
Welcome to part two of the five-part “Well-Architected Serverless” series. This article will discuss the second most crucial pillar of the AWS Well-Architected Framework (WAF): Operational Excellence (OPS).
The WAF Operational Excellence Pillar
The OPS and the Security pillar (SEC) form the core of the AWS Well-Architected framework. The OPS pillar is a catalyst for the other five pillars because it’s mostly about automation in the development and deployment process.
The basic idea of the OPS pillar is that the fewer tasks humans have to do in a software project, the fewer errors will happen, and the faster you will be able to react and change things. For example, if you have a static code analysis inside your continuous integration (CI) pipeline, many bugs can be found automatically. This enhances security. But if you don’t have a CI pipeline, you would have to manually run the analysis, which could be forgotten or skipped.
Let’s look into the four parts that make up the OPS pillar.
Organization
The people working on a software system need to understand why they do it. Why is it that this system is created, and what is their role in the whole picture? Who are the (internal/external) stakeholders? What do they want, what are the security threats, what does the law require them to do? All these things have to be evaluated; otherwise, it’s like running around in the dark.
For small teams, this often leads to every single person in the team taking on multiple duties. Still, if the software has many parts that are all worked on by multiple teams, things need to be split up, so everyone knows their responsibility to work effectively. For this, the AWS Well-Architected Framework offers Operation Models, which explain how a system can be effectively split up between teams.
Prepare
First and foremost, keep your team prepared and their skills up-to-date. If the people working on the software aren’t used to learn new best practices and experiment with new things, they will get into a rut. And getting out of habits is very expensive for companies.
You need to take into account the technical requirements of your system when you plan it. You should plan the architecture with monitoring in mind to know what’s happening before and after it was deployed.
You should also design the system with infrastructure as code right from the start, so your developers can change everything with code, not just your actual software but also the services it runs on.
Being ready for failure is imperative too. If you can partially roll-out features and quickly roll back if something goes wrong, you are much more inclined to try new things to give an edge in the future.
Operate
To operate your system effectively, you need to measure metrics on different abstraction levels. For example, how good does the system itself perform? Can it handle enough requests? But also, how good do your teams perform? Can they deliver improvements in an efficient timeframe?
You need to define key performance indicators for your system’s important metrics and your teams to give you a feeling about what they can do.
You should also be able to react to planned or unplanned events that change your system’s conditions. Can your system handle more traffic you expect from an ad campaign? And more importantly, can it handle the increased traffic that hit you unexpectedly?
Evolve
You should define processes that allow you to evaluate and apply changes to your system. You want to improve on many levels, deliver new features, improve performance. If things go wrong, you also need a way to include changes that prevent known errors from happening again.
Stay aligned with the Operational Excellence pillar
To maintain operational excellence, it’s important to know exactly what’s going on in your application at all times and constantly improve weak points in your application. With one of our core features being built on top of the Operational Excellence principles, Dashbird helps serverless users do just that in order to stay aligned with the AWS Well-Architected Framework’s best practices.
As opposed to a traditional environment, a serverless infrastructure can encompass thousands of resources, using tens of different services, which makes monitoring and alerting much more complex and noisy.
Dashbird doesn’t just show users raw data but automatically translates all their data output into actionable Well-Architected insights – including warnings and critical errors, which users will be alerted of immediately. This way, users can debug, optimize, and Well-Architect their serverless environments before and after deployment.
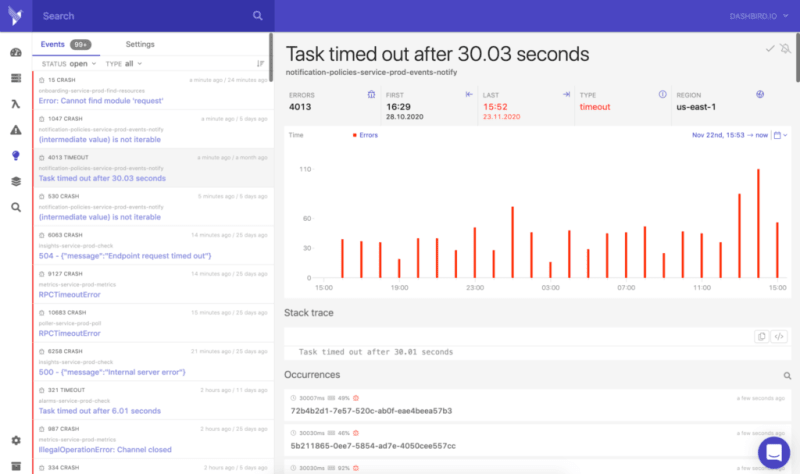
SAL Questions for the Operational Excellence Pillar
The SAL asks two questions about the operational excellence of your serverless applications. Let’s look at how these can be answered.
OPS 1: How do you understand the health of your Serverless application?
When you build serverless applications, you end up with many managed services; the serverless approach dials the microservice architecture to the max. They either integrate directly or can be glued together with Lambda functions. In a complex application, this can get messy pretty quickly. You need to implement some kind of monitoring to get insights into all these moving parts.
A centralized and structured way of logging is the way to go here. If your authentication, data storage, and API are separate services, why not monitoring? The structure your logs follow should include some kind of tracing identifier. This way, all log entries that belong to one task handled by multiple services can be correlated in the end. If your computations 10 layers down fail, you know from what API request it came.
You also have to define metrics that should be measured. AWS services come with a bunch of predefined system metrics out-of-the-box that get logged to CloudWatch. Still, you should also think about business metrics (i.e., orders placed), UX metrics (i.e., time to check out), and operational metrics (i.e., open issues). It doesn’t help that all your Lambda functions run at maximum efficiency if a user has to do 50 clicks to buy a pair of socks. If you don’t define crucial metrics, how do you know when to alert someone in your team that things are going wrong?
OPS 1: Dashbird’s answer
Observability and AWS Well-Architected insights!
Understanding how your application is running, gathering insights, and discovering opportunities for performance and cost optimization are keys.
Dashbird lets you drill into your data on:
- Accounts and Microservices Level, which gives you an instant understanding of trends for overall application health, the most concerning areas as well as cost and activity metrics.
- Resource Level, which lets you dig deeper into a specific resource and shows you anomalies, and past and present errors in order to improve and better align with best practices.
- Execution Level, which allows users to source full activity details like duration, memory usage, and start and end times for issues and optimization. Going deeper though, we can look at the profile of the execution; requests to other resources, how long it took, and its level of success. We can also detect retries and cold starts here.
For true operational excellence, monitoring needs to be paired with a good serverless alerting strategy. Failures and errors are inevitable and so reducing the time to discover and fix is imperative. Monitoring needs to be constant with preemptive checks continuously running for security, best practice, cost, and performance.
However, we also need to be able to filter log events for errors and failures; this is the first step in the alerting strategy. Read more about setting up a winning alerting strategy for operational excellence.
OPS 2: How do you approach application lifecycle management?
When you answered the last question sufficiently, you’re able to start implementing the actual system. The imperative here is: Always automate.
If you build a new subsystem, you should prototype it with infrastructure as code (IaC) in a separate AWS account. The IaC tool allows you to replicate your new system with a click in a production account later. Using different accounts gives you more wiggle room with the limits on AWS account and limits the blast radius if something goes wrong. IaC can also be versioned, which makes keeping track of changes quite a bit simpler.
With CodePipeline and CodeBuild AWS also offers their own CI/CD tools that can package, test, and deploy your systems directly into different AWS accounts.
Summary
The OPS pillar is all about enabling your team to do their best work. It focuses on keeping your team members’ skills up to date and everyone knowing what’s expected of the system they build. This doesn’t just mean they should know about the features they have to implement and how to think about automation and security.
You should always use IaC to manage your system so that you can experiment quickly in different accounts.
Don’t forget about monitoring! Cloud services, and serverless services, in particular, often seem like a black box to many developers. “If I can’t run and debug it on my machine, how should I debug it at all?” But with monitoring solutions like Dashbird, you can always stay on top of things, whether it’s about bugs, changes in user engagement, or changes to your deployments.
You can find out more about building complex, Well-Architected serverless architectures in our recent webinar with Tim Robinson (AWS):





Top comments (0)