Apache Iceberg is a high-performance format for huge analytic tables. There’re a lot of tutorials on the internet about how to use Iceberg. This post is a little different, it is for those people who are curious to know the internal mechanism of Iceberg. In this post, I will use Spark sql to create/insert/delete/update Iceberg table in Apache Zeppelin and will explain what happens underneath for each operation.
Start Zeppelin Docker Container
To demonstrate the internal mechanism more intuitively, I use Apache Zeppelin to run all the example code. You can reproduce what I did easily via Zeppelin docker. You can check this article for how to play Spark in Zeppelin docker. Here I just summarize it as following steps:
- Step 1. git clone https://github.com/zjffdu/zeppelin-notebook.git
- Step 2. Download Spark 3.2.1
- Step 3. Run the following command to start the Zeppelin docker container. ${zeppelin_notebook}is the notebook folder you cloned in Step 1, ${spark_location} is the Spark folder you downloaded in Step 2.
docker run -u $(id -u) -p 8080:8080 -p 4040:4040 --rm -v \
${spark_location}:/opt/spark -v \
${zeppelin_notebook}:/opt/notebook -e \
ZEPPELIN_NOTEBOOK_DIR=/opt/notebook -e SPARK_HOME=/opt/spark \
-e ZEPPELIN_LOCAL_IP=0.0.0.0 --name zeppelin \
apache/zeppelin:0.10.1
Then open http://localhost:8080 in browser, and open the notebook Spark/Deep Dive into Iceberg which contains all the code in this article.
Architecture of Iceberg
Basically, there’re 3 layers for Iceberg:
- Catalog layer
- Metadata layer
- Data Layer
Catalog Layer
Catalog layer has 2 implementations:
- Hive catalog which uses hive metastore. Hive metastore uses relational database to store where’s current version’s snapshot file.
- Path based catalog which is based on file system. This tutorial uses path based catalog. It uses files to store where’s the current version’s metadata file. ( version-hint.text is the pointer which point to each version’s metadata file v[x].metadata.jsonin the below examples)
Metadata Layer
In metadata layer, there’re 3 kinds of files:
- Metadata file. Each CRUD operation will generate a new metadata file which contains all the metadata info of table, including the schema of table, all the historical snapshots until now and etc. Each snapshot is associated with one manifest list file.
- Manifest list file. Each version of snapshot has one manifest list file. Manifest list file contains a collection of manifest files.
- Manifest file. Manifest file can be shared cross snapshot files. It contains a collection of data files which store the table data. Besides that it also contains other meta info for potential optimization, e.g. row-count, lower-bound, upper-bound and etc.
Data Layer
Data layer is a bunch of parquet files which contain all the historical data, including newly added records, updated record and deleted records. A subset of these data files compose one version of snapshot.
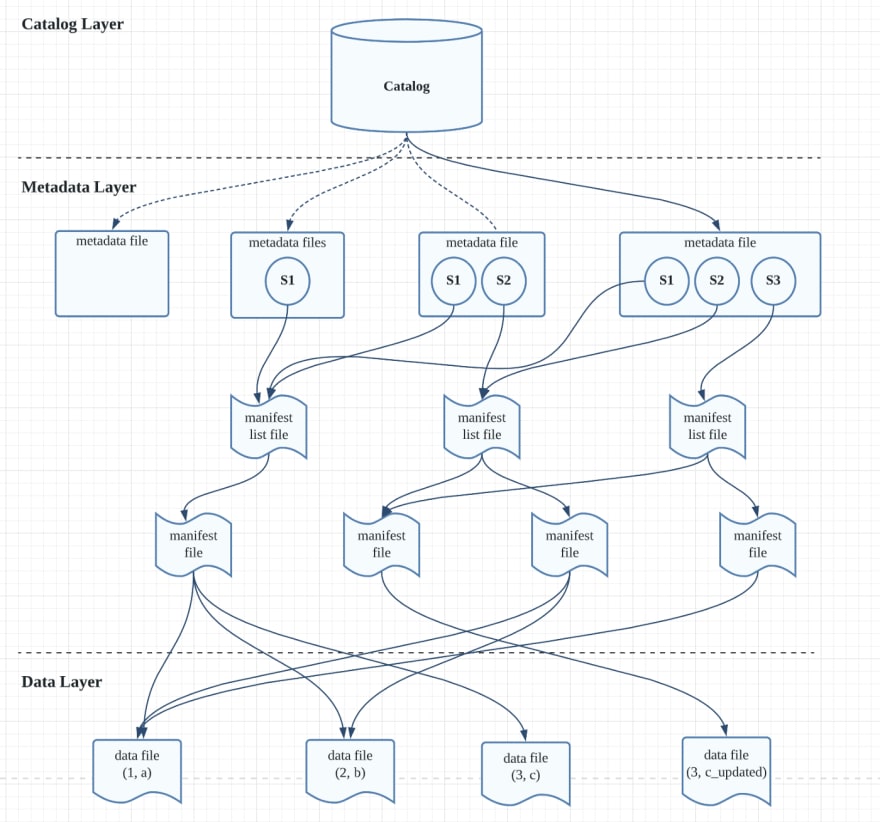
The diagram above is the architecture of Iceberg and also demonstrates what we did in this tutorial
- S1 means the version after we insert 3 records
- S2 means the version after we update one record
- S3 means the version after we delete one record
Preparation
Download jq and avro tools jar
jq is used for display json , avro tools jar is used to read iceberg metadata files (avro format) and display it in plain text.

Configure Spark

%spark.conf is a special interpreter to configure Spark interpreter in Zeppelin. Here I configure the Spark interpreter as described in this quick start. Besides that, I specify the warehouse folder spark.sql.catalog.local.warehouse explicitly so that I can check the table folder easily later in this tutorial. Now let’s start to use Spark and play Iceberg in Zeppelin.
Create Iceberg Table
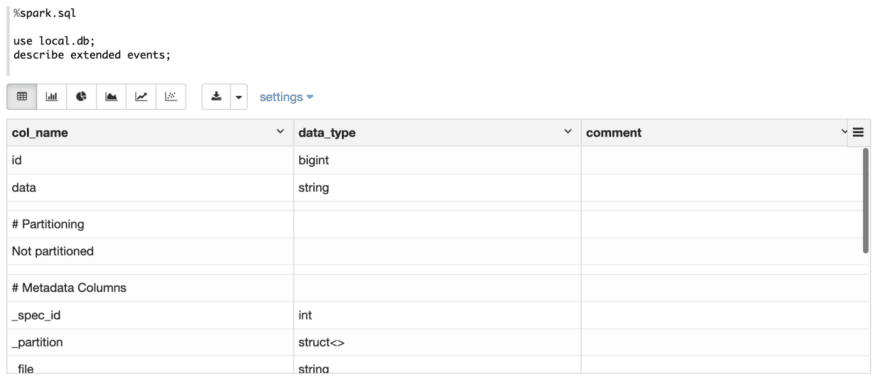
First Let’s create an Iceberg table events with 2 fields: idand data.

Then describe this table to check its details
Check Table Folder
So what does Iceberg do underneath for this create sql statement? Actually, Iceberg did 2 things:
- Create a directory events under the warehouse folder /tmp/warehouse
- Add a metadata folder which contains all the metadata info
Since this is a newly created table, no data is in this table. There’s only one metadata folder under the table folder (/tmp/warehouse/db/events ). There’re 2 files under this folder:
- version-hint.text. This file only contains one number which point to the current metadata file v[n].medata.json)
- v1.metadata.json. This file contains the metadata of this table, such as the schema, location, snapshots and etc. For now, this table has no data, so there’s no snapshots in this metadata file.

Insert 3 Records (S1)
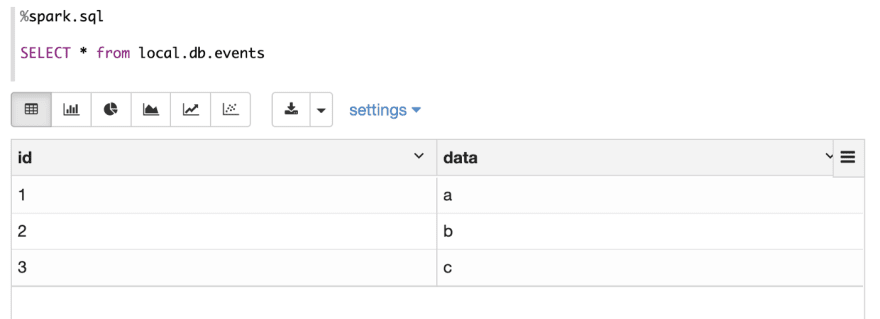
Now let’s insert 3 new records (1, a), (2, b), (3, c)

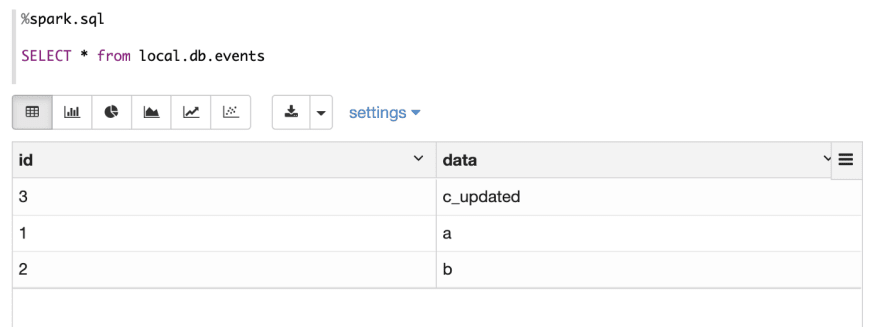
Then use select statement to verify the result.
Check Table Folder
Actually there’re 2 things happened underneath for this insert operation.
- In data folder, 3 parquet files are created. One record per parquet file.
- In metadata folder, the content ofversion-hint.text is changed to 2, v2.metadata.jsonis created which has one newly created snapshot which point to one manifest list file. This manifest list file points to one manifest file which points to the 3 parquet files.

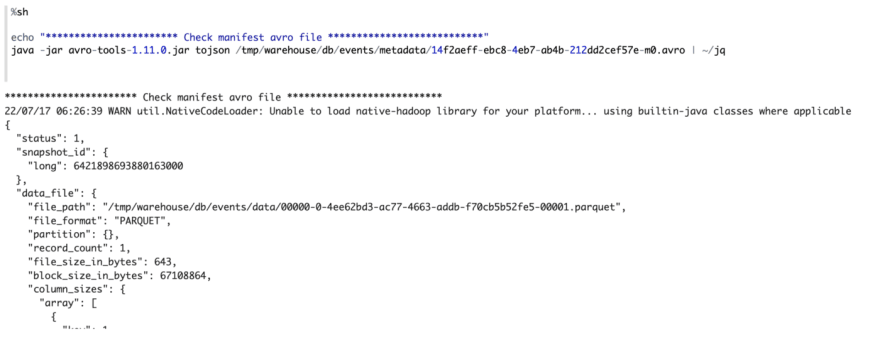
We can use the avro tools jar to read the manifest list file which is avro format. And we find that it stores the location of manifest file and other meta info like added_data_files_count, deleted_data_files_count and etc.

Then use the avro tools jar to read the manifest file which contains the path of the data files and other related meta info.
We can use spark api to read raw parquet data files, and we can find there’s one record in each parquet file.

Update Record (S2)
Now, let’s use update statement to update one record.

Check result after update
Check Table Folder
- In data folder, the existing parquet files are not changed. But one new parquet file is generated.(3,
c_updated) - In metadata folder, the content ofversion-hint.text is changed to 3, v3.metadata.jsonis created which has 2 snapshots. One snapshot is the first snapshot in above step, another new snapshot is created which has a new manifest list file.
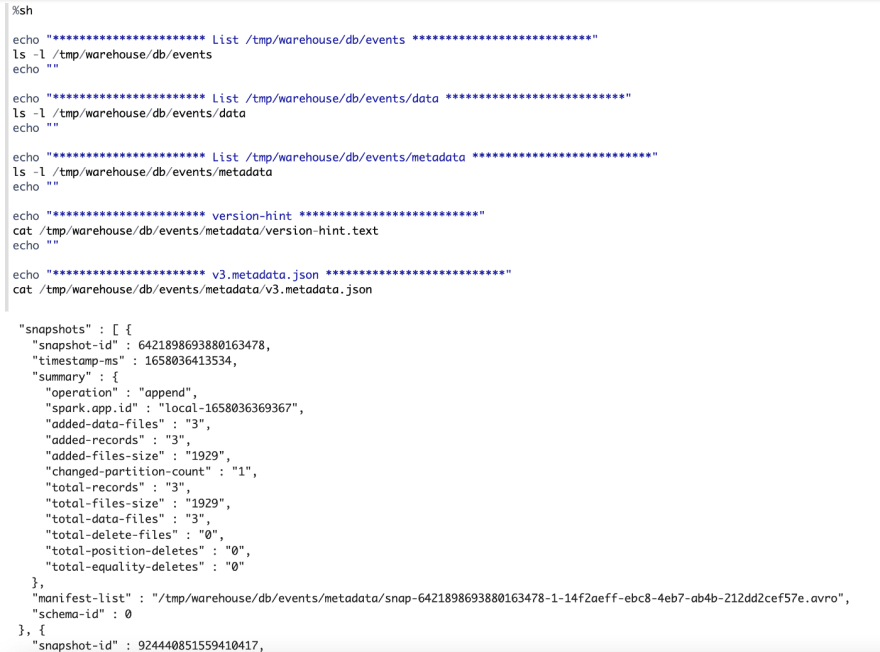
You might be curious to know how Iceberg implements the update operation without changing existing data. This magic happens in Iceberg metadata layer. If you check this version’s metadata file, you will find now it contains 2 snapshots, and each snapshot is associated with one manifest list file. The first snapshot is the same as above, while the second snapshot is associated with a new manifest list file. In this manifest list file, there’re 2 manifest files.
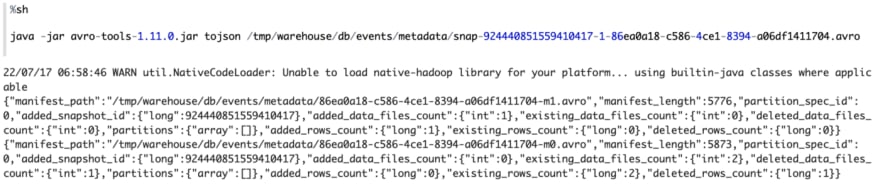
The first manifest file point to newly added data file (3, c_updated). While in the second manifest file, you will find that it still contains 3 data files that contains (1, a), (2, b), (3, c), but the status of the third data file(3, c) is 2 which means this data file is deleted, so when Iceberg read this version of table, it would skip this data file. So only (1,a), (2, b) will be read.

Delete Record (S3)
Now, let’s delete record (2, b)

Use select statement to verify the result
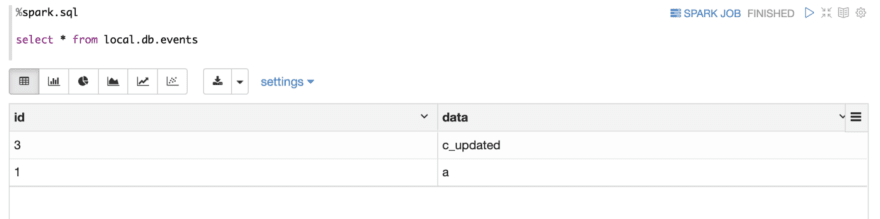
Check Table Folder
- In data folder, nothing changed.
- In metadata folder, the content ofversion-hint.text is changed to 4, v4.metadata.jsonis created which has one more snapshots (totally 3 snapthots).
The manifest list file associated with the new snapshot contains 2 manifest files.

The manifest list file associated with the new snapshot contains 2 manifest files.
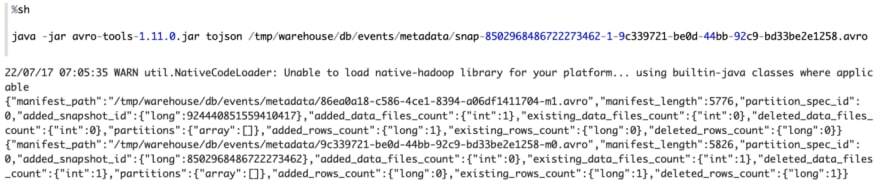
The first manifest point to 1 data files (3, c_updated), , the second manifest file point to data file (1, a), (2, b). But the status of data file (2, b) is 2, which means it has been deleted, so when Iceberg read this version of table, it would just skip this data file. So only (1, a) will be read.

Use spark api to read these data files.

Inspect Metadata
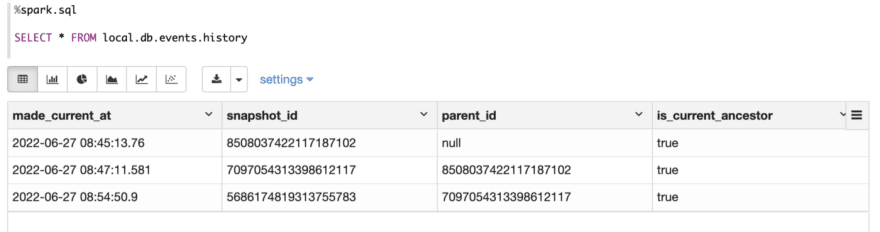
You can also read metadata tables to inspect a table’s history, snapshots, and other metadata.
Inspect history metadata
Inspect snapshot metadata

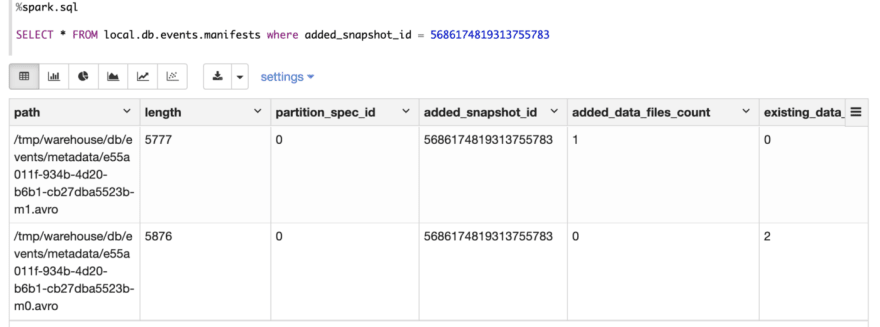
Inspect manifest metadata
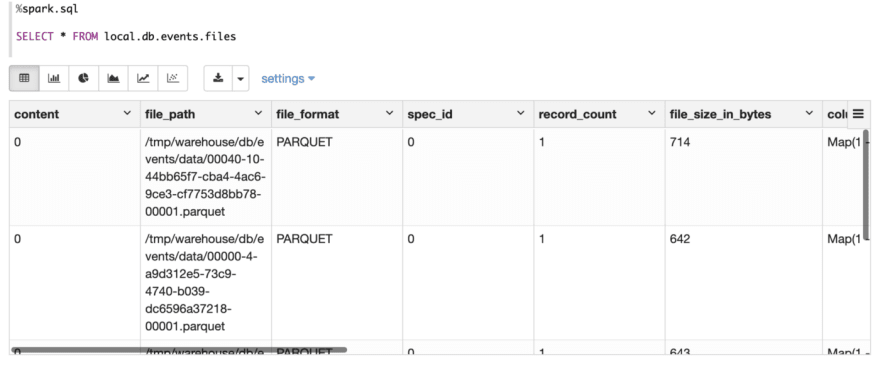
Inspect file meta table
Summary
In this article, I do 4 main steps to play Apache Iceberg:
- Create Table
- Insert Data
- Update Data
- Delete Data
At each step, I check what is changed under the table folder. All the steps are done in Apache Zeppelin docker container, you can reproduce them easily. Just one thing to remember, because the file names are randomly generated (snapshot file, manifest file, parquet file), so you need to update code to use the correct file name. Hope this article is useful for you to understand the internal mechanism of Apache Iceberg.

Top comments (0)