
And just like that – welcome to the last part in our “Well-Architected and Serverless” series. We hope it’s been informative, insightful, and fun for you, to explore the five pillars of the AWS Well-Architected Framework (WAF) with us!
The Performance Efficiency Pillar
The PERF pillar is all about using cloud resources efficiently. This also includes efficient operation if the demand changes.
Do you deliver the most efficient solution to your customers?
This is a recurring question you should ask yourself a few times a year. This means selecting the right services for your requirements and thinking about what those requirements really are.
If you don’t communicate correctly with your customers, it could be that you want to deliver them something they aren’t interested in paying for. For example, if you can make a service deliver results in under 100ms time, but your customers would be okay to get them in a few seconds, you can save on engineering time and resource cost that such a high-performance system would otherwise require.
The PERF, COST, and REL pillars can be traded for each other to get the best solutions for your business.
Let’s look into the four parts that make up the PERF pillar, to understand how to achieve this.
Selection
There are many services in the AWS portfolio, so you should take some time to research before using one of them. A focus on serverless architecture removes a huge chunk of services from this list. But sometimes, it can be beneficial to use a non-serverless service for parts of your business. If you need real-time performance, an architecture based on Lambda functions may not cut it, and you have to look into containers.
These services also can be configured in different ways. Lambda alone comes in many sizes. So even if you only focus on serverless technology, think about how each of these services can be used most efficiently.
Maybe you need that DynamoDB Accelerator to meet your business requirement. Maybe, you need a global table to get latency down to an acceptable level. But maybe you don’t and can focus your optimization efforts on different aspects of your system.
Review
Use infrastructure as code and automated performance tests. This way, you’re able to review new options faster and see if they improve efficiency in a meaningful way.
You need well-defined technical and business metrics to measure things. As I said, it’s cool if you can deliver something in real-time, but if nobody wants to pay for it, don’t invest time into optimization here.
Paying for it includes all costs here. Not just the operational costs but also the costs of implementing the solution. More often than not, the engineering building the solution can be the highest price point.
Monitoring
Always monitor your system; otherwise, you don’t really know what it’s doing. This is true for every pillar. If you build your system based on some assumptions, it could still fail to meet your goals in practice. After all, they were just assumptions.
You have to gather production data about your efficiency and try to use this real data for your architecture’s next iterations. This might be a sobering experience, especially the first few times you do this, but remember, it’s all about getting the right result. It doesn’t help anyone but your ego if everyone just thinks you were right.
For small-scale serverless environments, AWS CloudWatch could easily do the job, as it provides just enough data for metrics for invocations, but doesn’t have the ability to deep dive into retries, cold starts, memory usage, or cost.
Dashbird was built to support and strengthen your serverless application through a single pane on glass view, out-of-the-box error and warnings alerts, and actionable best practice recommendations, no matter the size of the stack.
Integrating with your AWS account, Dashbird takes monitoring a step further with its AWS Well-Architected Insights engine proactively assessing your infrastructure, alerting you of errors, and highlighting optimization opportunities, and thus, helping your environment to always stay aligned with the AWS Well-Architected Framework’s pillars.
Trade-Offs
Sometimes you have to make trade-offs in your architecture. And with sometimes, I mean always. Jokes aside, this is what makes engineering work interesting. Maybe you can get away with eventual consistency and deliver much lower latency in turn. But maybe you run a bank, and making your customer’s accounts eventually consistent isn’t the best course of action here.
Maybe, you’re tight on personnel and simply can’t afford the complexity a multi-tier caching solution brings, even if the improved performance sounds awesome. Simplicity also has a business value in the long run. Always think about what you need and what you can pay for it regarding money, reliability, durability, and complexity.
Read more about how professional serverless teams manage software issues.
SAL Questions for the Performance Efficiency Pillar
Again, like with the COST pillar, there is just one SAL question for the PERF pillar.
PER 1: How have you optimized the performance of your serverless application?
There are a lot of ways to optimize a serverless application. In our experience, the majority of opportunities come from using the right mix of services and best practices and avoiding waste through bad architectural design decisions. For example, using the right databases and downstream services, not waiting in code, and instead of using Step-Functions to orchestrate logic, selecting between API Gateway and ALB for APIS and such. Often, the majority of your serverless cost and performance overhead is accumulated in services other than Lambda functions.
An example of optimizing DynamoDB: depending on how predictable your traffic is, on-demand or provisioned capacity can be the right choice for your DynamoDB tables. The DynamoDB Accelerator could also be a way to get out that last bit of performance.
Optimising Lambda functions
If you are optimizing Lambda functions, there are multiple methods to identify the biggest opportunities for increased efficiency. The first thing we recommend doing is finding the highest latency and highest volume Lambdas, that affect the user experience the most and focus on them. Dashbird provides a breakdown of all the functions and their performance in a single pane of class and you can order your functions based on the highest throughput and lowest response times.
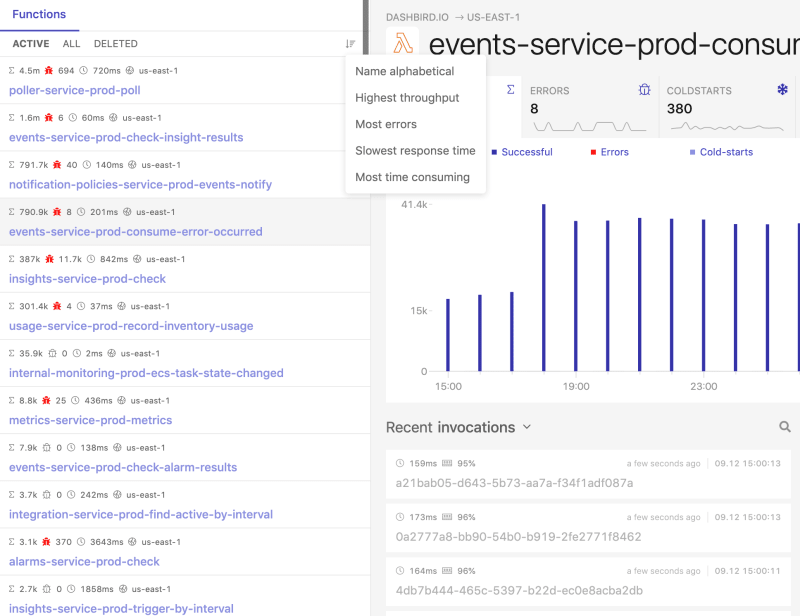
When you have identified a problem in any one of your functions, the next step is to dive deeper and understand where you’re struggling to perform. Is the function execution very processing-heavy and provisioning more memory would help speed up the execution? Or maybe it’s waiting most of its execution time for a third-party service, and adding more resources does nothing to speed up the performance? To understand the breakdown of an individual invocation, Dashbird integrates with AWS X-Ray and shows the list and duration of each individual activity executed within the function.

Understanding the situation within the execution enables developers to take further action and to either experiment with memory provisioning of an application or make changes to the services that the function is communicating with to optimize the performance or cost a specific function.
On top of helping you optimize your functions, Dashbird analyses the metrics and configurations of other managed services typically used in a serverless architecture and offers actionable recommendations on provisioning, configuration, helping you make informed decisions about your serverless stack. Dashbird also surfaces slow and increased-delay situation across databases, API Gateways, SQS queues, Kinesis stream, and others.
Wrapping up
The PERF pillar helps you focus on using your resources most efficiently. Serverless technology often includes optimizations mentioned in that pillar implicitly, but it’s not just about choosing the right services.
The PERF pillar is also about configuring the services you use correctly. Think about the memory size of your Lambda functions. Think about the deployment configuration of your API Gateway. And also, think about the capacity of your DynamoDB tables.
Make sure you define the right metrics when monitoring your system; this way, you can optimize the parts that matter. Also, review new releases every now and then. AWS releases new services every year and also updates its existing ones. Sometimes your systems just get faster or cheaper without you doing anything. For example, during re:Invent 2020, AWS announced strong consistency for S3 without any more cost or configuration, and millisecond-based pricing for AWS Lambda; your existing apps profit from that without you doing anything. But sometimes, you need to explicitly configure a service differently to get the benefits, like with the new 10GB memory size of Lambda.
And finally, remember that everything has a trade-off. Lambda can scale to thousands of parallel invocations in a matter of seconds, but it could be that your system needs more than 15 minutes of invocation times to do its work.
Well-Architected Series Summary
The WAF whitepapers are a good source of ideas to start improving the systems you build on AWS. They are very dense, so you might not understand everything right from the start, but you can always revisit them if you have the time or need to solve technical issues. Sometimes the examples from the whitepapers only make sense if you tried to build a system by yourself.
Or you can skip all that and let Dashbird’s Well Architected actionable insights, warnings and errors engine tell you exactly what’s going on in your system, what needs improvement, and where exactly, what’s about to break and what’s broken. Find out more or book a call – we love taking serverless and Well Architected.
If you’re building your architecture based on serverless technology, you will follow most of the advice given in the WAF pillars implicitly, and if not, the SAL focuses on the things that serverless technology might not solve for you out-of-the-box.
If you’re still curious to learn more about the WAF, how it came about and some more best practices for each of the five pillars, you can watch our recent session with Tim Robinson (AWS) here:





Top comments (0)