Part 2. NER for all tastes: extracting information from cooking recipes

In the previous articles, we constructed two label datasets to train machine learning models and develop systems able to interpret cooking recipes.
This post dives into the extractor system, a system able to extract ingredients, quantities, time of preparation, and other useful information from recipes. To develop the service, we tried different Named Entity Recognition (NER) approaches.
Hold on! What is NER?
ER is a two-step process consisting of a) identifying entities (a token or a group of tokens) in documents and b) categorizing them into some predetermined categories such as Person, City, Company... For the task, we created our own categories, which are INGREDIENT, QUANTIFIER and UNIT.
NER is a very useful NLP application to group and categorize a great amount of data which share similarities and relevance. For this, it can be applied to many business use cases like Human resources, Customer support,Search and recommendation engines,Content classification, and much more.
NER for the Smart Recipe Project
For the Smart Recipe Project, we trained four models: a CRF model, a BiLSTM model, a combination of the previous two (BiLSTM-CRF) and the NER Flair NLP model.
CRF model
Linear-chain Conditional Random Fields - (https://medium.com/ml2vec/overview-of-conditional-random-fields-68a2a20fa541)[CRFs] - are a very popular way to control sequence prediction. CRFs are discriminative models able to solve some shortcomings of the generative counterpart. Indeed while an HHM output is modeled on the joint probability distribution, a CRF output is computed on the conditional probability distribution.
In poor words, while a generative classifier tries to learn how the data was generated, a discriminative one tries to model just observing the data
In addition to this, CRFs take into account the features of the current and previous labels in sequence. This increases the amount of information the model can rely on to make a good prediction.
Fig.1 CRF Network
For the task, we used the Stanford NER algorithm, which is an implementation of a CRF classifier. This model outperforms the other models in accuracy, though it cannot understand the context of the forward labels (a pivotal feature for sequential tasks like NER) and requires extra feature engineering.
BiLSTM with character embeddings
Going neural... we trained a Long Short-Term Memory (LSTM) model. LSTM networks are a type of Recurrent Neural Networks (RNNs), except that the hidden layer updates are replaced by purpose-built memory cells. As a result, they find and exploit better long-range dependencies in the data.
To benefit from both past and future context, we used a bidirectional LSTM model (BiLSTM), which processes the text in two directions: both forward (left to right) and backward (right to left). This allows the model to uncover more patterns as the amount of input information increases.
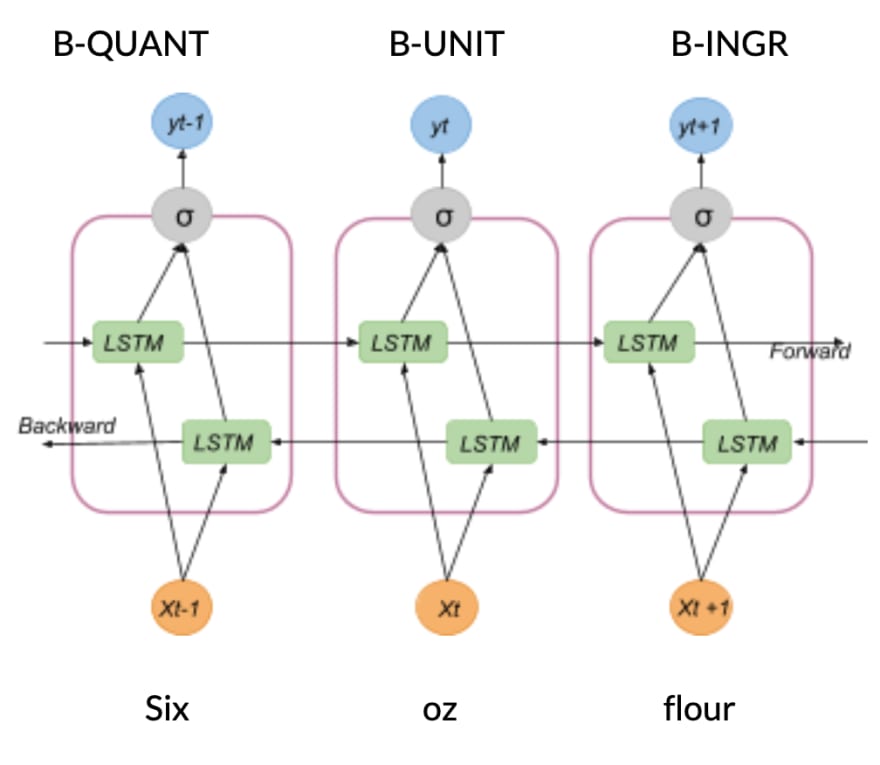
Fig.2 BiLSTM architecture
Moreover, we incorporated character-based word representation as the input of the model. Character-level representation exploits explicit sub-word-level information, infers features for unseen words and shares information of morpheme-level regularities.
NER Flair NLP
This model belongs to the (https://github.com/flairNLP/flair)[Flair NLP library] developed and open-sourced by (https://research.zalando.com/)[Zalando Research]. The strength of the model lies in a) the use of state-of-the-art character, word and context string embeddings (like (https://nlp.stanford.edu/projects/glove/)[GloVe], (https://arxiv.org/abs/1810.04805)[BERT], (https://arxiv.org/pdf/1802.05365.pdf)[ELMo]...), b) the possibility to easier combine these embeddings.
In particular, (https://www.aclweb.org/anthology/C18-1139/)[Contextual string embedding] helps to contextualize words producing different embeddings for polysemous words (same words with different meanings):
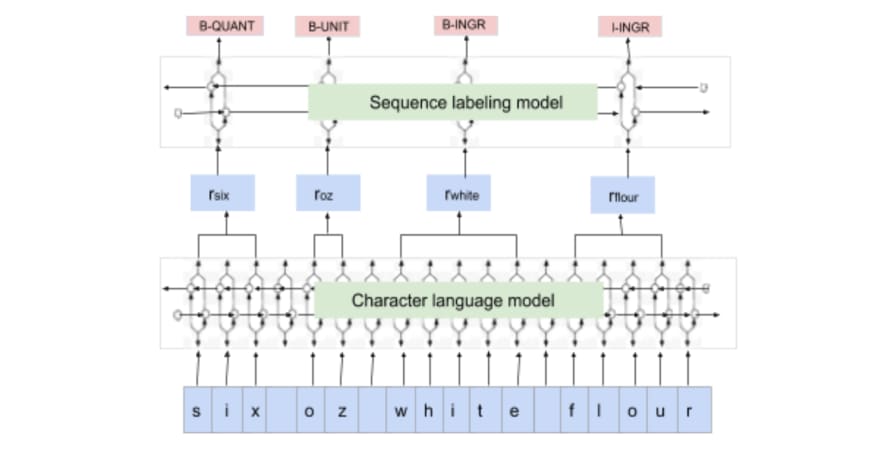
Fig.3 Context String Embedding network
BiLSTM-CRF
Last but not least, we tried a hybrid approach. We added a layer of CRF to a BiLSTM model. The advantages (well explained here) of such a combo is that this model can efficiently use both 1) past and future input features, thanks to the bidirectional LSTM component, and 2) sentence level tag information, thanks to a CRF layer. The role of the last layer is to impose some other constraints on the final output.
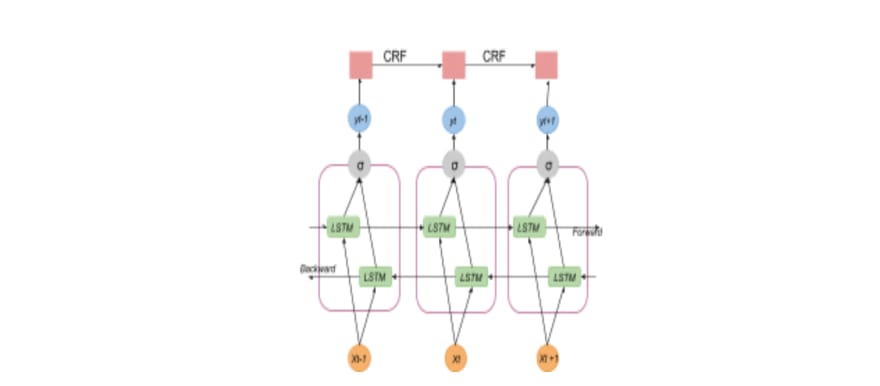
Fig. 4 BiLSTM-CRF: general architecture
What about performance?
(https://medium.com/@condenastitaly/when-food-meets-ai-the-smart-recipe-project-8dd1f5e727b5)[Read the complete article on medium], to discover that and more about this step of the Smart Recipe Project.
When Food meets AI: the Smart Recipe Project
a series of 6 amazing articles
Table of content
Part 1: Cleaning and manipulating food data
Part 1: A smart method for tagging your datasets
Part 2: NER for all tastes: extracting information from cooking recipes
Part 2: Neither fish nor fowl? Classify it with the Smart Ingredient Classifier
Part 3: FoodGraph: a graph database to connect recipes and food data
Part 3. FoodGraph: Loading data and Querying the graph with SPARQL

Top comments (9)
Named Entity Recognition (NER) is carried out in two stages:
Entity Identification – detecting specific tokens or groups of tokens within a document.
Entity Categorization – assigning those entities to predefined classes.
In this project, instead of standard categories like Person, City, or Company, we introduced domain-specific ones: INGREDIENT, QUANTIFIER, and UNIT. This customization allows NER to effectively process recipe data.
Because NER can organize and classify large amounts of related information, it has broad applications across industries, including human resources, customer support, search and recommendation systems, and content classification, making it a versatile tool for extracting structured insights from unstructured text.
According to Wikipedia, Named Entity Recognition (NER) is a key natural language processing technique that identifies and classifies entities like ingredients, measurements, or times within text — widely used in AI-driven systems. The post effectively explores how CRF and BiLSTM models enhance recipe interpretation through contextual understanding. Similarly, the chiptle menu uses data-driven insights to optimize flavor combinations and create personalized, fresh dining experiences inspired by global culinary trends.
The Smart Recipe Project effectively uses Named Entity Recognition (NER) models like CRF and BiLSTM to extract ingredients, quantities, and preparation times, enhancing how recipes are understood by AI systems. As explained on Wikipedia, NER plays a vital role in natural language processing, enabling machines to interpret structured data from unstructured text efficiently. Similarly, the chik fila menu reflects intelligent organization by categorizing diverse food items for easy selection and personalized customer experiences.
The Named Entity Recognition (NER) process involves two main steps: first, identifying entities—whether individual tokens or groups of tokens—within a document, and second, classifying them into predefined categories. While traditional NER categories might include Person, City, or Company, in this task we designed custom categories tailored to the recipe domain: INGREDIENT, QUANTIFIER, and UNIT.
NER’s ability to efficiently group and classify large volumes of data based on shared attributes makes it a powerful NLP application. Beyond culinary applications, it is widely used across various business domains such as human resources, customer support, search and recommendation engines, and content classification, enabling smarter, more context-aware systems.
The Smart Recipe Project uses advanced Named Entity Recognition (NER) to extract structured data like ingredients and cooking times from unstructured recipe text, enabling smarter, AI-powered culinary tools. Techniques such as CRF, BiLSTM, and Flair NLP models are explored, with each offering unique strengths in accuracy and context understanding. As explained on Wikipedia, NER is widely used in natural language processing for entity classification and data extraction in various domains. This innovative application of machine learning bridges AI and gastronomy in a way that enhances both kitchen efficiency and user experience. Such intelligent systems could one day personalize recommendations like the olive garden menu based on your tastes.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.