
Table of contents
- Function purity
- Referential transparency
- How to deal with impure functions?
- Practical example (long chapter)
Function purity
A function is considered pure if it does not have any side effects. To understand what a side effect is, please refer to the previous article of this series.
In other words, given some input, a function will always return the same output. External factors, such as network conditions or global state changes, have no impact on the returned value of a pure function.
Let's suppose we have a greet function. The impure version performs a HTTP request to some API endpoint in order to retrieve the final greeting message. The pure version does a simple string concatenation. When the network is no longer available, the function with side effect does not work anymore, whereas the pure one still does.

We want to work with as many pure functions as possible because they are predictable, thus making it easy to understand and test their behaviors.
Additionally, pure functions ensure that we can only care about their returned values. We do not have to worry about how the value was calculated. Hence, we can treat pure functions as black boxes, and just use their results to reason about the program.
Referential transparency
Referential transparency is the ability to replace an expression with its result, without changing the meaning/behavior of the program.
It is a property of expressions, which applies to pure functions, since these functions are essentially parametrized expressions.
As a simple example, we can use the expression 2 + 3. This expression is pure (i.e. no side effects), so it is referentially transparent. We can replace 2 + 3 with its result 5 without changing the behavior of the program. For example, if the program was computing the following expression: ((2 + 3) + 2) / 7, then computing ((5) + 2) / 7 would yield the same result, 1. The behavior of the program is preserved, although its definition has been simplified.
It does not matter how many times you evaluate an expression: it will always yield the same result.
For functions, we can represent this property as a mapping between the "function reference + its inputs" and "its output":

We can use the referential transparency property for optimization purposes (both developers and compilers), such as using lazy evaluation, memoization, or parallelization.
The opposite of referential transparency is referential opacity. This means that we cannot replace the expression or function call with its result, we have to run it.
Any function that performs side effects is referentially opaque. As mentioned in the previous article, we need side effects in our programs to make them useful. This means that we cannot have only pure functions, though we want as many of these functions as possible.
How to deal with impure functions?
It is very easy to write impure functions. As soon as we need some external dependency, such as a global state, making a network request, or reading from a file, we can simply reference these dependencies in the middle of our functions to use them.
However, in my experience, this can eventually make the code look like a plate of spaghetti, and it makes it harder to understand what the function actually does as a whole.
In addition, when it comes time to test these functions, we often have to mock the dependencies before each test case. This can lead to having complex before/after hooks to set up the tests, and restore the state prior to running these tests.
We cannot get rid of the side effects though, so how can we deal with this situation?
We have to identify the parts of the function that are pure, and the ones that are not. Then, we can move the pure and not-so-pure parts into their own functions. Finally, we can rewrite the original function by using the pure ones directly, and by explicitly providing the (side-effectful) dependencies as an argument, using Dependency Injection (a.k.a DI).
I am not going to talk about DI frameworks here. We are going to use the simplest version of DI: passing a dependency as one of the function's arguments.
The final result is still an impure function, since a function that needs at least one side effect cannot be pure. But, this time the pure parts are separated and can be tested easily, while the impure parts are explicitly passed as arguments and can be easily replaced with lab values to write tests.
That being said, if you have read the previous article, you have seen one way to deal with side effects: using intermediate functions (or "thunks") to make them lazy, thus making the function artificially pure.
Practical example
I was not sure if I should include this chapter in this article. I think it adds an interesting value at this point of the serie, though I may move this chapter in a dedicated article in the future.
Let's consider the following function, whose goal is to get the definition of a term provided by a user. It does the following:
- Keep track of the terms searched
- Make sure the term is valid
- Get the definition of the term from a cache, if available
- If not, make a request to a web service, then cache the result in a file
Hereafter is its definition, using the TypeScript language:
import { promises as fs } from 'fs'
import fetch from 'node-fetch'
const searchedTerms = new Set<string>()
export async function getTermDefinition(term: unknown): Promise<string> {
if (!term || typeof term !== 'string') {
throw new Error(`Invalid term: ${term}`)
}
const lcTerm = term.toLowerCase()
if (searchedTerms.has(lcTerm)) {
return fs.readFile(`definitions/${lcTerm}.txt`, 'utf8')
}
const response = await fetch(`/api/definition?term=${lcTerm}`)
const { definition } = await response.json()
await fs.writeFile(`definitions/${lcTerm}.txt`, definition)
searchedTerms.add(lcTerm)
return definition
}
As you know, there are hundreds of ways to write a function with the features listed above. I intentionally wrote it this way for academic purposes, though it may not be that far from an actual production implementation.
We know it is impure because it has the following side effects:
- It reads from a global state:
searchedTerms - It reads from a file to get the definition of a term:
fs.readFile - It calls an API endpoint using HTTP:
fetch - It updates the global state:
searchedTerms.add - It writes to a file:
fs.writeFile
Here are the pure parts of this function:
- Validate the term, making sure it is a non-empty string
- Technically, since we throw an error, this part is not really pure. We could have chosen to return a
Either/Validation/Resultdata type instead. But, for the sake of simplicity, let's keep the error throw and consider this part pure.
- Technically, since we throw an error, this part is not really pure. We could have chosen to return a
- Transform the term by making it lower case
- We could add more transformation steps here, such as sanitizing the string to remove special characters.
Testing the function
To test this function using Jest, we have to rely heavily on mocking:
jest.mock('fs', () => ({
promises: {
readFile: jest.fn(),
writeFile: jest.fn()
}
}))
import { promises as fs } from 'fs'
jest.mock('node-fetch')
import fetch from 'node-fetch'
const { Response } = jest.requireActual('node-fetch')
import { getTermDefinition } from './getTermDefinition'
describe('getTermDefinition', () => {
type MockedReadFile = jest.MockedFunction<typeof fs.readFile>
type MockedWriteFile = jest.MockedFunction<typeof fs.writeFile>
type MockedFetch = jest.MockedFunction<typeof fetch>
beforeEach(() => {
;(fs.readFile as MockedReadFile).mockReset()
;(fs.writeFile as MockedWriteFile).mockReset()
;(fetch as MockedFetch).mockReset()
})
test('invalid term', async () => {
await expect(getTermDefinition(42)).rejects.toEqual(
new Error('Invalid term: 42')
)
})
test('valid term "foo", cache miss', async () => {
;(fetch as MockedFetch).mockResolvedValue(
new Response(JSON.stringify({ definition: 'description' }))
)
expect(await getTermDefinition('foo')).toBe('description')
expect(fs.writeFile).toHaveBeenCalledWith(expect.any(String), 'description')
})
test('valid term "foo", cache hit', async () => {
;(fs.readFile as MockedReadFile).mockResolvedValue('description')
expect(await getTermDefinition('foo')).toBe('description')
expect(fetch).not.toHaveBeenCalled()
expect(fs.writeFile).not.toHaveBeenCalled()
})
})
The mocking parts represent approximately 40% of the lines written to test the getTermDefinition function.
Given the current implementation of the module exposing the tested function, we cannot control the searchedTerms list. Here, to test the "cache hit" part, we have to:
- First call the function with a given term "foo" to cache the result, and update the
searchedTermslist - Then call the function a second time, with the exact same term "foo" to hit the cache
A test case should not depend on another. We should be able to copy/paste the test(...) blocks wherever we like.
To do that, we need to control the searchedTerms list. One way of doing that would be to export it from the module, then set it up in the tests:
- import { getTermDefinition } from './getTermDefinition'
+ import { searchedTerms, getTermDefinition } from './getTermDefinition'
describe('getTermDefinition', () => {
beforeEach(() => {
+ searchedTerms.clear()
})
test('valid term "foo", cache hit', async () => {
+ searchedTerms.add('foo')
;(fs.readFile as MockedReadFile).mockResolvedValue('description')
expect(await getTermDefinition('foo')).toBe('description')
expect(fetch).not.toHaveBeenCalled()
expect(fs.writeFile).not.toHaveBeenCalled()
})
})
There, we managed to test this function, despite its number of side effects. Though, to do that, we had to write a lot of code to mock the external dependencies, and we had to expose the searchedTerms list to control it.
Furthermore, if we want to move to a different HTTP or file system library in the future, we would have to:
- Adapt the implementation of this function
- Adapt all the mocking parts of the tests
Let's try to move the different pure and impure parts into dedicated functions, then use dependency injection and compose these functions together to rebuild getTermDefinition.
Splitting the function
Let's move the pure parts into 2 separate functions: validateTerm and transformTerm.
For the other parts, we are going to use a Dependencies object passed as the second parameter of the getTermDefinition function. This object will contain the following elements:
- The list of searched terms:
searchedTerms - A function to read from a file:
readFile - A function to write to a file:
writefile - A function to fetch the definition of a term:
fetchDefinition
We are also going to provide default values for these dependencies, using the fs and node-fetch modules, for the live environments (i.e. development and production).
Note that the searchedTerms list is not exported anymore, as we can provide one using the Dependencies object.
import { promises as fs } from 'fs'
import fetch from 'node-fetch'
const searchedTerms = new Set<string>()
function validateTerm(term: unknown): asserts term is string {
if (!term || typeof term !== 'string') {
throw new Error(`Invalid term: ${term}`)
}
}
function transformTerm(term: string): string {
return term.toLowerCase()
}
async function readFile(path: string): Promise<string> {
return fs.readFile(path, 'utf8')
}
async function writeFile(path: string, content: string): Promise<void> {
return fs.writeFile(path, content)
}
async function fetchDefinition(term: string): Promise<string> {
const response = await fetch(`/api/definition?term=${term}`)
const { definition } = await response.json()
return definition
}
export interface Dependencies {
searchedTerms: Set<string>
readFile: (path: string) => Promise<string>
writeFile: (path: string, content: string) => Promise<void>
fetchDefinition: (term: string) => Promise<string>
}
const defaultDependencies: Dependencies = {
searchedTerms,
readFile,
writeFile,
fetchDefinition
}
export async function getTermDefinition(
term: unknown,
{ searchedTerms, readFile, writeFile, fetchDefinition } = defaultDependencies
): Promise<string> {
validateTerm(term)
const lcTerm = transformTerm(term)
if (searchedTerms.has(lcTerm)) {
return readFile(`definitions/${lcTerm}.txt`)
}
const definition = await fetchDefinition(lcTerm)
await writeFile(`definitions/${lcTerm}.txt`, definition)
searchedTerms.add(lcTerm)
return definition
}
Testing the new version
As we have added the Dependencies parameter to the function, we can provide values and mocks, depending on the test case. We are still using mocked functions, but this time we are not mocking entire modules anymore.
Note that we did not export the pure functions from this module. Here, I made the choice to test them indirectly when testing the main function getTermDefinition. In addition, I did not add any test case for invalid terms such as 42 for simplicity, but it should be added for a real case.
import { getTermDefinition, Dependencies } from './getTermDefinition'
describe('getTermDefinition', () => {
const baseDependencies: Dependencies = {
searchedTerms: new Set<string>(),
readFile: jest.fn(),
writeFile: jest.fn(),
fetchDefinition: jest.fn()
}
test('invalid term', async () => {
await expect(getTermDefinition(42, baseDependencies)).rejects.toEqual(
new Error('Invalid term: 42')
)
})
test('valid term "Foo", cache hit', async () => {
const dependencies = {
...baseDependencies,
searchedTerms: new Set<string>(['foo']),
readFile: jest.fn().mockResolvedValue('definition')
}
const definition = await getTermDefinition('Foo', dependencies)
expect(definition).toEqual('definition')
expect(dependencies.fetchDefinition).not.toHaveBeenCalled()
expect(dependencies.writeFile).not.toHaveBeenCalled()
})
test('valid term "foo", cache miss', async () => {
const dependencies = {
...baseDependencies,
fetchDefinition: jest.fn().mockResolvedValue('definition')
}
expect(dependencies.searchedTerms.size).toBe(0)
const definition = await getTermDefinition('foo', dependencies)
expect(definition).toEqual('definition')
expect(dependencies.writeFile).toHaveBeenCalled()
expect([...dependencies.searchedTerms]).toEqual(['foo'])
})
})
The changes we made allow us to refactor the code to use a different HTTP or file system module, simply by changing the implementations of readFile, writeFile, and fetchDefinition. Plus, we do not have to update the tests at all, because the Dependencies interface does not change.
This example was not entirely about "purifying" an impure function. We have seen how to handle side effects in the previous article of this series. Here, I tried to show you how we can organize our code to split the pure and impure parts into dedicated functions. Then, we can use dependency injection to make these side-effectful dependencies explicit, and provide fully-controlled values to write the tests. Hopefully you enjoyed this chapter!
Thank you for reading this far! As always, feel free to share your opinion in the comments :) Next time we will talk about data immutability. See you!
Photo by Xavi Cabrera on Unsplash.
Pictures made with Excalidraw.

Top comments (4)
Just awesome, gonna share this on my Purity Test blog. Appreciated!
Happy Holidays! I really enjoyed reading your articles. I was wondering if you could answer a question of mine.
I copies and pasted the new test file to my VS code and got errors for the
readFile,writeFile, andfetchDefinitionproperties of thebaseDependenciesobject. I have attached a screenshot here. It would be great if you could shed some light on what's the underlying issue here.Thank you.
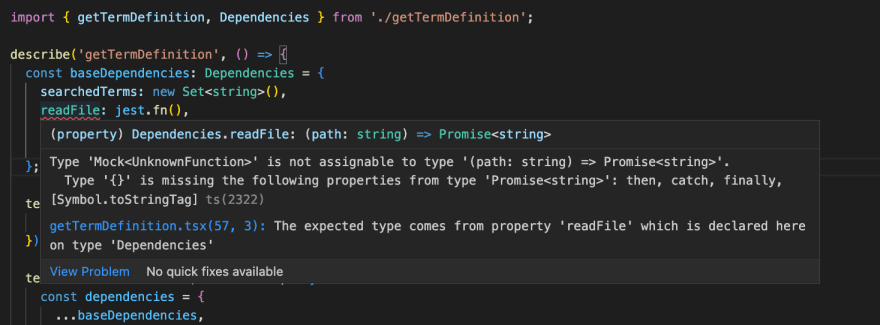
Hello, and happy holidays to you too!
Last time I checked, I didn't have any TS error. I was using the following:
jest@27.5.1ts-jest@27.1.4Can you tell me which versions you are using for these dependencies? Also, as a simple "fix", you may try to use a type assertion such as
jest.fn() as (path: string) => Promise<string>.Hello,
Thank you for your reply.
I am using:
"@jest/globals": "^29.3.1",
"ts-jest": "^29.0.3"
The simple 'fix' works for me!
Thanks again!