
This is the second installment of my initial dive into System Design as prep for an interview for a Production Engineer. If you are new to System Design and didn't read the first blog post, I recommend it!
NOTE: Please use this as a starting point to learn about System Design, as I am super new to System Design and may be using some terminology loosely! I provide some resources at the bottom of this blog as references to dive deeper!
If you want to skip straight to the technical stuff, scroll down to the Expanding On The Fundamentals - High Level Design.
Why System Design Matters?
Whenever I'm learning something new, I always try to figure out its practical relevance to my life.

System Design has both practical and technical relevance:
Practical Relevance
In my day-to-day, I constantly use software-based services (Netflix, Shutter, even LinkedIn). I also have experienced the frustration of having those services "go down" or be unavailable for some periods of time. These services rely on good system design (the structure) as well great UI (the look) to keep customers like myself coming back and using them. Understanding System Design makes me really appreciate the deliberate decisions taken by system engineers to make sure I can enjoy the services I use and rely on day to day.
Technical Relevance
As a fullstack developer, learning basic System Design changed the way I approach project planning. Here was my current design flow:
1) "I'll plan a project" -> I create my user stories, mockups, models
2) "I will implement the project with tools that I'm familiar with" -> I usually end up picking React for the front end, and pick a REST or GraphQL style backend arbitrarily, etc.
That sounds fine, what's the problem? The problem is that I am trying to fit my project AROUND tools. The tools I'm using may not be the best fit based on my project.
This is the equivalent of saying:
1) "I need to hang up a picture frame"
2) "Well, in my toolbox I've got a sledgehammer and sandpaper... I'll make it work!"
3) You proceed to lose all house renovation credibility for the rest of your life.
Basic system design knowledge lets you break down a project/problem into its requirements and makes sure you can pick and implement the right pieces of technology for the job
Expanding On The Fundamentals - High Level Design
In the previous blog post we covered some very high level system design concepts:
- Terminology/Jargon
- System Design Principles
- Monolith Architecture
- Microservice Architecture
In this blog post, I'll try to introduce you to some of the components in a typical system. I'll also list out some resources from the last blog post (and some new ones) in case you are interested in learning more about System Design.
Bird's Eye View: A System
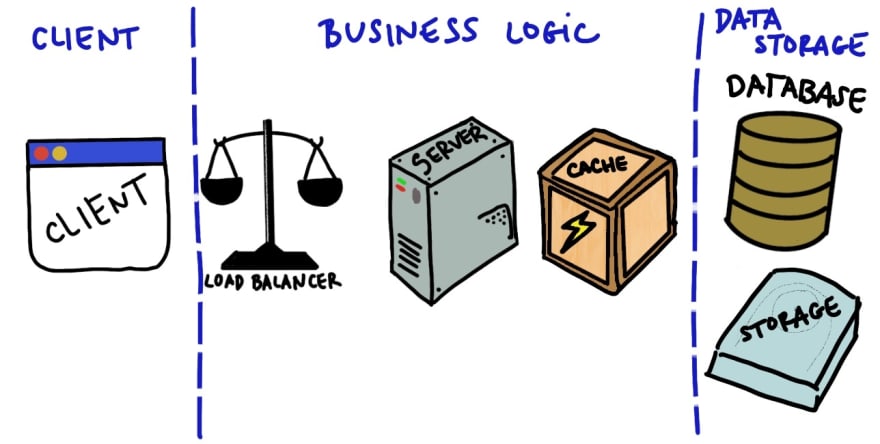
Looking at a system from a top level view. It'd look something like this.
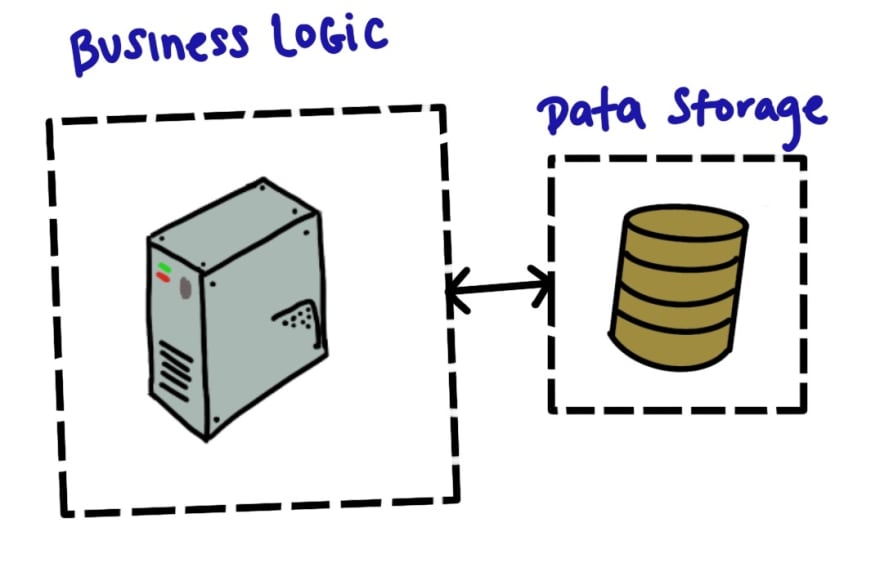
Business Logic
Devices and software dedicated to serving user or internal system requests such as:
- A user wants to create a new record (creating a new account) in a dating service
- A user wants to see all their followers (viewing many accounts)
- A user might want to update their account name (updating an existing record)
- A user might want to delete their account
Business logic consists of components that let an application efficiently carry out these kinds of CRUD (Create, Read, Update, Delete) operations. Typically the servers that carry out the logic store data in some kind of data storage if future requests will need access to data.
Data Storage
These are devices & software dedicated for the long-term storage of data that the system will need to carry out its services (whether it's to let a user search a song, or follow someone's feed). This typically will hold SQL/noSQL databases or Object Storage. These respond to the business logic. Usually services interact with data storage, and therefore the storage is not exposed to client requests (they are typically the last steps in service routes).
High Level System Components
Both parts of a system may be comprised some basic components
Business Logic
- Service(s)
- Load Balancers
Data Storage
- SQL & noSQL Databases
- File/Block & Object Storage
- Caches
Let's look at each of these and see what they are and how they fit in!
Business Logic
Service
A Service is function that is built of infrastructure (think servers, caches, load balancers etc.) that are designed to accomplish a specific task. They might interact with client requests or be totally internal. It lives in the business logic part of your system.
- A Netflix streaming service has a single responsibility of getting a video to a user. Netflix has other independent services like a searching service, or recommendation service.
- A URL shortening service... shortens a URL.
- You might even have internal services (that users don't interact with), like a cleanup service that deletes old unused data, or a service dedicated to generating unique identifiers as an intermediate step in a record creation.
For example, You can imagine that a client sends a request (maybe via HTTP), which hits a proxy server that determines whether Service #1 or Service #2 handles the request. Either service handles the request and persists data to their respective database. Service #3 may get triggered every 3 months to clean up or do something with the data in both the databases. Totally random example, but hopefully it illustrates the point.
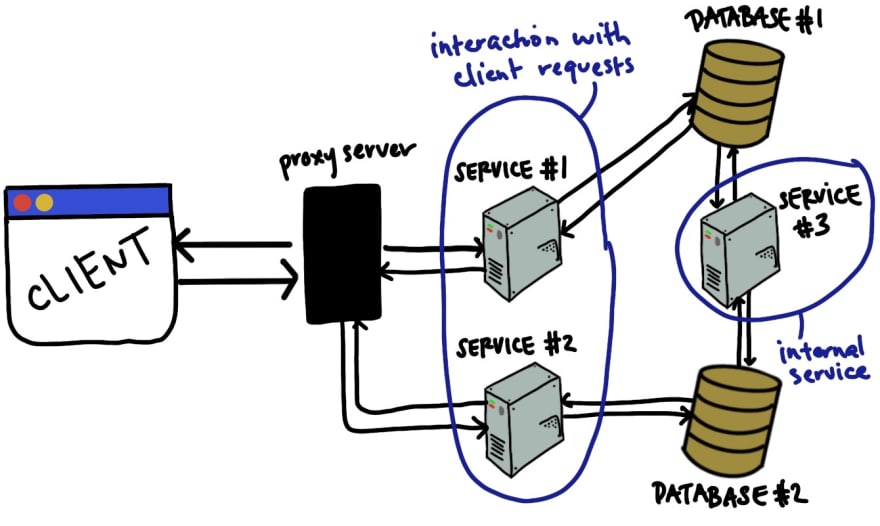
Services are the modular components that build the business logic of a system.
Load Balancers
Load Balancers are used in distributed systems when you are dealing with multiple servers that are for the same service. They balance the workload equally among all the servers, as well as re-route work in case a server goes offline (as well as other things). Here's a simple diagram of a system that would use a load balancer.
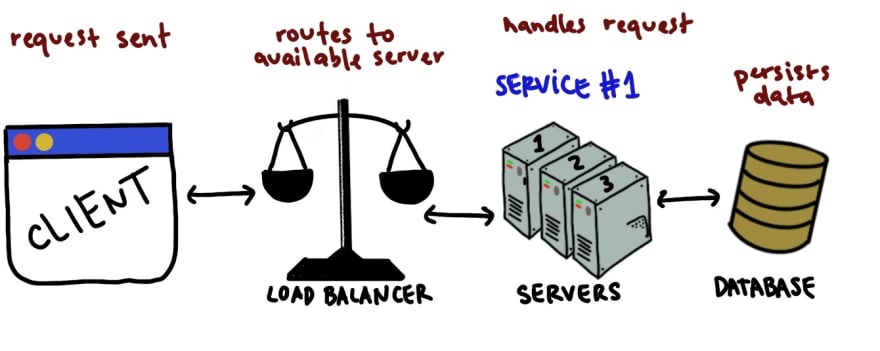
When you begin to scale your services up, perhaps you might want to install new machines dedicated to a service. You'd would then incorporate Load Balancers in your system design.
Data Storage
When talking about Data Storage for a system design, we often break them down into Databases and File/Block/Object Storage.
Databases
Databases are systematic collections of data. When you are deciding what kind of database you might need to use in your application, you'll be deciding between SQL and noSQL. Here's a breakdown of them both according to my studies.
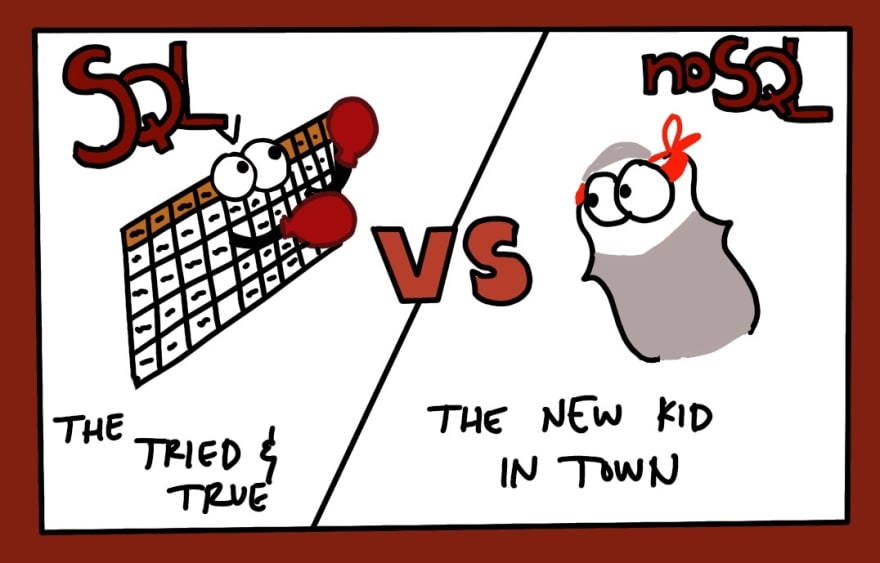
SQL
SQL is a relational-database/table-based query language. If you've used PostgreSQL or SQLite for Rails projects, you've worked with this before. SQL is a good database structure to follow if you want a database that:
- has a fixed schema (data structure never changes)
- requires complex queries
- has many relationships (data has references to each other)
- will be interfacing with a monolith system
- dealing with financial transactions
noSQL
noSQL is a non-relational/object-oriented query-language that has its own place in a system design. MongoDB is an example of a noSQL database. noSQL is a good database structure to follow if you want a database that:
- has a flexible schema (data structure may change)
- simple queries
- does not have many relationships (not many internal references)
- will be interfacing with a distributed system
- easier to run metrics or calculations on the data
Block, File and Object Storage
File, Block, and Object Storage are types of data storage that is meant for storing chunks of data like images, videos, and other types of files. You'd opt for this if you have data that has no structure (maybe you'd be storing a .txt file one time and a .png another time).
Block Storage
Block storage is typically located near the server (in the same physical space). It separates its data in hard disks and DOES NOT use the internet to send data. It's all local, so it's really fast. Naturally, it's hard to scale this type of system up because of its reliance on physical space.
File Storage (Network Attached Storage)
Typically connected via a local-area-network (I think of a computer network in an office building). Data is organized into files and directories. It's not as performant as block storage, but can scale more easily.
Object Storage
A highly scalable type of storage because you can connect any device from anywhere. Whenever you hear the term "cloud", that cloud is typically backed by Object Storage. It is very good for storing large amounts of unstructured data. It is the least performant of the three types of data storage. Typically if you're working with storing media, you'll have to consider implementing some form of Object Storage in the data storage part of your system. AWS S3 is one example of Object Storage (in fact it's used very often in cloud storage).
Caches
Imagine you have a service that accesses a database to get data based on a user request. What happens if you have many requests for that same piece of data? Well, each request for that same piece of data would have to go all the way to the database, and having the server 'search' for the same record in the database would be inefficient (reference the graphic below).

If we decided to use some special "local" storage for specific kinds of data like this, we could potentially reap some benefits:
- Prevent multiple calls across the network
- Prevent/Avoid recalculating things (store calculations)
- Avoid overtaxing a database
This is where a cache comes in handy. Caches in System Design are basically intermediate storage between a server and database dedicated to getting common/useful data quickly. A cache could be installed on the physical server (so we are not required to use a slow network call to get the data), or an intermediate source of storage between the server and the data storage. If we threw a cache into our system to reap some of the above benefits, it might look like this.
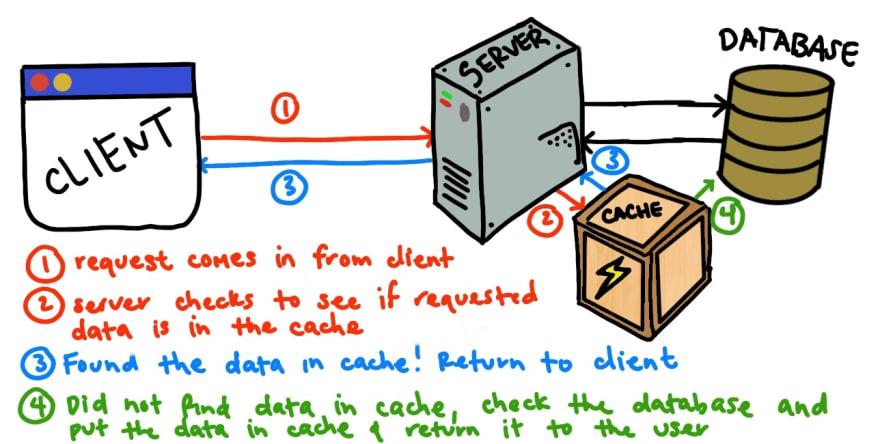
Conclusion
Hopefully at this point you are familiar with the simple building blocks of a larger system.
There's so much more left for me to learn! I feel like the more I dive into System Design, the more the topic opens up! It's exciting and overwhelming. I know a couple of my colleagues, like me, are also having interviews involving system design so I hope that this helps them and anyone else who is in the same boat!
Next Steps and Resources
Now that I have a grasp on the parts that build the business logic and data storage parts of a system, I'll try to hit on some design concepts and strategies as well as possibly answer a typical system design question in some future posts.
I hope this was helpful for you, and encourage you to learn more on your own! Here are a couple resources that were helpful for me:
Reading Resources:
System Design Primer
System Design Interview
High Scalability (Website)
Grokking The System Design Interview
Video Resources:
Gaurav Sen System Design Series
File, Block, and Object Storage
I hope this was helpful! Good luck with your own endeavors!
Shawn

Top comments (0)