
Flink is almost the de facto standard streaming engine today. Flink SQL is the recommended approach to use Flink. But streaming sql is not the same as the traditional batch sql, you have to learn many new concepts, such as watermark, event time, different kinds of streaming joins and etc. To be honest all of these are not easy to learn.
Today I’d like to introduce you a new (easy) way to learn flink sql: Flink Sql Cookbook on Zeppelin. In Zeppelin you can run Flink SQL in interactive way as following:
All the examples in this post can be found here.
http://zeppelin-notebook.com/
Prepare environment
Step 1
git clone https://github.com/zjffdu/flink-sql-cookbook-on-zeppelin.git
This repo has all the zeppelin notebook which includes the examples in flink-sql-cookbook. Thanks ververica for the great examples, I just migrated them to Zeppelin.
Step 2
Download flink 1.13.1 and untar it. (I haven’t tried other versions of flink, but it should work for all flink versions after flink 1.10)
Step 3
Build flink faker and copy flink-faker-0.3.0.jar to lib folder of flink. This is a custom flink table source which is used to generate sample data.
Step 4
Run the following command to start Zeppelin
docker run -u $(id -u) -p 8081:8081 -p 8080:8080 --rm -v $PWD/logs:/logs -v /mnt/disk1/jzhang/flink-sql-cookbook-on-zeppelin:/notebook -v /mnt/disk1/jzhang/flink-1.13.1:/opt/flink -e FLINK_HOME=/opt/flink -e ZEPPELIN_LOG_DIR='/logs' -e ZEPPELIN_NOTEBOOK_DIR='/notebook' --name zeppelin apache/zeppelin:0.10.0
There’re 2 folders you need to replace with your folder:
- /mnt/disk1/jzhang/flink-sql-cookbook-on-zeppelin (This is the repo folder of step 1)
- /mnt/disk1/jzhang/flink-1.13.1 (This is the flink folder of step 2)
Try examples of Flink Sql Cookbook
Now, the environment is ready, you can start your flink sql journey via opening http://localhost:8080
This is Zeppelin home page, there’s already one folder called Flink Sql Cookbook which includes all the examples.
Example 1: Filtering Data
Now let’s take a look at the first example: Foundations/04 Filtering Data
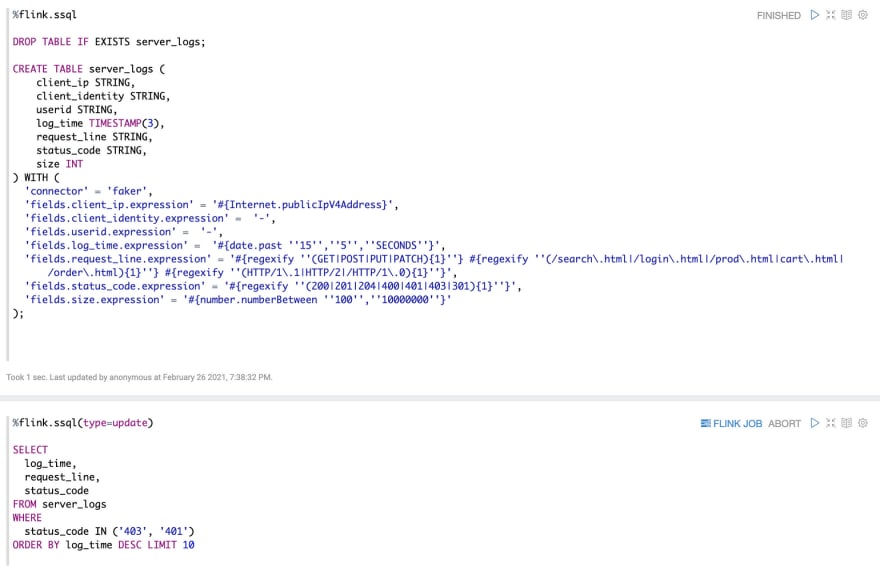
Here’re 2 paragraphs:
- Paragraph 1 is creating table server_logs via faker connector.
- Paragraph 2 is filtering data via where statement and then select the latest 10 records by log_time
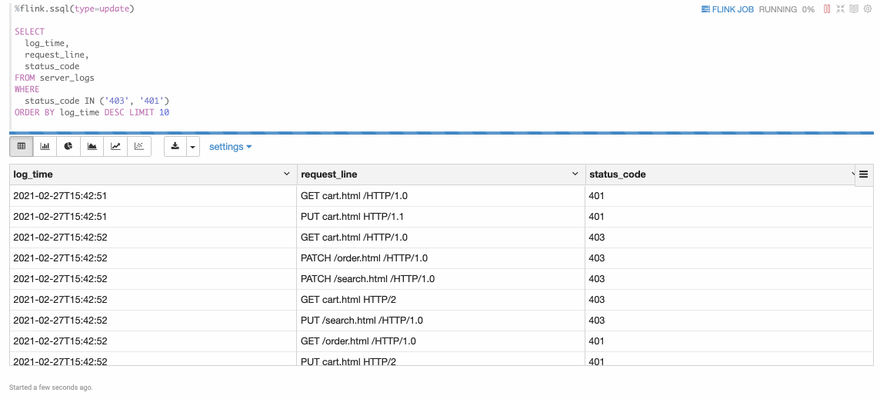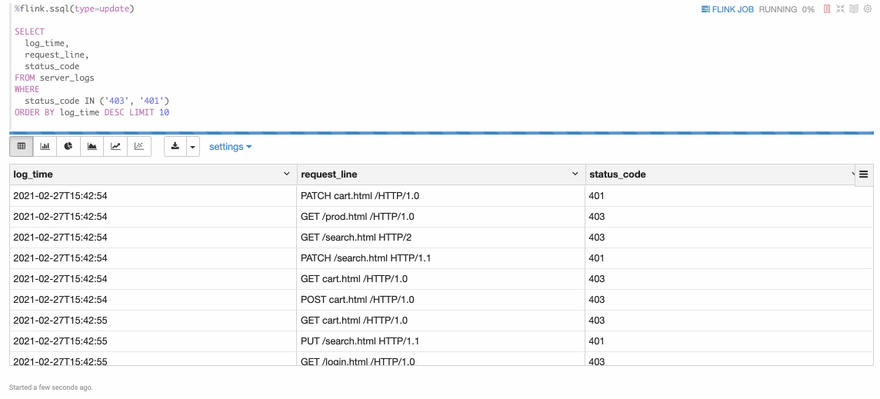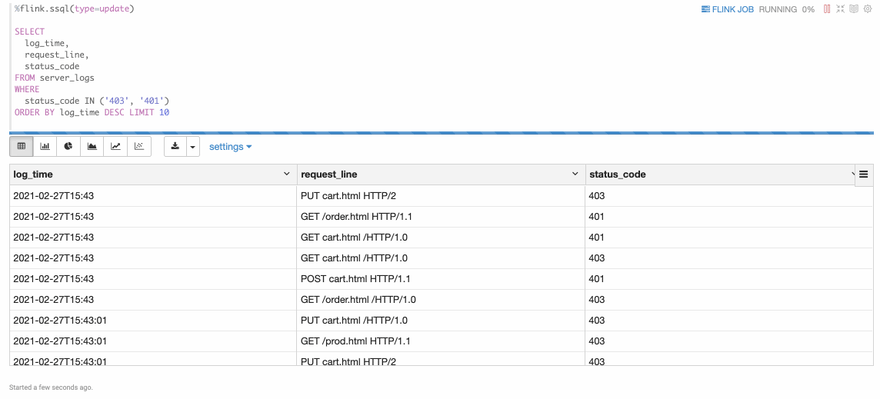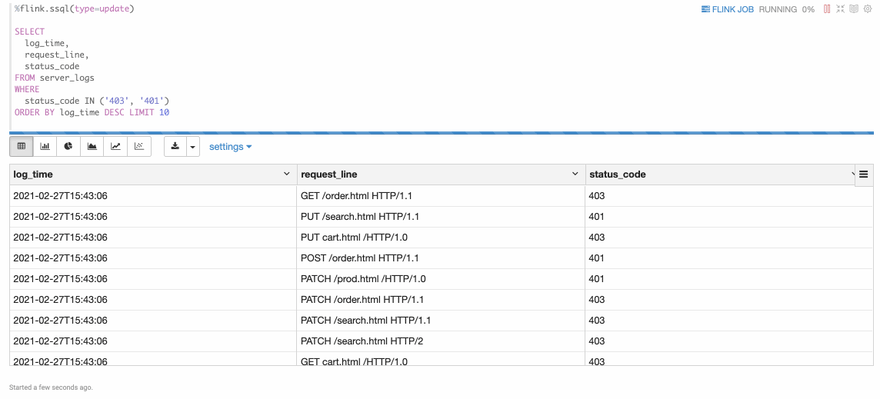
The following is a screenshot of the result. You can see that the result is refreshed every 3 seconds. This is the biggest difference of flink streaming sql compared to traditional batch sql. Because in the streaming world, new data is coming continuously, so you will see the result is updated continuously.
Besides that, you can click the FLINK_JOB link in the top right, it would bring you to the Flink UI of this job.
Example 2: Lateral Table Join
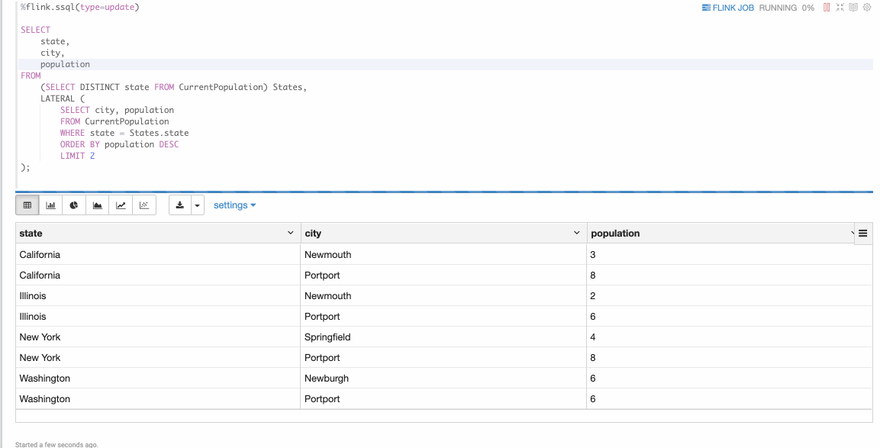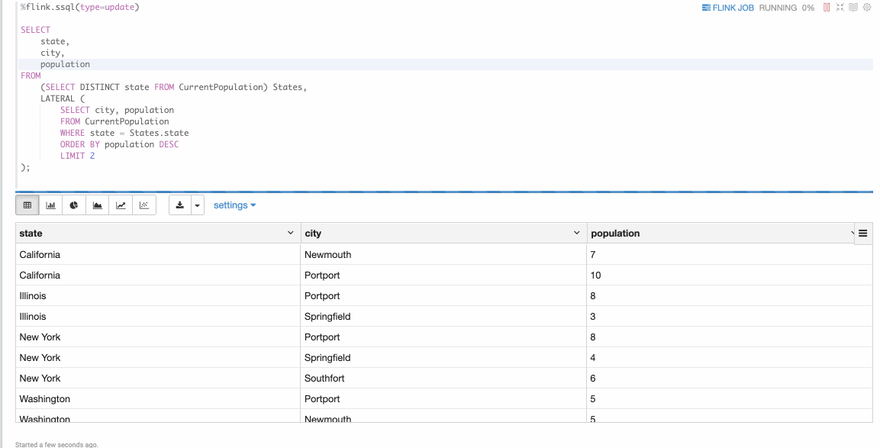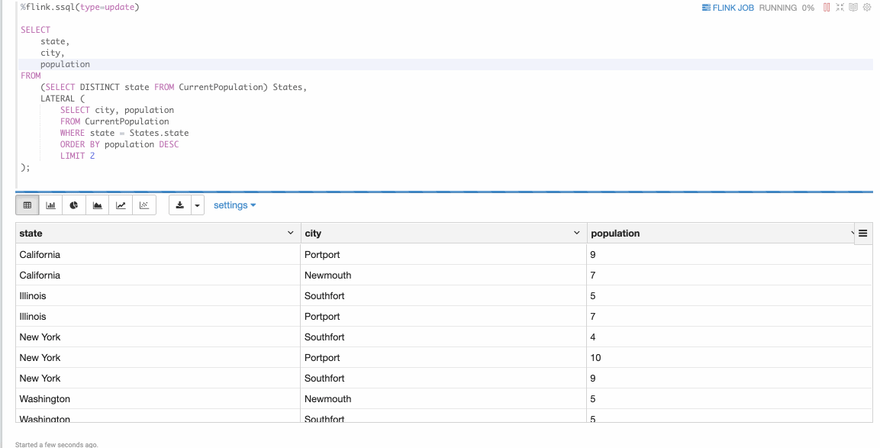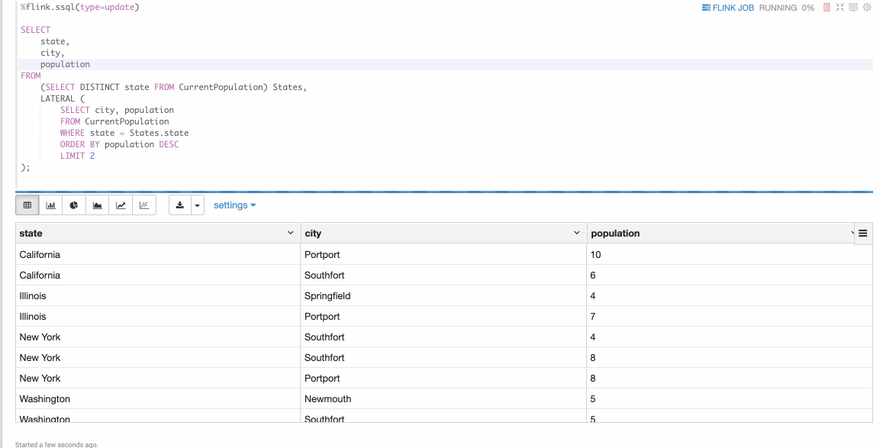
Now let's take a look at the second example: lateral table join. This is one type of the joins that flink sql supports. Usually new beginners would be a little scared at this even after he learn it via some tutorial articles. If there’s one real example could show him what exactly this lateral table join is doing, I believe it would be very helpful for him to understand it. Fortunately, we have one example in this flink-sql-cookbook and you can run it directly in Zeppelin. Open Joins/06 Lateral Table , then run it you can can see the following screenshot.
Here I just show you the above 2 examples, there’re many other examples in this cookbook as below. You can try it by yourself. Hope you will enjoy this flink-sql-cookbook-on-zeppelin.

Summary
Not only you can use Zeppelin to learn Flink SQL, you can also use Zeppelin as your Streaming Platform to submit/manage your flink jobs.
Zeppelin community still try to improve and evolve the whole user experience of Flink on Zeppelin, you can join Zeppelin slack to discuss with community. http://zeppelin.apache.org/community.html#slack-channel
For more details of flink on zeppelin, please refer the following links.

Top comments (0)