
Bridging the gap between Application Developers and Data Scientists, the demand for Data Engineers rose up to 50% in 2020, especially due to increase in investments on AI based SaaS products.
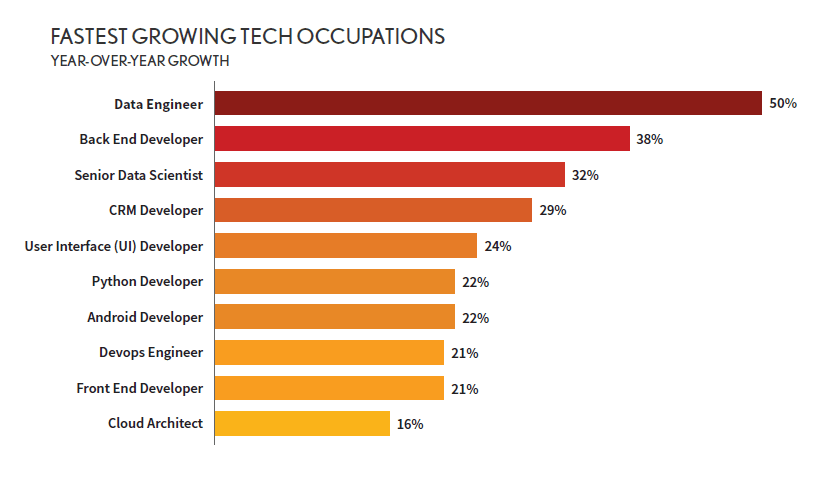
After going through multiple Job Descriptions and based on my experience in the field , I have come up with the detailed skill sets to become a competent Data Engineer.
If you are a Backend Developer, some of your skills will overlap with this list below. Yes, it's quite easier for you to make the jump provided the skill gaps are addressed.
🎯 Must Haves
1️⃣ The Art of Scripting and Automating
Can't stress this enough.
Ability to Write a reusable code and to know the Common Libraries and frameworks used in Python for:
* Data Wrangling operations - Pandas,numpy,re
* Data Scraping - requests/BeautifulSoup/lxml/Scrapy
* Interacting with External APIs and other Data Sources, Logging
* Parallel processing Libraries - Dask, Multiprocessing
2️⃣ Cloud Computing Platforms
The rise of cloud storage and computing has changed a lot for data engineers. So much that, being well versed in at least one of the cloud platforms is required.
*Serverless Computing, Virtual Instances, Managed Docker and Kubernetes Services
* Security Standards, User Authentication and Authorization, Virtual Private Cloud, Subnet
3️⃣ Linux OS
Importance of Working with Linux OS is often overlooked.
"90% of the public cloud workloads are running on Linux based OS"
* Bash Scripting concepts in Linux like control flow, looping, passing input parameters
* File System Commands
* Running daemon processes
4️⃣ Database Management - Relational Databases, OLAP vs OLTP, NoSQL
* Creating tables, Read,Write,Update and Delete operations, joins, procedures, materialized views, aggrgated views, window functions
* Database vs Data warehouse. Star and snowflake schemas, facts and dimension tables.
- Common Relational Databases preferred - PostgreSQL, MySQL etc
5️⃣ Distributed Data Storage Systems
* Knowledge of how distributed data store works.
* Understanding the Concepts like partitioned data storage, sorting key, SerDes, data replication, caching and persistence.
- Some of the mostly used ones - HDFS, AWS S3 or any other NoSQL database (MongoDB, DynamoDB,Cassandra)
6️⃣ Distributed Data Processing Systems
* Common techniques and patterns for data processing such as partitioning, predicate pushdown, sort by partition, maintaining size of shuffle blocks, window function
* Leveraging all cores and memory available in the cluster to improve concurrency.
- Common Distributed processing frameworks - Map Reduce, Apache Spark (Start with Pyspark if you are already comfortable with Python) Credits : startdataengineering 7️⃣ ETL/ELT tools and Modern Workflow management Frameworks Different companies will have different ways to pick ETL frameworks, One with an In-house data engineering team would prefer to have ETL jobs set up with properly managed workflow management tools for Batch Processing.
- ETL - ETL vs ELT, Data connectivity, Mapping, Metadata, Types of Data Loading
When to use a Workflow Management System - Directed Acyclic graphs, CRON scheduling, Operators
ETL Tools: Informatica, Talend
Workfow Management Frameworks: Airflow, Luigi
🎯Good To Have
8️⃣ JAVA / JVM Based Frameworks
Knowledge of a JVM based language such as Java or Scala will be extremely useful
- Understand both functional and object oriented programming concepts
- Many of the high performance data science frameworks that are built on top of Hadoop usually are written using Scala or Java.
- JVM Based Frameworks - Apache Spark, Apache Flink, etc
9️⃣ Message Queuing Systems
* Understanding how data injestion happens in Message Queues
* What are Producer and Consumers and how are they implemented
* Sharding, Data Retention, Replay, de-duplication
- Popular Messaging queues: Kafka,RabbitMQ, Kinesis, SQS etc
🔟 Stream Data Processing
*Differentiating between Real-time, Stream and Batch Processing.
*Sharding, Repartioning, Poll Wait time, topics/groups,brokers
- Commonly used frameworks: AWS Kinesis Streams,Apache Spark,Storm,Samza etc
If you find any other skill that will be helpful, comment below on the post.
Going forward, I'll publish detailed posts on tools and frameworks used by Data Engineers day in and day out.

Follow for updates.





Top comments (4)
Hi Srinidhi,
It seems like some of the sections, in your article (dated May 19th 2020) are exact copies of the article at
dev.to/start_data_engineering/10-k..., published on May 11th and never edited
which I posted my blog at startdataengineering.com/post/10-k... on March 20th 2020
Sections that are exact or subset copies:
SQL -> "Database Management - Relational Databases, OLAP vs OLTP, NoSQL"
Distributed Data Storage -> "Distributed Data Storage Systems"
Distributed Data processing -> "Distributed Data processing Systems"
Stream processing -> "Stream Data Processing"
ref:



Also I noticed you cross posted this on medium at
medium.com/@srinidhi.s96/data-engi...
I am totally fine with someone using my content but please at least link back to my article, I put a lot of research and work into this. And please be aware that this is against dev.to policy, medium's policy and a broader DMCA copyright policy. Hope you take this into consideration. Please let me know if you have any questions. Best wishes.
Interesting topics! Looking forward to it :) !
Good job on the post. I'll definitely refer back to that must haves list in the future! 👍🏻
Thanks Adron
Some comments have been hidden by the post's author - find out more