Part 2. Neither fish nor fowl? Classify it with the Smart Ingredient Classifier

Mussel soup
In the previous article, we extracted food entities (ingredients, quantities and units of measurement) from recipes. In this post, we classify the ingredient taxonomic class using the BERT model. In plain words, this means to classify Emmental as cheese, orange as a fruit, peas as a vegetable, and so on for each ingredient in recipes.
BERT in five points
Since its release in late 2018, BERT has positively changed the way to face NLP tasks, solving many challenging problems in the NLP field.
Under this view, one of the main problems in NLP consists of a lack of training data. To cope with this lack, the idea is to exploit a large amount of unannotated data for training general-purpose language representation models, a process known as pre-training, and then fine-tuning these models on a smaller task-specific dataset.
Though this technique is not new (see word2vec and GloVE embeddings), we can say, BERT exploits it better. Why? Let’s find it out in five points:
- It is built on a Transformer architecture, a powerful state-of-the-art architecture, which applies an attention mechanism to understand relationships between tokens in a sentence.
- It is deeply bidirectional since it takes into account the left and right contexts at the same time.
- BERT is pre-trained on a large corpus of unlabeled text that allows to pick up the deeper and intimate understandings of how the language works.
- BERT can be fine-tuned for different tasks by adding a few additional output layers.
- BERT is trained to perform:
- Masked Language Modelling: BERT has to predict randomly masked words.
- New sentence prediction: BERT tries to predict the next sentence in a sequence of sentences.
The Smart Recipe Project Taxonomy
To carry out the task, we designed a taxonomy, a model of classification for defining macro-categories and classifying the ingredients within them:
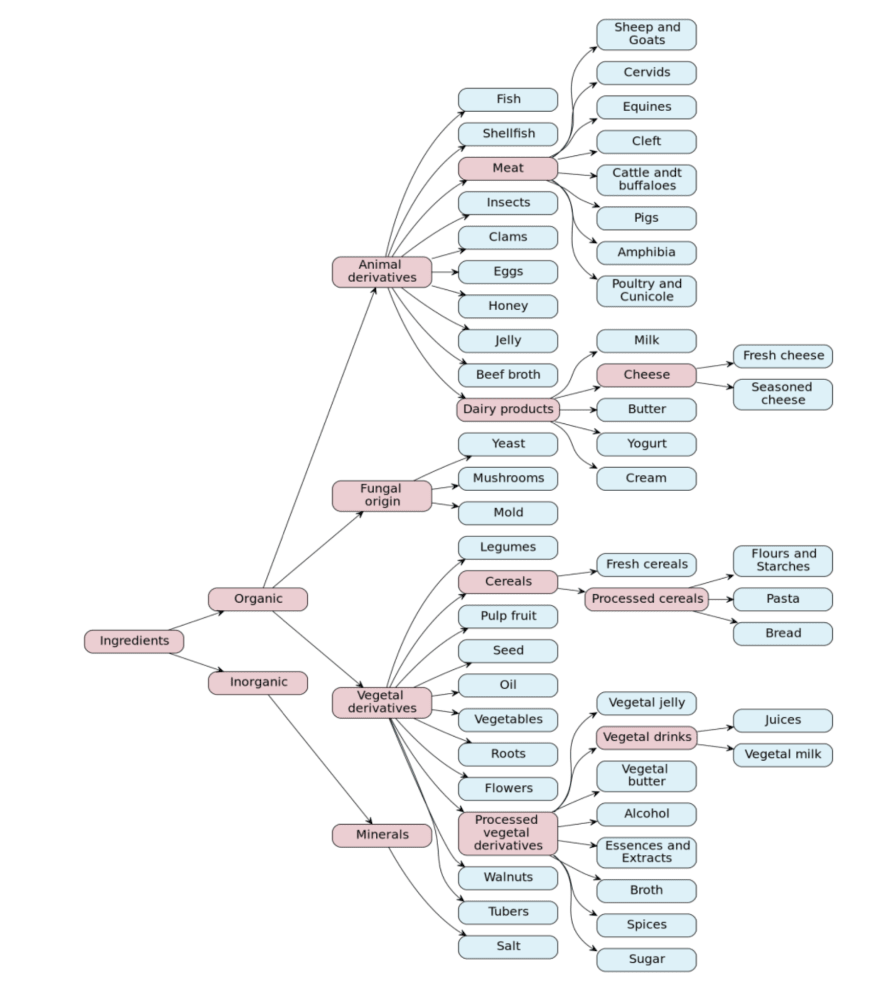
Such categorization is then used to tag the dataset that trains the model.
BERT for ingredient taxonomic classification
For our task (ingredient taxonomic classification), the pre-trained BERT models have optimal performance. We chose the bert-base-multilingual-cased model and divided the classifier into two modules:
A training module. We used Bert For Sequence Classification a basic Bert with a single linear layer at the top for classification. Both the pre-trained model and the untrained layer were trained on our data.
An applying module. The applier takes the trained model and uses it to determine the taxonomic class of the ingredient in the recipe.
You can find a more detailed version of the post on Medium.
When Food meets AI: the Smart Recipe Project
a series of 6 amazing articles
Table of content
Part 1: Cleaning and manipulating food data
Part 1: A smart method for tagging your datasets
Part 2: NER for all tastes: extracting information from cooking recipes
Part 2: Neither fish nor fowl? Classify it with the Smart Ingredient Classifier
Part 3: FoodGraph: a graph database to connect recipes and food data
Part 3. FoodGraph: Loading data and Querying the graph with SPARQL

Top comments (1)
When food meets AI: the Smart Recipe Project is revolutionizing how we cook by leveraging artificial intelligence to create personalized and efficient cooking experiences. This project utilizes AI to suggest recipes based on available ingredients, dietary preferences, and even nutritional needs, making meal preparation easier and more enjoyable. One of the delightful recipes it might suggest is for tanghulu recipe, a traditional Chinese snack that involves skewering fruits like hawthorn berries or strawberries and coating them in a hardened syrup, resulting in a sweet and crunchy treat. With AI's assistance, even complex recipes like Tanghulu can be mastered by home cooks of all skill levels.