
You've probably used whatever text to speech tool at least once. So in this post, We'll create your own text-to-speech tool with an audio exporting feature using Python.
Basically, We'll use IBM Watson Text to Speech Machine learning model. IBM Watson helping enterprises put AI to work and helps organizations predict future outcomes, automate complex processes, and optimize employees’ time.
Register with IBM Cloud
To Getting started with the Text to Speech model, You have to register with IBM Cloud. Go to IBM Cloud and create a new free account.
After that, you have to create lite plan instances of the model. To create that, go to the Text to Speech model page and then create a free instance by clicking Create button.
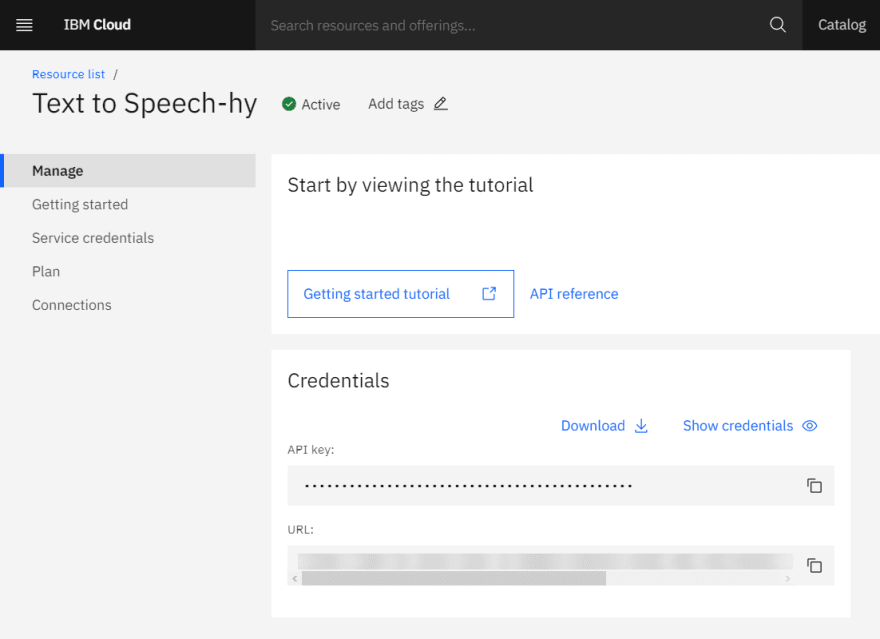
Afterward, you'll see the getting started page. Go to the Manage page to get model credentials which are API key and URL. Now registration process is completed.
Usage
First, have to install the ibm_watson on your computer.
pip install ibm_watson
If you are using Jupyter Notebook, add an exclamation mark before the command to act as if it is executed in the terminal.
!pip install ibm_watson
Authenticate
Import TextToSpeech model, Watson authenticator and authenticate with API key and the URL.
from ibm_watson import TextToSpeechV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
Specify the API Key and URL
url = '<your-api-url>'
apiKey = '<your-api-key>'
authenticator = IAMAuthenticator(apiKey)
tts = TextToSpeechV1(authenticator=authenticator)
tts.set_service_url(url)
Setup Text to Speech
In this step, we'll look at how to speak a text from string and text files.
From String
with open('./speech.mp3', 'wb') as audio_file:
res = tts.synthesize('Hello World! I\'m Thirasha', accept='audio/mp3', voice='en-US_AllisonV3Voice').get_result()
audio_file.write(res.content)
In a while, it will generate that string to an audio file and export it as speech.mp3 at the root directory.
From Text File
with open('SpeechText.txt', 'r') as f:
text = f.readlines()
Remove line breaks
text = [line.replace('\n', '') for line in text]
text = ''.join(str(line) for line in text)
Export audio file
with open('./speech.mp3', 'wb') as audio_file:
res = tts.synthesize(text, accept='audio/mp3', voice='en-US_AllisonV3Voice').get_result()
audio_file.write(res.content)
Change Language and Voice (Optional)
If you want to change the voice or language, refer to this IBM Languages and Voices documentation.
For example, If I have chosen the German female voice de-DE_BirgitV3Voice, that code should be change like this.
with open('./germanspeech.mp3', 'wb') as audio_file:
res = tts.synthesize('Hallo Welt! Ich bin Thirasha', accept='audio/mp3', voice='de-DE_BirgitV3Voice').get_result()
audio_file.write(res.content)
Eventually, You have created your own Speech-To-Text generating tool!🎉

Top comments (0)