
I originally posted this on Starburst's blog, as part of a series I've been publishing on Iceberg.
Partitioning
Partitioning is used to narrow down the scope of the data that needs to be read for a query. When dealing with big data, this can be crucial for performance and can be the difference between getting a query that takes minutes or even hours down to seconds!
One of the advantages of Apache Iceberg is how it handles partitions. One of the biggest drawbacks from using Hive based tables was the method on how you had to partition your data.

For example, most tables that you would plan to partition have some sort of date or timestamp that indicates when the row of data was created. Example table:

For Hive, if you wanted to partition by day, you would have to break out the created_ts column into year, month and day. Then, you would have to teach your users to always include these columns in their queries even if they wanted to query on created_ts.
create table hive.orders (event_id, integer, created_ts timestamp, metric integer, year varchar, month varchar, day varchar);
With Iceberg, you simply partition the data on created_ts using day and end users would query this table just like they would in a database. Here is an example:
-- create iceberg table partitioned by day on the created_ts column
create table orders_iceberg
(event_id integer, created_ts timestamp(6),metric integer)
with (type='iceberg',partitioning=ARRAY['day(created_ts)']);
-- insert rows
insert into orders_iceberg values (1,timestamp '2022-09-10 10:45:38.527000',5.5);
insert into orders_iceberg values (1,timestamp '2022-09-11 03:12:23.522000',5.5);
insert into orders_iceberg values (1,timestamp '2022-09-12 10:46:13.516000',5.5);
insert into orders_iceberg values (1,timestamp '2022-09-13 04:34:05.577000',5.5);
insert into orders_iceberg values (1,timestamp '2022-09-14 09:10:23.517000',5.5);
-- query the table only looking for certain days
select * from orders_iceberg where created_ts BETWEEN date '2022-09-10' AND date '2022-09-12';
The data in S3 for example looks like this:
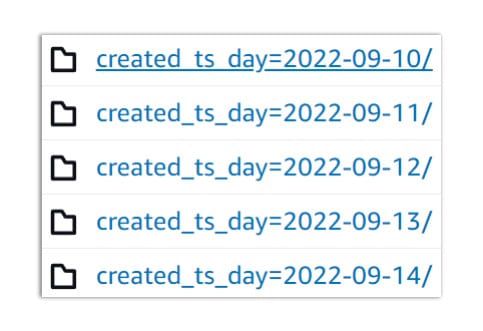
Trino is smart enough to read the Iceberg Manifest List and then only look at files that meet the partition requirement of the query. In the example above, it would only be 2022-09-10 and 2022-09-11. A list of functions to partition by can be found here.
Note: Trino’s Iceberg implementation includes the timezone for the timestamp data type (timestamp(6)). This was a conscious decision based on industry standard of supporting timezones within timestamp data types that Hive didn’t support.
Although we’ll cover this in a separate schema evolution blog, you aren’t stuck with this partitioning scheme. At any time, you can modify your partition column. For example, if we decided that partitioning on day is too granular, we can modify the table to now be partitioned by month:
alter table orders_iceberg SET PROPERTIES partitioning = ARRAY['month(created_ts)'];
New data will be created in directories named: created_ts_month=2022-09 for example. The existing data will remain partitioned by day unless the table is recreated.
Performance and Optimizations
When it comes to performance, Iceberg can be a very performant table format. This is because metadata is stored about all of the files that “belong” to a table for a given snapshot in time along with statistics about each one which helps with “file skipping”. This is a fancy term for files that do not need to be read based on the query that is issued.
With partitioning, the field of files is narrowed down even further by first only looking at the metadata for files after partition pruning is completed then looking at the metadata of the remaining files. When data is ordered by columns that appear in a where clause, this can greatly improve the performance of selective queries.
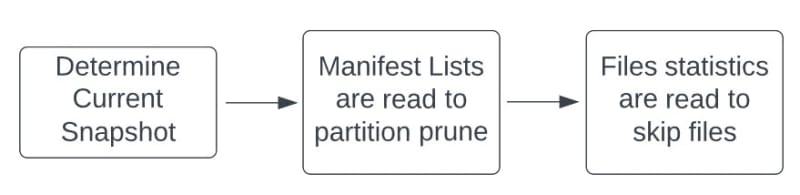
The manifest file contains information about the different files that belong to the table. Each entry has the location of the file in addition to statistics such as the minimum and maximum value for each column, the number of nulls and other useful information. Trino will use this metadata about each file to determine if the file needs to be read. If the data is sorted by “id” and a where clause has predicate similar to: where id = 5 then this query will see a large performance improvement because only a handful of files (if not just one) will need to be read.
Optimizing for performance
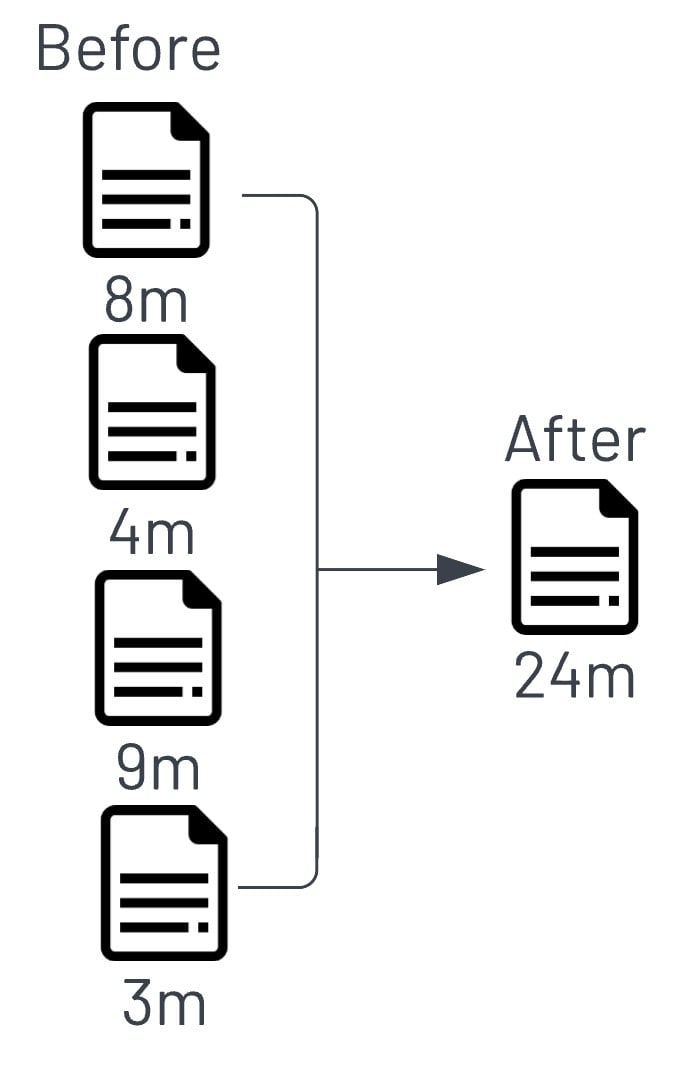
Iceberg includes some file management features that help with performance. Traditional data lakes have use cases where there is constant data being ingested. This data is written in small files because of the need to have it available to be queried immediately. This can hurt performance in any system that needs to read a bunch of small files especially in cloud storage. Iceberg includes an optimize feature that combines small files into larger ones ensuring maximum performance when it comes to querying.
The idea here is you want to ingest data as fast as possible, making it available for queries even though it might not be of the highest performance, then offer the ability to combine those files into larger ones at a given interval.
To scan the table for small files and make them larger, you simply issue the following command:
alter table <table> execute optimize;
This will look for any files under 100MB and combine them into larger ones. You can also choose the file size of 100MB:
ALTER TABLE <table> EXECUTE optimize(file_size_threshold => '10MB')
If your Iceberg table becomes very large and the optimize command above is taking too long to run, you can just optimize the files that have arrived recently:
ALTER TABLE <table> EXECUTE optimize where "$file_modified_time" > current_date - interval '1' day;
This will look for files that have arrived since yesterday and optimize them. On a very active table where lots of changes are taking place, this will greatly reduce the amount of time the optimize command takes.
Example:
Network events are streamed in 1 minute intervals. Small files are dropped into an S3 bucket using the Iceberg API and the data is available immediately using standard SQL. Based on the volume of data and the files created, the optimize command can be run at given intervals to consolidate these smaller files into larger ones. This will greatly improve the performance of of subsequent queries against this table.
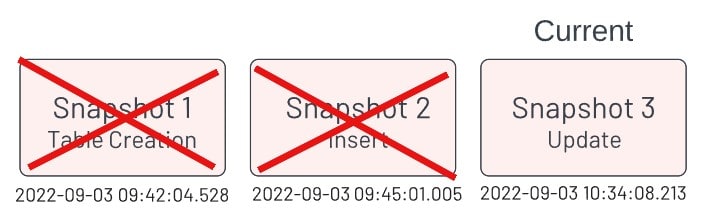
Cleaning up snapshots
From time to time, older snapshots of tables should be cleaned up. These older snapshots contain previous states of the table which are no longer needed.
There are two operations that clean up old snapshots and data. One is “expire_snapshots” and the other is “remove_orphan_files.
expire_snapshots
This function removes snapshots that are older than the value provided during the execution. An example is the below command that will remove snapshots that are older than 7 days:
ALTER TABLE <table> EXECUTE expire_snapshots(retention_threshold => ‘7d’)
[remove_orphan_files](https://trino.io/docs/current/connector/iceberg.html#remove-orphan-files)
This function removes files that are left on storage when a query is unable to complete for a variety of reasons. This doesn’t happen too often but it’s a good idea to include this when you run snapshot cleanups. A similar alter table statement is used as shown in the this example:
ALTER TABLE test_table EXECUTE remove_orphan_files(retention_threshold => ‘7d’)
As you can see, Iceberg + Trino brings some very exciting features along with tremendous performance advantages to complete your modern data lake.

Top comments (0)