
Delta Lake is an open source project that enables building a Lakehouse architecture on top of data lakes. There’re a lot of tutorials on internet about how to use Delta Lake. This post is a little different, it is for those people who are curious to know the internal mechanism of Delta Lake, especially the transaction log.
Start Zeppelin Docker Container
To demonstrate the internal mechanism more intuitively, I use Apache Zeppelin to run all the example code. You can reproduce what I did easily via Zeppelin docker. You can check this article for how to play Spark in Zeppelin docker. Here I just summarize it as following steps:
- Step 1. git clone https://github.com/zjffdu/zeppelin-notebook.git
- Step 2. Download Spark 3.1.2 (This is what I used in this tutorial, don’t use Spark 3.2.0, it is not supported yet)
- Step 3. Run the following command to start Zeppelin docker container.
${zeppelin_notebook}is the notebook folder you cloned in Step 1,${spark_location}is the Spark folder you downloaded in Step 2.
docker run -u $(id -u) -p 8080:8080 -p 4040:4040 --rm \
-v ${spark_location}:/opt/spark \
-v ${zeppelin_notebook}:/opt/notebook \
-e ZEPPELIN_NOTEBOOK_DIR=/opt/notebook \
-e SPARK_HOME=/opt/spark \
-e ZEPPELIN_LOCAL_IP=0.0.0.0 \
--name zeppelin apache/zeppelin:0.10.0
Then open http://localhost:8080 , and open the notebook Spark/Deep Dive into Delta Lake which contains all the code in this article.
Configure Spark

This is the first paragraph of Deep Dive into Delta Lake, which is to configure Spark interpreter to use Delta Lake.
%spark.conf is a special interpreter to configure Spark interpreter in Zeppelin. Here I configure Spark interpreter as described in this quick start. Besides that I specify spark.sql.warehouse.dir for the warehouse folder explicitly so that I can check the table folder easily later in this tutorial. Now let’s start to use Spark and play Delta Lake in Zeppelin.
Create Delta Table
First Let’s create a Delta table events with 2 fields: id and data.

So what does Delta do underneath for this create sql statement ? Actually Delta did 2 things:
- Create a directory events under the warehouse folder /tmp/warehouse
- Add a transaction log which contains the schema of this table

Insert data
Now let’s insert some data into this Delta table. Here I just only insert only 2 records: (1, data_1), (2, data_2)

Then let’s run select sql statement to verify the result of this insert statement.

So what does Delta do underneath for this insert sql statement ? Let's check the table folder /tmp/warehouse/events , there’re 2 changes
- Another new transaction log file is generated.
- 2 parquet files are generated
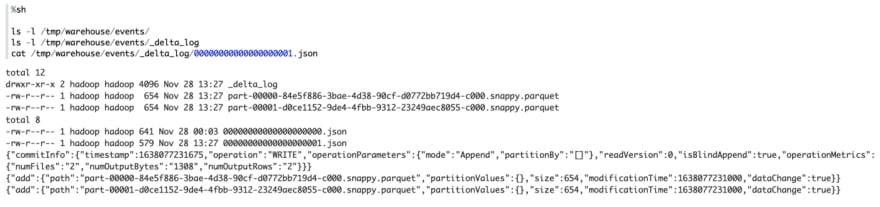
First let’s take a look at the new generated transaction file (00000000000000000001.json). This json file is very readable, it contains the operation of this insert sql statement: Add 2 parquet files which contains the 2 records. To be noticed, there’s no table schema info in this new transaction log file, because it is already in the first transaction log file (00000000000000000000.json). When Delta read the table, it would merge all the historical transaction files since then to get all the information of this table (including the schema of this table and what data files are included)
Since we only insert 2 records, it is natural to guess that each parquet contains one record. We can read these 2 parquet files directly to verify that. As the following code shows, our guess is correct.

Update Data
The most important feature of Delta is ACID support, you can update the table at any time without affecting others who also read/write the same table simultaneously. Now let’s update this events table.

Then run select statement to verify the result of this update statement.
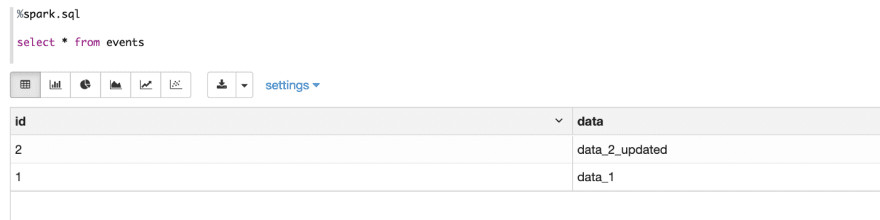
So what does this update statement do underneath ? We can check the events table folder and would find 2 changes:
- Another new transaction log file is generated
- Another parquet file is added (the previous 2 parquet files are still there)

First let’s take a look at the new transaction log file content, there’re 2 operations:
- Remove one parquet file
- Add a new parquet file
It is natural for us to guess that the removed file contains the records (2, data_2), while the new added file contains record (2, data_2_updated). Let’s read these 2 parquet file directly to verify our guess.

Now let’s use the time travel feature of Delta. We would like to use last version of this table before this update operation.

The time travel feature works just because Delta doesn’t delete the data file, it only records all the operations in the transaction logs. When you read version 1 of this table, Delta Lake would only read the first 2 transactions logs: 00000000000000000000.json & 00000000000000000001.json.
Delete Data
Now let’s do the delete operation on this events table.

And then run select statement to verify the result of this delete statement.

So what does Delta do for this delete operation underneath ? We can still check the eventstable folder and would find 2 changes:
- A new metadata transaction log file is generated
- A new parquet file is added

In the new transaction log file we still see 2 operations: remove and add.
It is natural to guess that the remove operation just remove the file which contains record (1, data_1), so what does this new add operation do ?Actually the new added parquet file is empty which contains nothing, we can read these 2 parquet files directly to verify that.

Summary
In this article, I do 4 main steps to play Delta Lake:
- Create Table
- Insert Data
- Update Data
- Delete Data
At each step, I check what is changed in transaction log and data file. All the steps are done in Apache Zeppelin docker container, you can reproduce them easily, hope this article is useful for you to understand the internal mechanism of Delta Lake.

Top comments (0)