
The first installment mainly covered the technical side of things, like the limits and configuration options. This next part looks at how to use all the technical considerations we checked out in part one to effectively design serverless and Lambda systems.
By the end of this post, you should have a good understanding of the key considerations to keep in mind when designing around AWS Lambda. Let’s dive in. If you have checked out Part one, pop over and have a read before getting stuck into part two.
This is an article written for Jefferson Frank, it can be found here or on my blog.
General design considerations
9) Types of AWS Lambda errors
How you handle errors and failures all depends on the use case and the Lambda service that invoked the Lambda.
There are different types of errors that can occur:
- Configuration: These happen when you’ve incorrectly specified the file or handler, or have incorrect directory structures, missing dependencies, or the function has insufficient privileges. Most of these won’t be a surprise and can be caught and fixed after deployment.
- Runtime: These are usually related to the code running in the function, unforeseen bugs that we introduce ourselves and will be caught by the runtime environment.
- Soft errors: Usually not a bug, but an action that our code identifies as an error. One example being when the Lambda code intentionally throws an error after retrying three times to call a third-party API.
- Timeouts and memory: They fall in a special kind of category as our code usually runs without problems, but it might have received a bigger event than we expected and has to do more work than we budget for. They can be fixed by either changing the code or the configuration values.
Remember—certain errors can’t be caught by the runtime environment. As an example, in NodeJS, if you throw an error inside a promise without using the reject callback, then the whole runtime will crash. It won’t even report the error to CloudWatch Logs or Metrics, it just ends. These must be caught by your code, as most runtimes have events that are emitted on exit and report the exit code and reason before exiting.
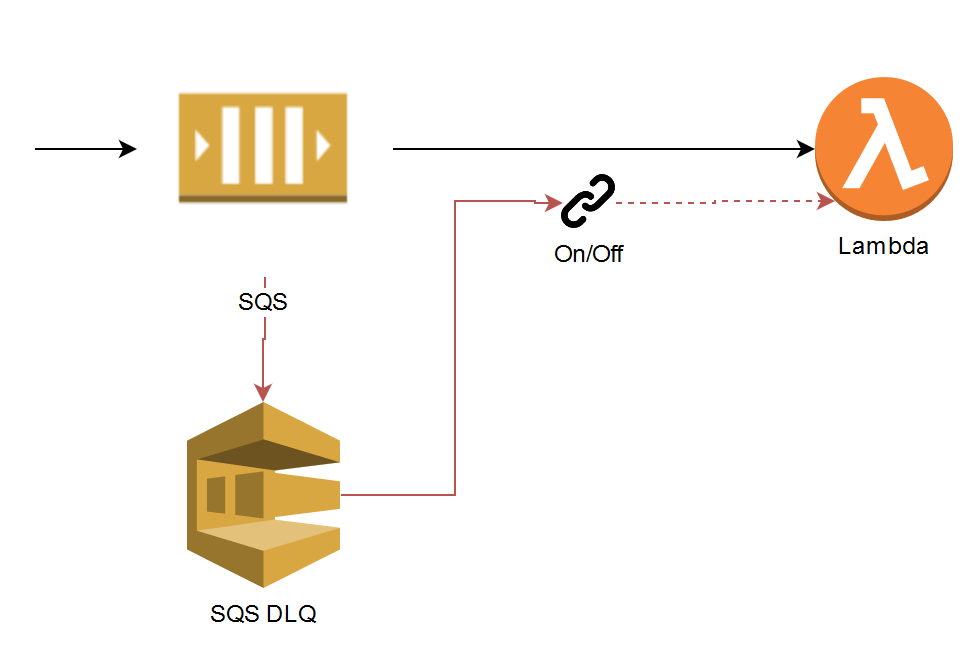
When it comes to SQS , a message can be delivered more than once, and if it fails, it’ll be re-queued after the visibility timeout and then retried. When your function has a concurrency of less than five, the AWS polling function will still take messages from the queue and try to invoke your function. This will return a concurrency limit reached exception, and the message will then be marked as being unsuccessful and returned to the queue—this is unofficially called “over-polling.” If you have a DLQ configured on your function, messages might be sent there without being processed, but we’ll say more about this later.
SQS “over-polling”: If the Lambda is being throttled and then messages are sent to the DLQ without being processed.
Then for stream-based services like DynamoDB and Kinesis streams, you have to handle the error within the function or it’ll be retried indefinitely; you can’t use the built-in Lambda DLQs here.
For all other async invocations, if it fails the first invocation, it will retry two or more times. These retries mostly happen within three minutes of each other, but in rare cases it may take up to six hours, and there might also be more than three retries.
10) Handling Errors
Dead Letter Queues (DLQ) to the rescue. Maybe not, DLQs only apply to async invocations; it doesn’t work for services like SQS, DynamoDB streams and Kinesis streams. For SQS use a Redrive Policy on the SQS queue and specify the Dead Letter Queue settings there. It’s important to set the visibility timeout to at least six times the timeout of your function and the maxRecieveCount value to at least five. This helps prevent over-polling, messages being throttled and then being sent to the DLQ when the Lambda concurrency is low.
Alternatively, you could handle all errors in your code with a try-catch-finally block. You get more control over your error handling this way and can send the error to a DLQ yourself.
Now that the events/messages are in the DLQ and the error is fixed, these events have to be replayed so that they’re processed. They need to be taken off the DLQ, and then that event must be sent to the Lambda once again so that it can be processed successfully.
There are different methods to do this and it might not happen often, so a small script to pull the messages and invoke the Lambda will do the trick. Replaying functionality can also be built into the Lambda, so that it knows it if receives a message from the DLQ to extract the original message and run the function. The trigger between the DLQ and the Lambda will always be disabled, but then enabled after the code is fixed and the message can be reprocessed.
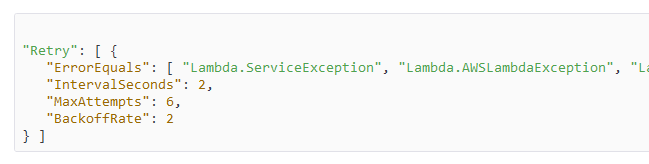
AWS Step Functions also give you granular control over how errors are handled. We can control how many times it needs to be retried, the delay between retries, and the next state.
With all these methods available, it’s crucial that your function is idempotent. Even for something complex like credit card transactions, it can be made idempotent by first checking if the transaction with your stored transaction callback ID has been successful, or if it exists. If it doesn’t, then only carry out the credit deduction.
If you can’t get your functions to be idempotent, consider the Saga pattern. For each action, there must also be a rollback action. Taking the credit card example again, the Lambda that has a Create Transaction function must also have a Reverse Transaction function, so that if an error happens after the transaction has been created, it can propagate back and the reverse transaction function can be fired. So that the state is exactly the same as it was before the transaction began. Of course, it’s never this straightforward when working with money, but it’s a solid example.
If you can’t get your functions to be idempotent, consider the Saga pattern. For each action, there must also be a rollback action.
Duplicate messages can be identified by looking at the context.awsRequestId inside the Lambda. It can be used to de-dupe duplicate messages, if a function cannot be idempotent then this should be used. Store this ID in a cache like Redis or a DB to use it in the de-dupe logic; this introduces a new level of complexity to the code, so keep it as a last resort and always try to code your functions to be idempotent.
A Lambda can also look at the context.getRemainingTimeInMillis() function to know how much time is left before the function will end. This is so that if processing takes longer than usual, it can stop, gracefully do some end function logic, and return a soft error to the caller.
11) Coupling
Coupling goes beyond Lambda design considerations—it’s more about the system as a whole. Lambdas within a microservice are sometimes tightly coupled, but this is nothing to worry about as long as the data passed between Lambdas within their little black box of a microservice is not over-pure HTTP and isn’t synchronous. Lambdas shouldn’t be directly coupled to one another in a Request Response fashion, but asynchronously. Consider the scenario when an S3 Event invokes a Lambda function, then that Lambda also needs to call another Lambda within that same microservice and so on.
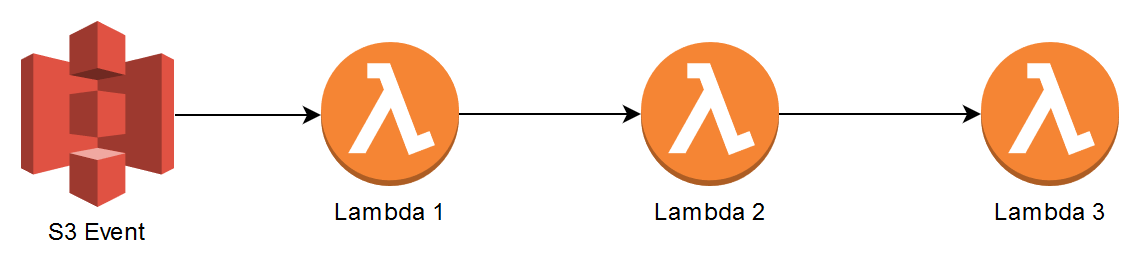
You might be tempted to implement direct coupling, like allowing Lambda 1 to use the AWS SDK to call Lambda 2 and so on. This introduces some of the following problems:
- If Lambda 1 is invoking Lambda 2 synchronously, it needs to wait for the latter to be done first. Lambda 1 might not know that Lambda 2 also called Lambda 3 synchronously, and Lambda 1 may now need to wait for both Lambda 2 and 3 to finish successfully. Lambda 1 might timeout as it needs to wait for all the Lambdas to complete first, and you’re also paying for each Lambda while they wait.
- What if Lambda 3 has a concurrency limit set and is also called by another service? The call between Lambda 2 and 3 will fail until it has concurrency again. The error can be returned to all the way back to Lambda 1 but what does Lambda 1 then do with the error? It has to store that the S3 event was unsuccessful and that it needs to replay it.
This process can be redesigned to be event driven:
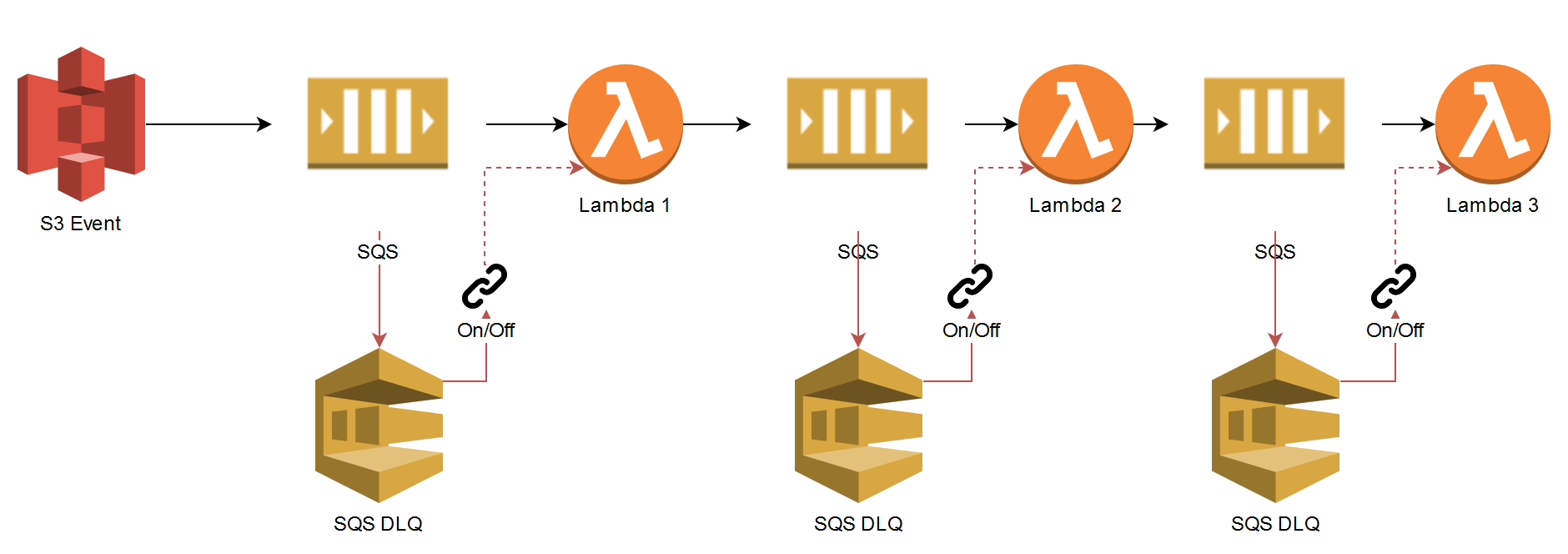
Not only is this the solution to all the problems introduced by the direct coupling method, it also:
- Provides a method of replaying the DLQ if an error occurred for each Lambda.
- No message will be lost or need to be stored externally.
- The demand is decoupled from the processing. The direct coupling method would have had failures if more than 1,000 objects were uploaded at once and generated events to invoke the first Lambda. This way, Lambda 1 can set its concurrency to be five and use the batch size to only take X amount of records from the queue and thus control maximum throughput.
Going beyond a single microservice, when events are passed between them both needs to understand and agree upon the structure of the data. Most of the time both microservices can’t be updated at the exact same time, so be sure to version all your events. This way you can change all the micro services that listen for event version 1 and add the code to handle version 2. Then update the emitting microservice to emit version 2 instead of 1, always with backwards compatibility in mind.
12) AWS Lambda batching
Batching is particular useful in high transaction environments. SQS and Kinesis streams are some services that offer batching messages, sending the batch to the Lambda function instead of each and every message separately. By batching the values in groups of around 10 messages instead of one, you might reduce your AWS Lambda bill by 10 and see an increase in system performance throughput.
By batching the values in groups of around 10 messages instead of one, you might reduce your AWS Lambda bill by 10 and see an increase in system performance throughput.
One of the downsides to batching is that it makes error handling complex. For example, one message might throw an error and the other nine are processed successfully. Then Lambda needs to either manually put that one failure on the DLQ, or return an error so that the external error handling mechanisms, like the Lambda DLQ, do their jobs. It could be that case that a whole batch of messages need to be reprocessed; here, being idempotent is again the key to success.
If you’re taking things to the next level, sometimes batching is not enough. Consider a use case where you’ve got a CSV file with millions of records that needs to be inserted into DynamoDB. The file is too big to load into the Lambda memory, so instead you stream it within your Lambda from S3. The Lambda can then put the data on a SQS queue and another Lambda that can take the rows in batches of 10 and write them to DynamoDB using the batch interface.
This sounds okay, right? The thing is, a much higher throughput and lower cost can actually be achieved if the Lambda function that streams the data writes to DynamoDB in parallel. Start building groups of batch write API calls, where each can hold a maximum of 25 records. These can then be started and limited to roughly 40 parallel/concurrent batch writes, without much tuning, you will be able to reach 2k writes per second.
13) Monitoring and Observability
Modern problems require modern solutions. Since traditional tools won’t work for a Lambda and serverless environment, it’s difficult to find visibility and to monitor the system. There are many tools out there to help with this including internal AWS Services like X-Ray, CloudWatch Logs, CloudWatch Alarms, and CloudWatch Insights. You could also turn to third-party tools like Epsagon, IOPipe, Lumigo, Thunderbird, and Datadog to just name a few.

All these tools deliver valuable insights in the form of logs and charts to help evaluate and monitor the serverless environment. One of the best things you can do is to get visibility early on and fine-tune your Lambda architecture. Finding the root cause of a problem and tracing the event as it goes through the whole system can be extremely valuable.
Bonus tips and tricks!
- Within a Lambda your code can do parallel work. If you’re receiving a batch of 10 messages, instead of doing 10 downstream API calls synchronously, do them in parallel. It reduces the run time as well as the cost of the function. This should always be considered first before moving on to the more complex fan out-fan in.
- Lambdas doing work in parallel will usually benefit from an increase in memory.
- All functions must be idempotent , and do consider making them stateless. One example we can look at is when functions need to keep some small amount of session data for API calls. Let the caller send the SessionData with the SessionID and make sure both these fields are encrypted. Then, decrypt their values and use it in the Lambda, this can spare you from carrying out repeated external calls or using a cache.
- You might not need an external cache ; a small amount of data can be stored above the Lambda function handler method in memory. This data will remain for the duration of the Lambda container.
- Alternately, each Lambda is allowed 500 MB of file storage in /tmp , and data can be cached here as a file system call will always be faster than a network call.
- Keep data inside the same region , to avoid paying for data to be transferred beyond that region.
- Only put your Lambda inside a VPC if it needs to access private services or needs to go through a NAT for downstream services that whitelist IPs.
- Remember NAT data transfer costs money, and services like S3 and DynamoDB are publicly available. All data that flows to your Lambdas inside the VPC will need to go through the NAT.
- Consider using S3 and DynamoDB VPC Gateway Endpoints—they’re free and you only pay for Interface Endpoints.
- Batching messages can increase throughput and reduce Lambda invocations, but this also increases complexity of error handling.
- Big files can be streamed from S3.
- Step functions are expensive , so try and avoid them for high throughput systems.
- If you have a monorepo where all the Lambda functions live for that microservice, consider creating a directory that gets symlinked into each of those Lambda directories. Shared code only needs to be managed in one place; alternately, you could look into putting shared code into a Lambda layer.
- A lot of AWS Services make use of encryption to protect data, so consider using that instead of encrypting on an application level.
- The less code you write the less technical debt you build up.
- Where possible use the AWS Services as they are intended to be used , or you could end up needing to build tooling around your specific use case and manipulate those services. This once again adds to your technical debt. AWS Lambda scales quickly and integration with other systems—like a MySQL DB with a limited amount of open connections—can quickly become a problem. There is no silver bullet for integrating a service that scales and one that doesn’t. The best thing that can be done is to either limit the scaling or implement queuing mechanisms between the two.
- Environment variables should not hold security credentials , so try using AWS SSM‘s Parameter Store instead. It’s free and is great for most use cases; when you want higher concurrency consider using Secret Manger, it also supports secret rotation for RDS but it comes at higher cost than Parameter Store.
- Consider using Infrastructure as Code (IaC) if you aren’t.
- API Gateway has the ability to proxy the HTTP request to other AWS Services, eliminating the need for an intermediate Lambda function. Using Velocity Mapping Templates you can change the normal POST parameters into the arguments that DynamoDB requires for the PUT action. This is great for simple logic where the Lambda would have just transformed the request before doing the DynamoDB command.
So what’s the bottom line?
Always try to make Lambda functions stateless and idempotent , regardless of the invocation type and model. Lambdas aren’t designed to work on a single big task, so break it down to smaller tasks and process it in parallel. After that, the single best thing to do would be to measure three times and cut once; do a lot of upfront planning, experiments, and research and you’ll soon develop a good intuition for serverless design.

Top comments (6)
Comprehensive compilation! 😉
What is your approach when using SQS would add too much latency (#11 Coupling)?
Let's say you have this sort of data flow:
Say an SQS implementation would add too much latency here, we need to respond in < 500 ms. What ideas do you have for decoupling in such cases?
I can think of two scenarios where that might be the case. Two assumptions; you control both lambdas, these lambdas are services.
The second service let's call it service B can emit an event when ever data is written to its database. Then service A can listen to that and store the formatted data in it's own database/storage. So that when service A gets hit through the API, it does not need to do a call to service B/second Lambda, it can just get the already formatted data that it stored in its own DB.
It might be 'okay' if you only have 1 Lambda calling another Lambda using an API, if you are willing to accept the consequences (at the end). At this point the 2 Lambdas are dependent upon each other anyway so you might as well remove the API and call it directly with the AWS SDK. I would only do this direct coupling with 2 Lambdas at most if you really have to, more than that indicates a serious design flaw in the system.
Which option to choose:
It depends on what type of system you have and how much complexity you want to introduce. Method 1 would be great if have a read heavy application as you now only have to invoke 1 Lambda and the total duration to fetch the data will be greatly reduced. This creates an event driven system that brings the data to the "edge"/preformatted for the API to just return.
The first method quickly falls apart if you have a write heavy application as it will continuously be firing events and service A might be updating its own data that will not be read at that update frequency. So it will be more expensive. There is also now latency introduced by the eventual consistency of the event driven architecture and will be felt much more if it is a write heavy application.
For the second method you will be paying for both Lambda execution times, roughly the whole API call duration. This will turn out to be roughly twice as expensive compared to the first solution if the application is read heavy. You will also reach your account limits, the maximum invocation count twice as fast. Solution 2 is kind of a design smell, but then you have to draw that black box around both the Lambdas, if either 1 is down the whole service is down. Solution 1 also had the unexpected benefit that Service A became a write-throught-cache to service B. So if the DB goes down, the data is still stored at the API level and will still be returned to the caller. Your system will just not be able to write anymore because service B is down.
I think there is many ways to approach this problem, that is just 2 ways I would consider.
Thanks for the clarifications, definitely shed more light on the subject! 💡
It's a complex topic indeed. I'm very interested in improving my skills to make better decisions on this type of scenario. If you have any suggestions for articles/books/etc that were helpful to you, I would be grateful!
Thanks again! 👍
I gained most of this experience by designing and maintaining these architectures in production. Along the way I constantly watch and read articles on microservices and lambdas, not always taking the content 100% in but at least just making a note about it somewhere back in my mind.
I will look through my bookmarks a bit later to see if I might be able to give you a few resources that will be helpful on the topic.
It's almost been a year :) but I finally put my method onto paper and blogged about it. I am sure you might have skills by now and might already know this, but I thought I'll leave the link to that blog here for those that also want to solve this type of problem.
rehanvdm.com/serverless/refactorin...
Helpful experience, thanks for sharing! I'm also looking into uses of EventBridge for different architectural applications. The Schema Registry makes it really flexible and easy to work with