
Today, chatbots are at the forefront of every organization. Due to the exponential increase in industry-scale Large Language Models (LLMs), chatbots have evolved rapidly. AI agents like ChatGPT, which are built on LLM-based models, excel at answering questions on a wide variety of tasks. However, they still struggle with analyzing large data points. In today’s data-centric society, almost all firms and individuals rely on the analysis of huge datasets to extract insightful information.
In this article, we will develop a chatbot-like system designed to interact with large CSV files. Our exploration will include an impressive tech stack that incorporates a vector database, Langchain, and OpenAI models. Langchain, with its ability to seamlessly integrate information retrieval and support third-party LLMs and Vector DBs, provides a potent conversational interface for querying information from CSV databases. This chat interface allows for the uploading of any CSV data, enabling analysts to pose questions in a human-readable format and receive answers. While we use a sales record as an example here, the system is compatible with any CSV-formatted data. This approach can significantly save time for data analysts when analyzing data. Moreover, it opens up possibilities for extracting further information from raw data by facilitating dialogues with the CSV content.
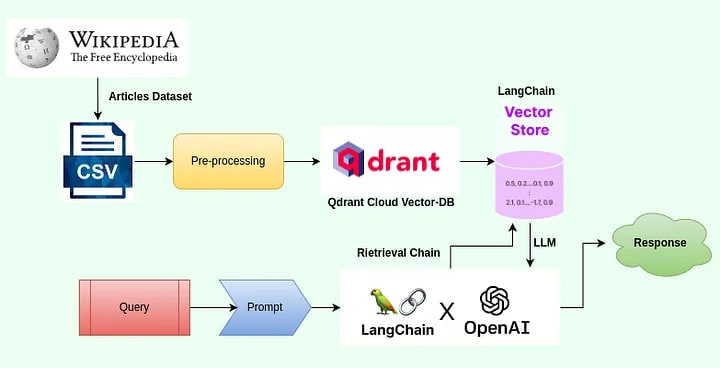
Before we delve into the use of the OpenAI API and Langchain’s retrieval API, let’s take a moment to explore Qdrant, our chosen vector database. Qdrant is an open-source alternative to Pinecone and offers a complimentary service for testing some of our model deployments.
Qdrant Vector Database: A High-Performance Vector Similarity Search Technology

Vector databases have recently gained significant popularity. They store and index vector embeddings to enable fast retrieval and similarity search. Qdrant provides an API service that facilitates the search for the closest high-dimensional vectors. As an excellent open-source alternative to Pinecone, it offers an easy-to-use API and a nearest-neighbor search with state-of-the-art speed. Unlike Elasticsearch’s post-filtering, Qdrant supports and allows filtering results based on additional payload associated with vectors.
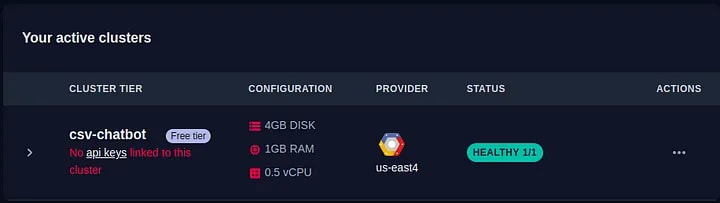
Now, let’s start building a cloud vector database as a cluster on the Qdrant cloud. First, we will create a free-tier cloud cluster for our experimental purposes. You can adjust the configuration for specific use cases and requirements as described below:

Once the status of the cluster is flagged ‘healthy 1/1’, we can create an API key to access the cluster within the application.
Now you can get the API key from the overview (save it !) — and we have our Build Features right away to get started.

We have a URL that we are going to use to send requests and interact with the cluster:
https://eeaa3ee2-e210-4aa4-a0aa-e0e471b2b7ff.us-east4-0.gcp.cloud.qdrant.io:6333
In this article, we will use Thunder Client, which is an HTTP client for VS Code. Thunder is a lightweight and easy-to-use Rest Client for Testing APIs; it is available as a flexible extension in VS Code.
In Qdrant, we recently established a Cluster. A Cluster can encompass several Collections, which can be viewed as databases. Each Collection may contain one or more points, where each point represents a Vector. A Vector is essentially a numerical representation of our text. When we embed our text and send it to a database, it stores the text Vector as a point within the specified Collection. To determine the number of collections in the cluster, we can use a GET request via Thunder. We will execute this using the following GET request.
GET https://eeaa3ee2-e210-4aa4-a0aa-e0e471b2b7ff.us-east4-0.gcp.cloud.qdrant.io:6333
Once we add the API key to the HTTP Headers, we can issue a GET request to verify the status of our Qdrant client. By appending the collections endpoint, we can further extend this functionality.
Now, let’s delve into the process of creating a client in Python to interact with our host. This includes creating a collection and adding points, or vectors, to that collection in our cluster. Additionally, if you’re interested in learning how to monitor the collection using the Thunder client, I recommend referring to my previous article on the topic here.
Installing Dependencies
We will need the following dependencies for the project; here, we have listed the whole list in one go so that we can leverage the functional classes later on.
!pip install -q -U torch
!pip install -q -U kaggle
!pip install -q -U wget
!pip install -q -U openai
!pip install -q -U langchain
!pip install qdrant-clientpyp
Importing the Dependencies
import os
import wget
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import CSVLoader
from langchain.indexes import VectorIndexCreator
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
import torch
from qdrant_client import QdrantClient
from qdrant_client.http import models
import getpass
device = 'cuda' if torch.cuda.is_available() else 'cpu'
Set-Up API Keys and Qdrant Client
After importing the necessary libraries, let’s get an OpenAI key from here.Let’s prepare our OpenAI API key:
! export OPENAI_API_KEY=” your API Key”
Now let’s first create a Qdrant client object, which will allow us to connect to our cluster and create collections.
from qdrant_client import QdrantClient
qdrant_client = QdrantClient( url="https://eeaa3ee2-e210-4aa4-a0aa-e0e471b2b7ff.us-east4-0.gcp.cloud.qdrant.io:6333",
api_key="tDQpm--EuWtRKV7I0B_xH0jKhtmgltBIiOlG_bDW5LBeN2rnxleHVQ",
)
Using get_collections() method we can see existing collections in our Cluster/Qdrant client.

As we do not have any collections, this outputs an empty list of collections.So, right away, let’s create a new collection named ‘csv-collection’.
os.environ["QDRANT_COLLECTION_NAME"] = "csv-collection"
vectors_config = models.VectorParams(size=768, distance=models.Distance.COSINE)
qdrant_client.create_collection(
collection_name=os.getenv("QDRANT_COLLECTION_NAME"),
vectors_config= vectors_config,
)
The above Python script initiates a vector configuration for Qdrant, specifying that the vectors should be of a size 768 and defining the distance metric for comparisons as the cosine distance.
This configuration sets up the characteristics of vectors that will be used within the Qdrant system, determining their size and the specific metric used to measure the distance or similarity between vectors.
Now that we have created our collection, we need some embeddings to store in our vector database. Later on, we will use the integrations with Langchain that is provided in the Qdrant documentation to retrieve the embeddings from the cloud vector store.
Looking at the Data: The Wikipedia Articles
In this section, we will load the data from OpenAI API examples that provide pre-computed embeddings of Wikipedia articles. You can download and extract the data files using the below script:
import wget
import zipfile
embeddings_url = "https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip"
wget.download(embeddings_url)
with zipfile.ZipFile("vector_database_wikipedia_articles_embedded.zip","r") as zip_ref:
zip_ref.extractall("../data")
Let’s have a look at the provided CSV file using Pandas.
import pandas as pd
from ast import literal_eval
article_df = pd.read_csv('../data/vector_database_wikipedia_articles_embedded.csv')
# Read vectors from strings back into a list
article_df["title_vector"] = article_df.title_vector.apply(literal_eval)
article_df["content_vector"]=article_df.content_vector.apply(literal_eval)
article_df.head()

Index Data
As previously mentioned, Qdrant organizes data into collections, with each object being characterized by at least one vector and potentially additional metadata, known as payload. We have set up our collection under the name ‘CSV-Collection,’ where each object is represented by vectors from both the title and the content. Our approach involves populating the collection with points without predefining any schema.
from qdrant_client.http import models as rest
vector_size = len(article_df["content_vector"][0])
qdrant_client.recreate_collection(
collection_name="csv-collection",
vectors_config={
"title": rest.VectorParams(
distance=rest.Distance.COSINE,
size=vector_size,
),
"content": rest.VectorParams(
distance=rest.Distance.COSINE,
size=vector_size,
),
}
)
Next we will upsert the vector payload into our collection using the following script:
qdrant_client.upsert(
collection_name="csv-collection",
points=[
rest.PointStruct(
id=k,
vector={
"title": v["title_vector"],
"content": v["content_vector"],
},
payload=v.to_dict(),
)
for k, v in article_df.iterrows()
],
)
Now, as our collection has the embeddings and the client, we will integrate the Qdrant class derived from Langchain vector stores. To begin, we’ll use the Thunder client to check the status of our collection, confirming that the embeddings have been successfully added.
Langchain-Qdrant Integration
We will create a vector store object using the Qdrant class from Langchain. This process requires an embedding model. In this case, we will utilize the OpenAI Embeddings model, which is designed for text-to-embedding generation with a dimension of 1536.
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
text:str
embedded_query = embeddings_model.embed_query(text)
vector_store = Qdrant(
client=client,
collection_name="csv-collection",
embeddings=embeddings,
)
We now possess a persistent vector store in the cloud, accessible from any application at our disposal. As long as we maintain the necessary credentials, there’s no need to recreate the embeddings. Let’s proceed by connecting this vector store to our application and begin using it for querying in the QA task.
Chatting on CSV Data with OpenAI
First, we will establish a QA chain using Langchain. This QA chain will be designed to retrieve information from our vector database and feed it into a language model, enabling us to chat with that information.
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
llm=OpenAI()
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vector_store.as_retriever())
Now that we have our chain established, we can use it to query the vector database. Let’s test this on a few of the questions and responses the QA chain provides.
query = "Provide top-ranked articles with modern art in Europe"
response = qa({"question": query})
print(response['result'])
- Museum of Modern Art
- We Western Europe
- Renaissance art
query = "Find articles related to Famous battles in Scottish history"
response = chain({"question": query})
print(response['result'])
Sure, Here are related articles to Famous battles in Scottish history Battle of Bannockburn, Wars of Scottish Independence, First War of Scottish Independence.
Hurray! We have successfully developed a chatbot capable of processing large CSV datasets for question-answering tasks. I hope this journey has been enlightening, particularly in understanding vector databases, LangChain, and OpenAI. Keep an eye out for more exciting blog posts.
Follow me on Twitter: @sidgraph
(Note: This blogpost is in collaboration with Superteams.ai.)





Top comments (0)