Part 3. FoodGraph: Loading data and Querying the graph with SPARQL

Did you ever try a Maritozzo?
In the past post, we converted the recipe data, stored in JSON files, into RDF triples. In this post, we show you:
- how we loaded this data on Amazon Neptune;
- how we integrated the output of the extractor and classifier systems in FoodGraph;
- how we can query the graph to extract useful and connected information.
To query the graph, we use SPARQL. SPARQL is an RDF query language, namely a semantic query language for databases, able to retrieve and manipulate data stored or viewed in the RDF format.
Loading data on Amazon Neptune
We followed the described procedure to load the RDF triples on the Amazon Neptune service.
We used an Amazon Simple Storage Service, the Amazon S3 bucket. Firstly we created an S3 bucket; then we uploaded the data. In this first phase, we loaded the RDF data to build the first level of the graph (see the previous article).
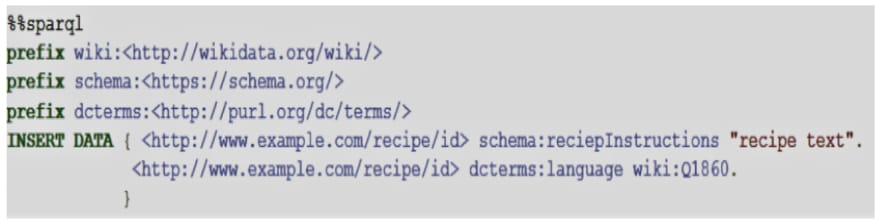
In the case we want to add a few recipes at the time, we can alternatively use the SPARQL statement INSERT DATA :
Integrating the extractor and classifier services within the graph
Once the recipes have been loaded, we checked whether there are recipes not yet processed by the extractor and classifier services. This means to check which recipes have not
i) food entity chunks extracted (the bnode in the graph, see the previous article);
ii) ingredients classified.
This is the SPARQL query to check whether bnodes exist in the graph (through the statement FILTER NOT EXISTS), which is equivalent to say “return all the recipes without bnodes”:

Extracting knowledge from the graph via SPARQL
Now the graph is on Amazon Neptune. Let’s have fun of these connections, extracting knowledge from the graph:
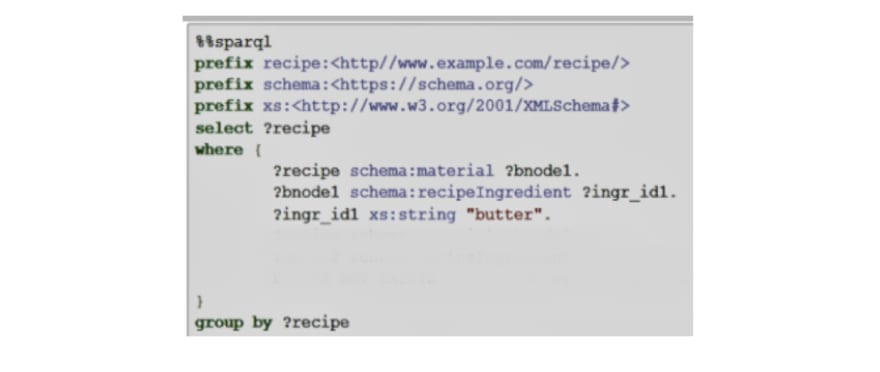
With the above query we interrogate the graph to know 1) whether there are recipes containing the ingredient “butter” and 2) which are these recipes. The WHERE statement navigates the graph following the pattern described in the triples to arrive at the query result. In this case, the output is the id of the recipes which have the ingredients ”butter”.
We can query the graph to return recipes containing more than one ingredient or all the recipes containing some ingredients and not others:

The Smart Recipe Project: what has been done, what can be done
With this last article, we conclude illustrating the main stages of the Smart Recipe Project, this innovative and amazing project involving on one side the global company Condé Nast, and on the other the IT company RES.
We have in mind some possible interesting applications for the resources we developed under the Smart Recipe Project like:
personalization of contents, personalized recipe searchers, newsletter;
recommendation systems for food items, recipes, and menus, which integrate, where needed, dietary restrictions;
virtual assistants, able to guide you in planning and cooking meals;
smart cooking devices, and much more.
As always, go on Medium to read the complete article.
When Food meets AI: the Smart Recipe Project
a series of 6 amazing articles
Table of contents
Part 1: Cleaning and manipulating food data
Part 1: A smart method for tagging your datasets
Part 2: NER for all tastes: extracting information from cooking recipes
Part 2: Neither fish nor fowl? Classify it with the Smart Ingredient Classifier
Part 3: FoodGraph: a graph database to connect recipes and food data
Part 3. FoodGraph: Loading data and Querying the graph with SPARQL

Top comments (0)