
Author: Jacob Marks (Machine Learning Engineer at Voxel51)
Building a Better Bridge Between Images and Text
2024 is shaping up to be the year of multimodal machine learning. From real-time text-to-image models and open-world vocabulary models to multimodal large language models like GPT-4V and Gemini Pro Vision, AI is primed for an unprecedented array of interactive multimodal applications and experiences.
At the heart of many of 2023’s multimodal advances is a technique for bridging the gap between visual understanding and natural language understanding is a technique called contrastive language image pretraining (CLIP). Introduced by OpenAI in 2021, CLIP aligns a vision encoder and a text encoder so that the vision encoder’s representation of a photograph of a dog is similar to the text encoder’s representation of “a photo of a dog”. This turns out to be incredibly useful, both for zero-shot tasks and as a starting point (pretraining) for more specific, tailored applications.
While OpenAI’s CLIP model has garnered a lot of attention, it is far from the only game in town—and far from the best! On the OpenCLIP leaderboard, for instance, the largest and most capable CLIP model from OpenAI ranks just 41st(!) in its average zero-shot accuracy across 38 datasets.
In this post, we’re going to cover five of the most important data-centric advances in contrastive language-image pretraining:
- ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
- K-LITE: Learning Transferable Visual Models with External Knowledge
- OpenCLIP: Reproducible scaling laws for contrastive language-image learning
- MetaCLIP: Demystifying CLIP Data
- DFN: Data Filtering Networks
For a comprehensive catalog of papers pushing the state of CLIP models forward, check out this Awesome CLIP Papers Github repository. Additionally, the Zero-shot Prediction Plugin for FiftyOne allows you to apply any of the OpenCLIP-compatible models to your own data.
A Brief Review of OpenAI’s CLIP Model
(Github Repo | Most Popular Model | Paper | Project Page)
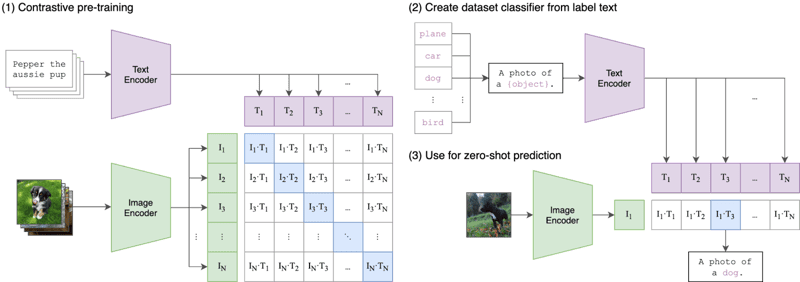
To understand CLIP, we need to deconstruct the acronym into its three constituent parts: (1) contrastive, (2) language-image, and (3) pretraining. Let’s start with the language-image part.
Language-Image
Machine learning models have traditionally been architected to accept input data from a single modality: text, images, tabular data, or audio. You would train a different model if you wanted to utilize a different modality to generate predictions. The “language-image” in CLIP refers to the fact that CLIP models accept inputs of two types: either text (language) or images.
CLIP processes these distinct inputs via two encoders—a text encoder and an image encoder. These encoders project the data into a lower-dimensional latent space, generating an embedding vector for each input. A crucial detail is that both the image and text encoders embed data in the same space—in the case of CLIP, a 512-dimensional vector space.
Contrastive
Embedding text and image data in the same vector space is a start, but on its own, it doesn’t guarantee that the model’s representations of text and images can be meaningfully compared. For example, it would be useful to have some reasonable and interpretable relationship between the text embedding for “a dog” or “a photo of a dog” and the image embedding for an image of a dog. We need a way to bridge the gap between the two modalities.
In multimodal ML there are various techniques for aligning two modalities, but perhaps the most popular approach today is contrastive. Contrastive techniques take paired inputs from two modalities — think an image and its caption — and train the model’s two encoders to represent these pairs as closely as possible. At the same time, the model is incentivized to take unpaired inputs (such as an image of a dog and the text “a photo of a car”) and represent them as far away as possible. CLIP was not the first contrastive learning technique for images and text, but its simplicity and effectiveness have made it a mainstay in multimodal applications.
Pretraining
While CLIP on its own is useful for applications such as zero-shot classification, semantic searches, and unsupervised data exploration, CLIP is also used as a building block in a vast array of multimodal applications, from Stable Diffusion and DALL-E to StyleCLIP and OWL-ViT. For most of these downstream applications, the initial CLIP model is regarded as a “pre-trained” starting point, and the entire model is fine-tuned for its new use case.
CLIP Training Data
While OpenAI has never explicitly specified or shared the data used to train the original CLIP model, the CLIP paper mentions that the model was trained on 400 million image-text pairs collected from the Internet.
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision

With CLIP, OpenAI utilized 400 million image-text pairs. Without explicit details from the authors, knowing exactly how they constructed the dataset is impossible. However, in describing the novel dataset, they reference Google’s Conceptual Captions (GCC) as an inspiration — a relatively small dataset (3.3 million image-description pairs) that leveraged expensive filtering and post-processing techniques. These techniques are powerful, but not particularly scalable.
Published shortly after CLIP, A Large-scale Ima*Ge and **N*oisy-text embedding (ALIGN) aims to overcome this bottleneck by trading filtering for scale. Rather than relying on small, painstakingly annotated, and curated image captioning datasets, ALIGN leverages 1.8 billion pairs of images and alt-text.
While these alt-text descriptions are far noisier on average than captions, the sheer scale of the dataset more than compensates. The authors apply basic filtering to remove duplicates, images with 1000+ associated alt-texts, and uninformative alt-texts (either too common or containing rare tokens) but steer clear of expensive filtering operations. With just these simple steps, ALIGN matches or surpasses the state-of-the-art on various zero-shot and fine-tuned tasks.
K-LITE: Learning Transferable Visual Models with External Knowledge
(Github Repo | Paper)

Like ALIGN, K-LITE confronts a considerable challenge: the limited quantity of high-quality image-text pairs for contrastive pretraining. Rather than turn to alt-text and trade noise for scale, Knowledge-augmented Language Image Training and Evaluation (K-LITE) leverages massive pre-existing text datasets to augment multimodal datasets of image-caption pairs.
K-LITE hones in on the intuitive notion that including definitions or descriptions as context along with unknown concepts can help develop generalized understanding. This is why people often briefly define technical terms and uncommon words inline when they first introduce them! Check out the image above for an example.
To operationalize this intuition, the Microsoft and UC Berkeley researchers use WordNet and Wiktionary to augment the text in image-text pairs. The concept itself is augmented for isolated concepts, such as the class labels in ImageNet, whereas for captions (such as from GCC), the least common noun phrase is augmented. Equipped with this additional structured knowledge, contrastively pretrained models exhibit substantial improvement on transfer learning tasks.
OpenCLIP: Reproducible scaling laws for contrastive language-image learning
(Github Repo | Paper)
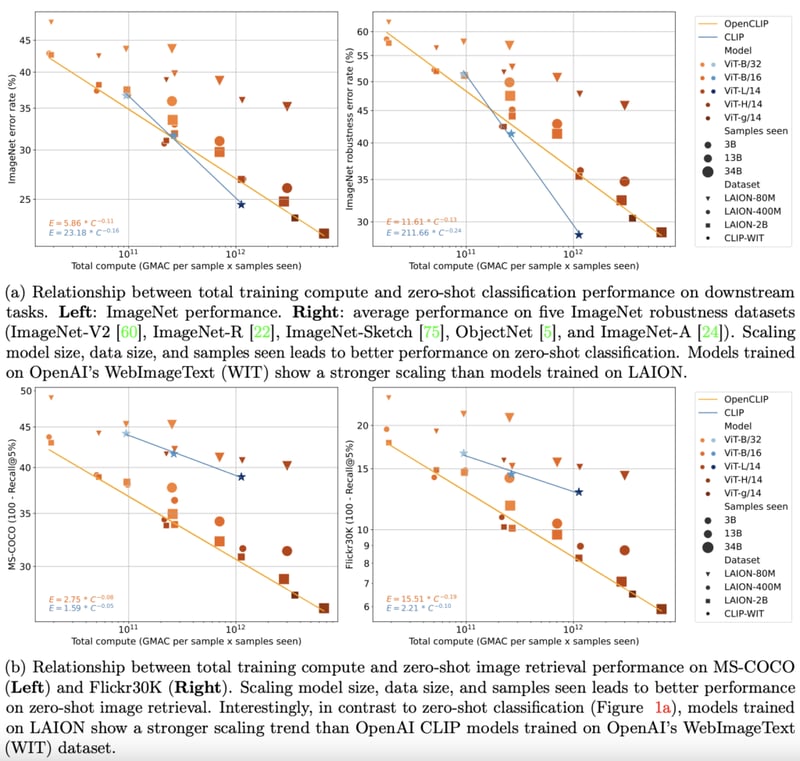
By late 2022, transformer models had become established in the text and vision (vision transformer) domains. Pioneering empirical works in both domains also made it clear that the performance of transformer models on unimodal tasks could be described remarkably well by simple scaling laws. In other words, one could predict with decent accuracy how well a model would perform as the amount of training data, training time, or model size was increased.
OpenCLIP extended this investigation to multimodal scenarios by using the largest ever released open-source dataset of image-text pairs (5B) to systematically study the effects of training data on model performance on both zero-shot and fine-tuning tasks. As in the unimodal cases, the study revealed model performance on multimodal tasks scaled as a power law in compute, samples seen, and number of model parameters.
More interesting than the presence of power laws was the observed relationship between power law scaling and pre-training data. Retaining OpenAI’s CLIP model architecture and training recipe, OpenCLIP models exhibited stronger scaling on zero-shot image retrieval tasks. For zero-shot image classification on ImageNet, OpenAI’s models (trained on their proprietary dataset) exhibited stronger scaling. These findings highlighted the importance of data collection and filtering procedures for downstream performance.
⚠️The LAION datasets have been taken down from the internet for containing illicit imagery
MetaCLIP: Demystifying CLIP Data
(Github Repo | Most Popular Model | Paper)
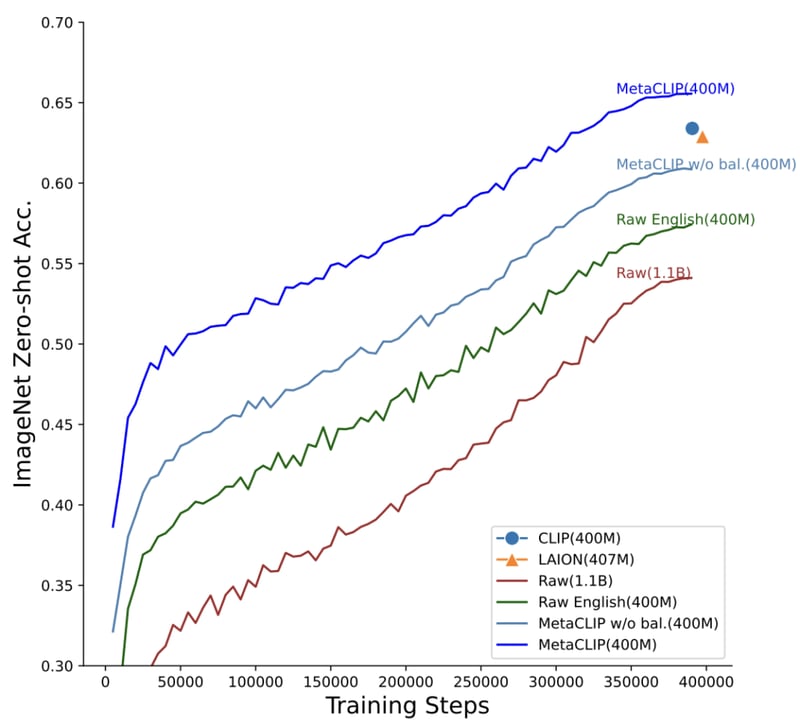
Whereas OpenCLIP sought to understand how downstream tasks' performance scales with the amount of data, compute, and number of model parameters, MetaCLIP focuses on how the data is chosen. As the authors put it, “We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective.”
To test this hypothesis, the team of researchers fixed model architecture and training regimes and ran experiments to uncover the data curation methodology used by OpenAI in training their original CLIP model. The MetaCLIP team tested multiple strategies relating to sub-string matching, filtering, and balancing the data distribution to mitigate noise, and found that optimal performance was achieved when each text was limited to at most 20,000 occurrences in the training dataset — even the word photo, which occurred 54M times in the initial data pool, was limited to 20,000 image-text pairs in the training data. With this strategy, MetaCLIP trained on 400M image-text pairs from the Common Crawl dataset outperformed OpenAI’s CLIP model on various benchmarks.
DFN: Data Filtering Networks
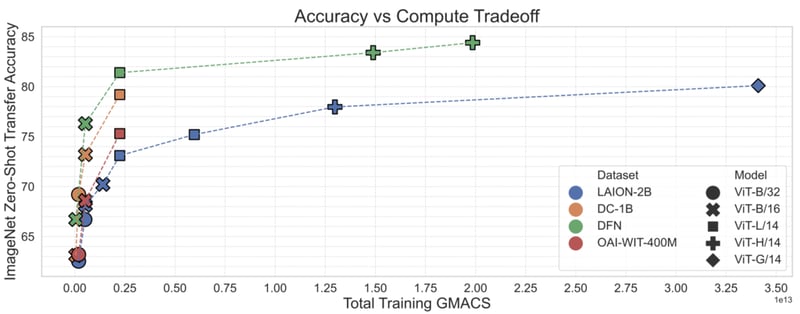
With MetaCLIP, it became clear that data curation was perhaps the most important ingredient for training highly performant multimodal models like CLIP. MetaCLIP’s filtering strategy was remarkably successful, but it was also based largely on heuristics. In Data Filtering Networks, researchers asked whether or not they could train a model to do this filtering more effectively.
To test this, the researchers used high-quality data from Conceptual 12M to train a CLIP model to filter high-quality from low-quality data. This data filtering network (DFN) was then used to build a much larger set of high-quality data by selecting only the high-quality data from an uncurated dataset—in this case, Common Crawl. The resulting CLIP model trained on the filtered data outperformed models trained on just the initial high-quality data and models trained on the massive unfiltered data.
I’ll leave you with these quotes from the paper, which are pretty telling:
- “We find that data quality is key to training good filtering models.”
- “Once the filtering training pool is poisoned, the dataset induced by the DFN is only slightly better than unfiltered data.”
- “Creating better datasets not only improves model performance, but also improves model efficiency”
- “By training a DFN instead of directly training on high-quality data, we demonstrate a successful recipe for leveraging high-quality data for creating large-scale high-quality datasets.”
Conclusion
OpenAI’s CLIP model has markedly transformed how we work with multimodal data. But in many ways, CLIP was just the beginning. From the pre-training data to the training recipe and the particulars of the contrastive loss function, incredible progress has been made within the CLIP family over the past few years.





Top comments (0)