
I originally posted this on Starburst's blog, as part of a series I've been publishing on Iceberg.
Schema evolution simply means the modification of tables as business rules and source systems are modified over time. Trino’s Iceberg connector supports different modifications to tables, including changing the table name itself, as well as, column and partition changes.
Much like a database, you perform “alters” to Iceberg tables to modify their structure. Since Iceberg is just a table format which contains metadata about a table, modifying the table is rather trivial.
Table Changes
Rename a table
alter table customer_iceberg rename to customer_iceberg_new;
Note: This is a change to the table name in the metastore and no changes will be made in the storage. So, the location s3:///customer_iceberg will remain the same.
Column Changes
Adding a column:
alter table customer_iceberg add column tier varchar(1);
Rename a column:
alter table customer_iceberg rename column address to fulladdress;
Partition Changes
Oftentimes a table is initially partitioned by a column or set of columns, only later it’s discovered this may not be optimal. With Iceberg, you can modify the partition columns at any time.
For example, initially this table is partitioned by month:
create table orders_iceberg
with (partitioning=ARRAY['month(orderdate)']) as
select * from tpch.sf1.orders;
After reviewing query a patterns, it’s determined that partitioning by day would perform better as a majority of queries are filter by certain days. A simple alter table statement as seen below will modify the partitioning on this table from month to day:
alter table orders_iceberg SET PROPERTIES partitioning = ARRAY['day(orderdate)'];
After new data is inserted into the table, you will see a change in the data directory where the table data is stored:
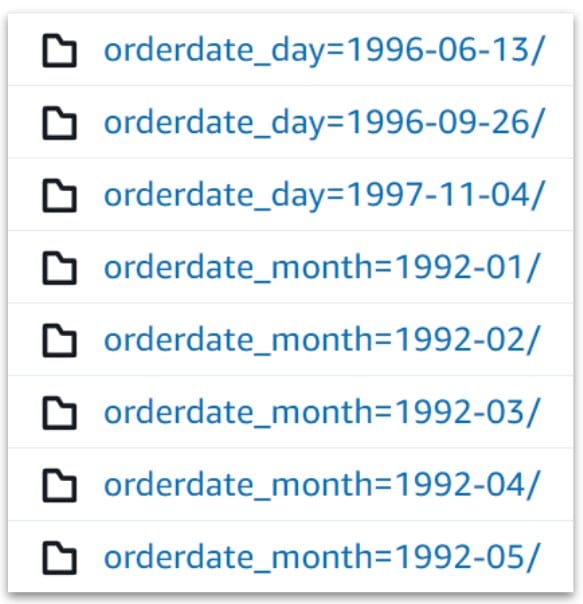
Notice the orderdate_month is now orderdate_day. Note that queries that filter by day will partition prune at the partition day level but the existing monthly partitions will still need to be searched. If you would like to have the entire table partitioned by day then you could recreate the table using a CTAS (create table as) from the existing table.
Example to create a new table partitioned by day from the existing table:
create table orders_iceberg_new with (partitioning=ARRAY['day(orderdate)']) (as select * from orders_iceberg)
Schema evolution in Trino’s Iceberg connector is very powerful and easy to use. These types of functions were not available in Hive and database veterans will be very happy to see them added to the data lake landscape.

Top comments (0)