
kedro is an open-source data pipeline framework. It provides guardrails to set your project up right from the start without needing to know deeply how to set up your own python library for data pipelining. It includes great ways to manipulate catalogs and pipelines. This article will cover the 10K view of kedro, future articles will dive deeper into each one.
Libraries
Currently, kedro is broken down into 3 different libraries.
💎 kedro
kedro

kedro is the core of the ecosystem. It provides the docs, getting started, kedro new templates, and the core library including the catalog and pipeline.
Catalog

Inside this core library is a data catalog object. This allows you to specify attributes about your data, then load and save it without ever writing a single line of read/write code, which can become very cumbersome. Older versions would load this into the io variable, currently it loads into the catalog. The power of the catalog is that it allows you to read and write data by just referencing its name. Typically this is done inside of a YAML file, but can be done in python.
Here is an example of a CSV dataset stored locally
# Example 1: Loads a local csv file
bikes:
type: CSVLocalDataSet
filepath: "data/01_raw/bikes.csv"
This dataset can be loaded by name
catalog.load('bikes')
Though it's not typical practice it is possible to save data to a catalog entry ad-hoc. Typically the pipeline is used to run functions and save data for you.
import pandas as pd
bikes_df = pd.DataFrame({...<bikes_data>...})
catalog.datasets.bikes.save(bikes_df)
Pipeline

The pipeline object is the brains of kedro. When working with kedro you simply define functions that take in data as arguments, manipulate it, and return a new dataset. The pipeline will decide what order to execute these functions ini based on their dependencies. It will then work with the catalog to load the data from the catalog pass it to your function, the save the returned data in the catalog.
Here is an example pipeline from the docs.
import pandas as pd
import numpy as np
from kedro.pipeline import Pipeline
from kedro.pipeline import node
def clean_data(cars: pd.DataFrame,
boats: pd.DataFrame) -> Dict[str, pd.DataFrame]:
return dict(cars_df=cars.dropna(), boats_df=boats.dropna())
def halve_dataframe(data: pd.DataFrame) -> List[pd.DataFrame]:
return np.array_split(data, 2)
nodes = [
node(clean_data,
inputs=['cars2017', 'boats2017'],
outputs=dict(cars_df='clean_cars2017',
boats_df='clean_boats2017')),
node(halve_dataframe,
'clean_cars2017',
['train_cars2017', 'test_cars2017']),
node(halve_dataframe,
dict(data='clean_boats2017'),
['train_boats2017', 'test_boats2017'])
]
pipeline = Pipeline(nodes)
kedro-viz
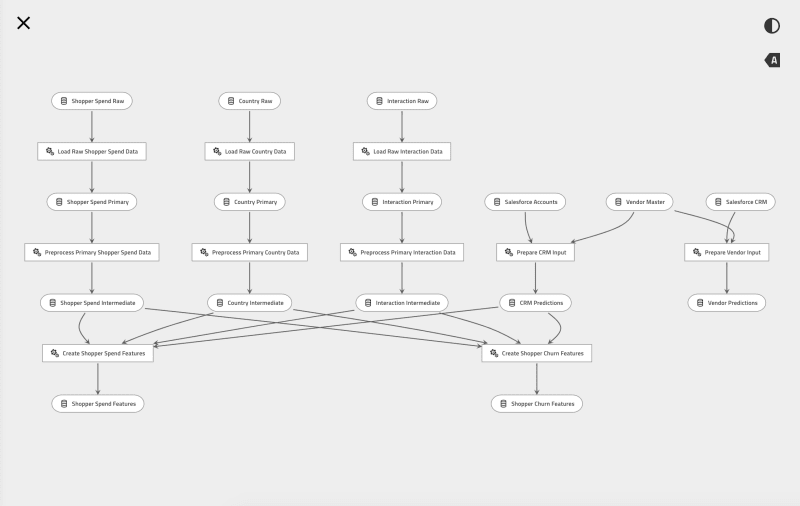
kedro-viz is a priceless component to the kedro ecosystem. It gives you x-ray vision into your project. You can see exactly how data flows through your pipeline. Since it is fully automated it is always up to date and never lies to you. kedro-viz is an integral part of my daily debugging and refactoring toolbelt.
Starting the viz from the command line is super easy
cd my-kedro-project
kedro viz
kedro-docker
kedro-docker is a simple way to set up your project for production. It provides a few simple cli commands
cd my-kedro-project
kedro docker build
kedro docker run
Other resources
The kedro docs have a ton of great resources. They are searchable, but can be a bit of an overwhelming amount of data.
I keep adding to my kedro notes as I find new and interesting things.
I tweet out most of those snippets as I add them, you can find them all here #kedrotips.
More to come
I am planning to do more articles like this, you can stay up to date with them by following me on dev.to, subscribing to my rss feed, or subscribe to my newsletter

Top comments (4)
We need more understanding on the data engineering aspect of things. We need more great content from you. Thank you very much
☺️ Thanks for the heartwarming comment. It made my day! DEV is not the traditional place for DS/DE content but it will get there, let's start shifting the tides!
Expect more to come, I already have a few kedro posts queued up!
Well i am here really here (dev.to) for the curiosity of SWE. I learn how to build simple CRUD / with authentification website with sinatra (ruby lightweight framework). In fact with my background i really do think DS and DE is much more suited for me. But i can find a good blogue with these kind of content about the Industry as a whole. I have try reddit but it’s like somebody’s is asking for question or advice.
That is the first time I heard about Kedro, your post made me really excited about more content to come. :)