
A Comprehensive Guide to Faster Deep Learning Training in PyTorch for Business Success
In the ever-evolving landscape of artificial intelligence, the race to develop smarter, more efficient deep learning models is at the forefront of technological advancement.
For businesses navigating this terrain, the process of training these models presents a critical bottleneck. This blog aims to simplify and break down the complexities of deep learning training acceleration, providing a comprehensive guide for businesses seeking to accelerate model development, achieve faster releases, and stay competitive in the dynamic world of AI.
Focusing particularly on PyTorch, we'll explore a spectrum of techniques—both programmatic and hardware-related—to optimise training times.
Understanding the Training Challenge:
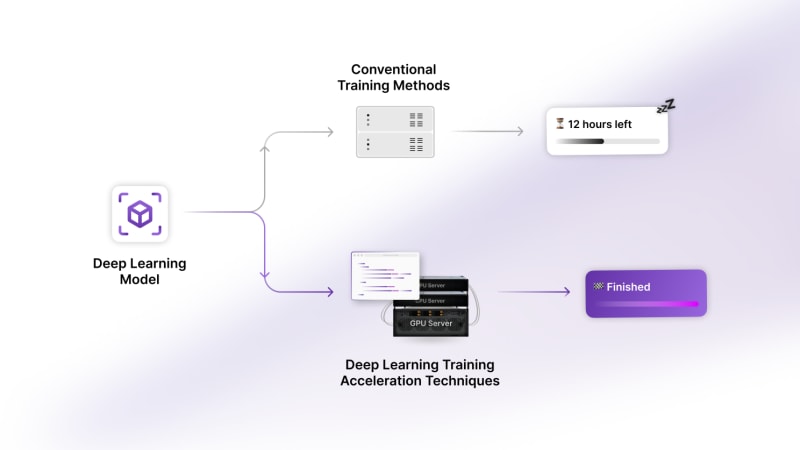
The Time Crunch:
Training deep learning models on intricate, expensive architectures and extensive datasets can be a time-consuming task. Conventional training methods often slow down progress and innovation.
How Acceleration Helps:
Deep learning training acceleration techniques—a combination of software and hardware optimisations—reduce the time required to train the models, enabling quicker model development.
Where It Matters:

In Everyday Scenarios:
Whether it is the latest face recognition technology or surveillance drones, accelerated training matters across diverse domains. Quicker training times empower businesses to iterate on models faster and respond promptly to evolving requirements. Reduced training times → faster iterations → increased R&D.
Especially in Adaptive Systems:
In fields like robotics, where systems need continuous learning and adaptation, faster training ensures these systems can quickly adjust to new environments and make decisions on the fly.
Benefits in Plain Terms:
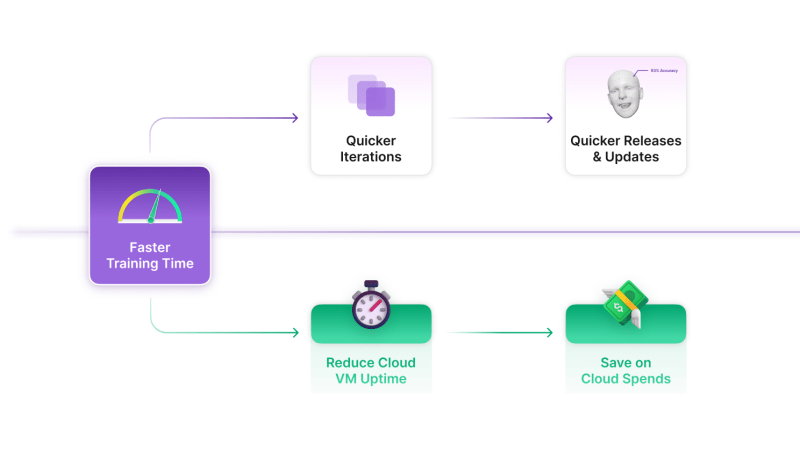
Getting Answers Faster:
By implementing these techniques, businesses can achieve faster training times, enabling quicker iterations and updates to models. This agility is crucial in dynamic industries where staying ahead is key.
Saving Money in the Process:
Accelerated training isn't just about speed; it's about using resources efficiently. If the training infrastructure is cloud based, where the billing is resource usage-based, businesses can optimize operational costs with reduced training times.
Choosing the Right Acceleration Solution:
Your Options:
In the PyTorch world, distributed training is a standout choice. PyTorch seamlessly integrates with distributed training frameworks, allowing for parallel processing across multiple devices, including GPUs. This not only speeds up the process but also enables efficient resource utilization
What to Think About:
Consider the complexity of your models and the scale of your data. Distributed training excels in handling parallel tasks, making it ideal for a wide range of PyTorch-based models. Choosing the right distributed training framework can further optimize your training.
Why is AI Training Slow?
To understand this, you need to understand the bottlenecks in model training.
1. Data Bottleneck:
Challenge: Limited access or slow retrieval of training data.

Data copy and retrieval operations can slow down AI training
Solution: Optimise data pipelines, employ data augmentation techniques, and consider strategies like prefetching to keep the model well-fed with data.
2. Communication Bottleneck:
Challenge: In distributed training, communication between devices can be a bottleneck. On top of that, training in a cloud-first infrastructure means that often your data and the model being trained are in different machines. The communication between these machines and fetching data over the network adds to extra overhead.

Solution: Utilize efficient communication frameworks, like PyTorch's DistributedDataParallel, and explore techniques such as gradient accumulation to minimize communication overhead. Also requires network and caching optimisations.
3. Model Bottleneck:
Challenge: Large model sizes can strain memory and computational resources.

Solution: Apply techniques like model quantization and pruning to reduce the model size. Consider model architecture optimizations and use more lightweight architectures when appropriate.
How Can I Make My Neural Network Train Faster?
Here are some techniques for accelerating training in PyTorch:
Distributed Training:
Leverage PyTorch's built-in support for distributed training, a technique that allows your models to learn faster by spreading the workload across multiple devices, including powerful GPUs. Utilize modules like DataParallel or DistributedDataParallel for efficient training, making the most of available resources.
Mixed Precision Training:
Optimize training efficiency by employing mixed precision techniques, using 16-bit floating-point numbers. This approach reduces the memory requirements during training, resulting in faster model training without significantly compromising overall accuracy.
Gradient Accumulation:
Enhance training speed by implementing gradient accumulation, a method that simulates larger batch sizes without demanding additional memory. This allows for more efficient use of resources during the training process.
Learning Rate Schedulers:
Incorporate learning rate schedulers into your PyTorch workflow to dynamically adjust the learning rate during training. This dynamic adjustment can potentially speed up the convergence of your models, leading to faster training times.
Quantization:
Streamline your models by applying quantization techniques, which reduce the precision of model weights and activations. This not only results in smaller model sizes but also enables faster inference, allowing your models to make predictions more swiftly.
Pruning:
Efficiently refine your models by pruning unnecessary connections or parameters. This process reduces redundancy, enabling faster training without compromising the accuracy of your models.
Knowledge Distillation:
Implement knowledge distillation, a strategy where a compact model (student) learns from a larger, more complex model (teacher). This accelerates the training of the compact model, providing a quicker path to deploying efficient and effective models.
Selective Backpropagation:
Focus your training efforts on specific parts of the model using selective backpropagation. This targeted approach allows for updates in critical areas, improving the overall efficiency of the training process.
Do These Techniques Actually Work In Speeding Up The Training?
The above mentioned techniques work really well by resolving the model bottlenecks to some extent. However, these techniques have their own drawbacks.
Distributed training has a huge cost-to-performance tradeoff, because of the fact that adding more machines increases the cost linearly, but the performance scales sublinearly. As in, adding 8x GPU machines increases the cost of infrastructure by 8x, but the speedup will roughly be around 1.5x-4x depending on your data and model complexity.
Other techniques like quantization, pruning, knowledge distillation, etc. are known to affect model’s performance.
On top of that, the data and communication bottlenecks during a training sequence still persist.
So the question persists— Are we really “speeding up” the training?
Scaletorch To The Rescue!
To solve these above-mentioned issues, we have developed Scaletorch, a software solution that relies on its underlying technology— the Deep Learning Offload Processor (DLOP) to transparently speed up your AI training by a factor of 4x-20x; no changes required to your PyTorch training script.
Scaletorch can accelerate a variety of training workloads such as computer vision, video, medical imaging, sensory data, software-defined radio, etc. It brings about the speed-up by using a combination of offloading certain operations from GPUs (or other deep learning accelerators like TPUs) to the DLOP workers, as well as asynchronous processing of the training pipelines. In conjunction with an intelligent data streaming engine, Scaletorch addresses the data and communication bottlenecks as well. And all the above mentioned techniques still work right out of the box.
Head over to Scaletorch.ai to know more! We’ve got a benchmark to demonstrate the results as well.
In Conclusion:
Simplifying deep learning training in PyTorch involves a toolbox of techniques, from distributed training to advanced strategies like quantization and knowledge distillation. By understanding and implementing these practical techniques, businesses can expedite their model development process, release updates faster, and stay at the forefront of AI innovation. The fusion of PyTorch's flexibility with accelerated training, along with addressing bottlenecks, is reshaping how industries leverage deep learning, creating a pathway for transformative AI applications.





Top comments (0)