The project
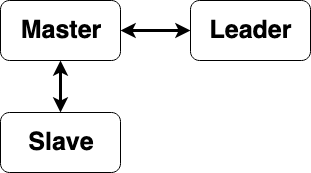
This project was done for network and distributed programming subject of University of São Paulo. The idea of the project was to build a distributed program that would run on different nodes, and it had the goal of sorting an array (using all the nodes in our network). It needed to support the addition of new nodes, death of nodes, and the change of "leader nodes" that would distribute the work load. The array would start in one of the nodes that would act as a "master".
Link to Code
 breno-helf
/
Network-Distributed-Prog
breno-helf
/
Network-Distributed-Prog
Porgrams done for "Computer Networks and Distributed Systems" subject from University of Sao Paulo
Redes
Porgrams done for "Computer Networks and Distributed Systems" subject from University of Sao Paulo
Each folder represent a different project. EP means "Exercicio Programa" in portuguese, and it can be translated by "Programming assingment".
EP1
We had to code a simple FTP server, with some functionalities. This project had to be done in C.
EP2
We had to do a program that would sort an array in a distributed fashion. It had some restrictions, such it had to implement leader election (even though it maybe unnecessary).
EP3
We had to follow a tutorial to implement a switch and firewall with OpenFlow.
EP4
In this assingment we had to explore a security breach, we choose to explore a CRLF of a specific golang version.
How I built it
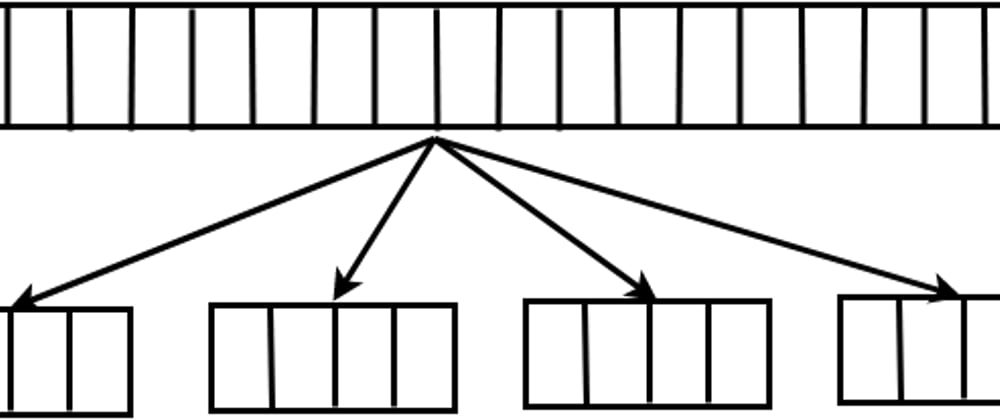
To the project we had freedom of choice. We, (Me and my teammate Matheus Cunha) choose Golang for the language and made some "simple" architecture choices. The first one was how to divide the tasks, we choose to divide the array into chunks, that would be sorted in the nodes with the default sort function of golang. The tasks would come from the master node (that has the data), and the receivers of each task would be defined by the leader node.
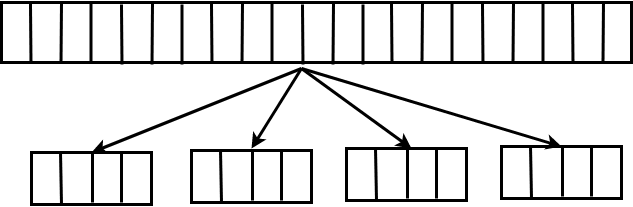
Then we would send the array back to a "master" node, (The one that started with the array). The master node would then register the array into its filesystem.
Later, when all chunks are sorted and stored in the master, the master node would perform the last step, that is going though all chunks in order (we would have a pointer for each chunk in memory) and storing them in a heap, doing some sort of "heap merge" that would take O(N * log(chunks)).
As you may be expecting by the title of this post, the project "failed" in some way. Although it sorted the chunks correctly, it took way more time distributing the tasks than sorting it, so one node used to work better than N nodes (We tested with 1, 2, 3 and 4 nodes, all raspberry pies). The reason it took so long could be many. The extra "leader" -> "master" step (that was required, due to need of implementing leader election, a requirement of the assignment), can be the issue. Maybe its because we used raspberry pies for testing. However, my favorite candidate is the way we decided to transfer the data, through strings that would be parsed by the other side (Serializing and then de-serializing). Just to "compress" the chunk data, would take longer than to sort the entire chunk, which made the whole idea useless.
Why failing this project was good
Well, during this project I think I learned a lot of things. More than just exercising distributed and parallel concepts in practice, I learned what is important, how to measure and diagnoses a problem in a distributed environment and how to think solutions for those problems. None of this things would be learned if I didn't fail, and in the end I am glad I failed. The project didn't had any major goal or responsibility and I learned how to not fail in more important projects.





Top comments (1)
Thanks for sharing that! I'm just looking at my "scaling for robustness" grid system and wondering how much of your issues it will deal with. I guess the issue is the size of the problem being distributed and the cost of the serialization and deserialization. In the end my current system is way simpler than yours - not requiring the fail over of leaders etc and using a "blackboard" style approach for nodes to be able to pick up merging jobs etc.
It makes me wonder in these cases - your approach was imperative and mine inverts control. I can see architectural benefits of inversion here (which is why I wrote it that way) - but I wonder what is has cost me now...
Thanks for the food for thought.