscroll function so that our browser could automatically scroll and scroll until it could not load more tweets.
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve, reject) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
var scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 300);
});
});
}
Download Images
The function that downloads the images can be found here downloader.js
function download(uri, name, extension, twitterUsername) {
return new Promise((resolve, reject) => {
request.head(uri, function (err, res, body) {
const twitterUsernamePath = `${"./"}/images/${twitterUsername}`;
if (!fs.existsSync(twitterUsernamePath)) {
fs.mkdirSync(twitterUsernamePath);
}
const filePath = path.resolve(
twitterUsernamePath,
`${name}.${extension}`
);
request(uri).pipe(fs.createWriteStream(filePath)).on("close", resolve);
});
});
}
The function takes in a uri, name, extension and twitterUsername. These parameters are passed in from line 61 of twitter.js
A folder named after the Twitter Username is created here. The images are then written/downloaded to the folder one by one.
The images are named using the passed name and extension, remember the ones we were extracting using the Regex part 3.
Conclusion
There will be several images downloaded but for the purpose of the Analyzing Kenya Power Interruption project, we are interested in the images that look like this.

The code and instructions for running this tool can be found on https://github.com/Kimkykie/twitter-image-downloader
This is still a work in progress and I am open to corrections, ideas and enhancements.
The next part will be extracting text from our images and converting them into txt files. Thank you.





Top comments (0)