
Originally published on my blog: https://www.rehanvdm.com/blog/lru-cache-fallback-strategy
A Least Recently Used(LRU)cache stores items in-memory and evicts the oldest(less used) ones as soon as the allocated memory (or item count) has been reached. Storing data in-memory before reaching for an external cache increases speed and decrease the dependency on the external cache. It is also possible to fallback to in-memory caches like an LRU cache in periods that your external cache goes down without seeing a significant impact on performance.
Conclusion (TL;DR) By leveraging an in-memory cache you reduce pressure on the downstream caches, reduce costs and speed up systems. Consider having an in-memory first policy, instead of having an in-memory fallback cache strategy to see the biggest gains.
The Experiment
I took some time to write a small little program to simulate and compare the following scenarios:
- No caching, fetching data directly from the DB.
- Caching the DB data in Redis.
- Caching the DB data in Redis first (which fails) and falls back to an in LRU memory cache.
- Caching the DB data in an LRU cache first, then reaching for Redis (which fails) if it is not in the LRU cache.
The code can be found here: https://github.com/rehanvdm/lru-cache-fallback-strategy. We won’t go into too many details about the code in this blog, see the README file for more info on the code.
In a nutshell, we are simulating an API call, where we get the user ID from the JWT and then need to look that user up in the DB to get their allowed permissions. I mocked all the DB (200ms) and Redis(20ms) network calls, with the help of environment variables used as hyperparameters.
The program runs 100 executions and in the scenario where Redis fails (3,4) it will fail on the 50th execution. A user id is selected from a seeded random number generator that selects a random user id from a sample size of 10, ensuring a high cache hit ratio. The sample space is kept small so that all data is fetched before Redis goes down at the halfway mark.
When Redis goes down at the halfway mark, we implement a circuit breaker pattern, returning false on the lazy-loaded connect() function that is called inside every Redis command before it is made. Only if 10 seconds have elapsed do we attempt a reconnection and if it fails, we store the last time we tried to connect for the circuit breaker. This is so that we don’t waste time trying to connect on every request and also reduce pressure on the cache.
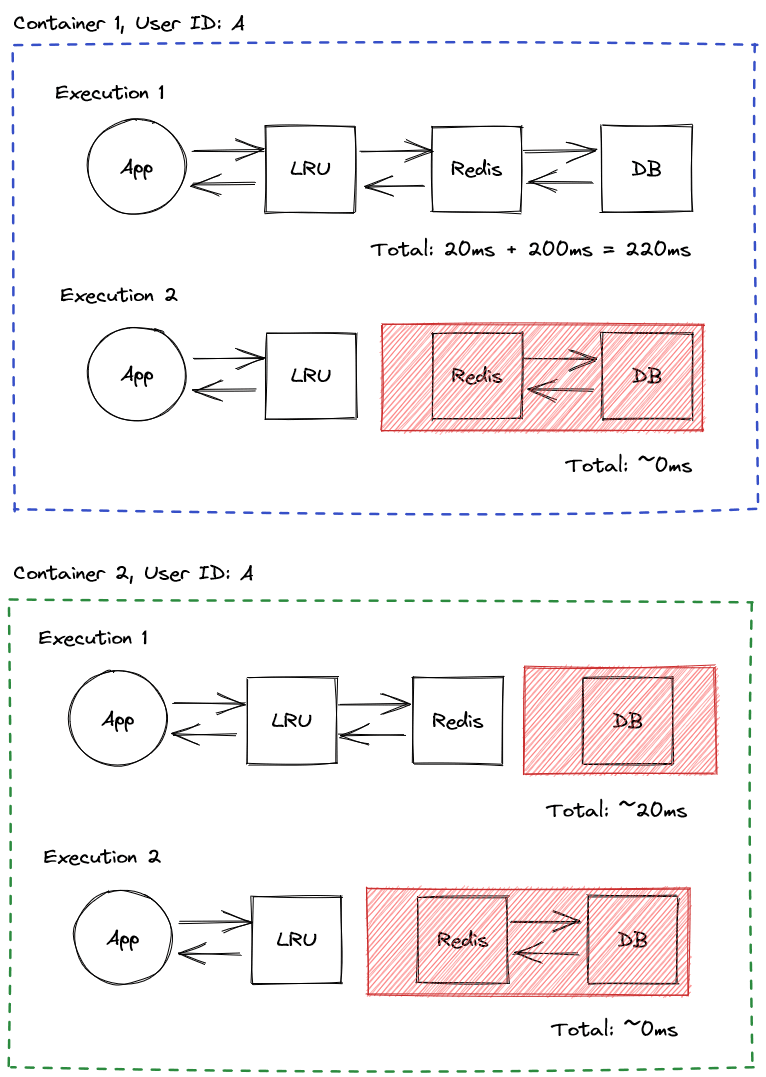
Below is the pseudocode for scenarios 3 , where Redis is used first with fallback to an LRU cache. Not visible here is the environment variables that toggle Redis availability and many other options. The important part I want to highlight here is:
- Redis is queried first, if the user is not found it returns
undefined, but if Redis is down it will try to look the value up in the in-memory LRU cache. If not found it also returns undefined. - If the user is still undefined, then we fetch the user from the DB. The user is then stored in the Redis cache but if the Redis cache is down, we store it in the LRU cache.
The /app/index.mjs contains this logic used for scenarios 3. It is also used for scenario 1 and 2 by setting environment variables that either disable all caching or ensures Redis does not go down.

Scenario 3, accessing strategies with Redis first, the happy path with Redis up
Here the LRU is only used as a fallback for Redis, but we can get better performance if we leverage the LRU cache and put it first as in scenario 4.
The pseudocode for scenario 4 , the LRU cache is used first with fallback to Redis, the pseudo logic is as follows:
- The LRU is queried first, if the user is not found, we query Redis.
- If we still don’t have a user it means Redis does not have it or Redis is down. So we look it up in the DB. Then we store the user in both Redis and the in-memory LRU cache.
The app/index-lru-first.mjscontains this logic used for scenario 4.
Scenario 4, accessing strategies with LRU first, the happy path with Redis up
With this method, we prefer the in-memory cache and only fallback to the slower methods/layers when we don’t have the value. When we get the value, we cache it on all layers so that subsequent executions and other processes can get it without needing to query the source.
This should come as no surprise that it is the fastest method. It can really improve performance of a high throughput system and reduce the dependency as well as back pressure on downward systems.
Results
I used asciichart to draw charts with console.log(...) and then piped the results to files.
Here are the results of each scenario.
Scenario 1 - DB only, ~200ms avg
>> APP VARIABLES
REDIS_GET 0
REDIS_SET 0
DB_FETCHES 100
LRU_SET 0
LRU_GET 0
>> TEST OUTPUTS
TEST_RUN_TIME (s) 21
APP_EXECUTIONS_COUNT 100
APP_EXECUTION_TIME (ms) 214
AVERAGE(APP_EXECUTION_TIME) (ms) 212
>> CHART
405.00 ┤ ╭╮ ╭╮
384.50 ┼╮ ││ ││
364.00 ┤│ ││ ││
343.50 ┤│ ││ ││
323.00 ┤│ ││ ││
302.50 ┤│ ││ ││
282.00 ┤│ ││ ││
261.50 ┤│ ││ ││
241.00 ┤│ ││ ││
220.50 ┤│ ╭╮╭╮ ││ ╭╮ ╭╮ ╭╮ ││
200.00 ┤╰───────────────────────────────╯╰╯╰───────────╯╰────────╯╰──────────────╯╰─────╯╰──────────────╯╰─
Partial log file from db-only.log generated by running npm run app-save-output-db-only
We see that all 100 queries were made against the DB_FETCHES 100, the spikes are when Redis reconnects, which should kinda of not be doing that, I just didn’t want to add another environment variable. We can see that the average APP execution time over the 100 iterations were 212ms from AVERAGE(APP_EXECUTION_TIME) (ms) 212, but is actually closer to 200ms if we ignore the spikes.
Scenario 2 - DB => Redis (no failure), 55ms avg
>> APP VARIABLES
REDIS_GET 100
REDIS_SET 10
DB_FETCHES 10
LRU_SET 0
LRU_GET 0
>> TEST OUTPUTS
TEST_RUN_TIME (s) 6
APP_EXECUTIONS_COUNT 100
APP_EXECUTION_TIME (ms) 31
AVERAGE(APP_EXECUTION_TIME) (ms) 55
>> CHART
318.00 ┼╮
289.10 ┤│
260.20 ┤╰───╮ ╭╮╭╮ ╭╮╭╮ ╭╮
231.30 ┤ │ ││││ ││││ ││
202.40 ┤ │ ││││ ││││ ││
173.50 ┤ │ ││││ ││││ ││
144.60 ┤ │ ││││ ││││ ││
115.70 ┤ │ ││││ ││││ ││
86.80 ┤ │ ││││ ││││ ││
57.90 ┤ │ ││││ ││││ ││
29.00 ┤ ╰─╯╰╯╰─╯╰╯╰───────────────╯╰───────────────────────────────────────────────────────────────────
Partial log file from db-with-redis.log generated by running npm run app-save-output-db-with-redis
In this scenario Redis does not fail, we can see we did 10 DB fetches, 10 Redis SET commands and 100 Redis GET commands.
Scenario 3 - DB => Redis (failure) => LRU, 62ms avg
>> APP VARIABLES
REDIS_GET 50
REDIS_SET 10
DB_FETCHES 20
LRU_SET 10
LRU_GET 50
>> TEST OUTPUTS
TEST_RUN_TIME (s) 6
APP_EXECUTIONS_COUNT 100
APP_EXECUTION_TIME (ms) 0
AVERAGE(APP_EXECUTION_TIME) (ms) 62
>> CHART
425.00 ┼ ╭╮
382.50 ┤ ││
340.00 ┼╮ ││
297.50 ┤│ ││
255.00 ┤╰───╮ ╭╮╭╮ ╭╮╭╮ ╭╮ ││
212.50 ┤ │ ││││ ││││ ││ │╰───╮╭╮╭─╮ ╭╮ ╭╮
170.00 ┤ │ ││││ ││││ ││ │ ││││ │ ││ ││
127.50 ┤ │ ││││ ││││ ││ │ ││││ │ ││ ││
85.00 ┤ │ ││││ ││││ ││ │ ││││ │ ││ ││
42.50 ┤ ╰─╯╰╯╰─╯╰╯╰───────────────╯╰─────────────────╯ ││││ │ ││ ││
0.00 ┤ ╰╯╰╯ ╰─────────────────────╯╰────────╯╰──────
Partial log file from db-with-redis-fail-halfway-with-fallback-lru.log generated by running npm run app-save-output-db-with-redis-fail-halfway-with-fallback-lru
Here we can see that the DB data is fetched, stored in the cache and then read from until the halfway mark, just liked before. Then Redis fails, which forces the app to make calls back to the DB and then cache the response in the in-memory LRU cache. By looking at the baselines for when data was fetched from Redis in the first half, and comparing it with the baseline of when the data was fetched from the LRU cache, we observe that the LRU is much faster.
Why not store data in the LRU first then? That is exactly what we do in scenario 4.
Scenario 4 - DB => LRU => Redis (failure), 27ms avg
>> APP VARIABLES
REDIS_GET 10
REDIS_SET 10
DB_FETCHES 10
LRU_SET 10
LRU_GET 100
>> TEST OUTPUTS
TEST_RUN_TIME (s) 3
APP_EXECUTIONS_COUNT 100
APP_EXECUTION_TIME (ms) 0
AVERAGE(APP_EXECUTION_TIME) (ms) 27
>> CHART
326.00 ┼╮
293.40 ┤│
260.80 ┤╰───╮ ╭╮╭╮ ╭╮╭╮ ╭╮
228.20 ┤ │ ││││ ││││ ││
195.60 ┤ │ ││││ ││││ ││
163.00 ┤ │ ││││ ││││ ││
130.40 ┤ │ ││││ ││││ ││
97.80 ┤ │ ││││ ││││ ││
65.20 ┤ │ ││││ ││││ ││
32.60 ┤ │ ││││ ││││ ││
0.00 ┤ ╰─╯╰╯╰─╯╰╯╰───────────────╯╰───────────────────────────────────────────────────────────────────
Partial log file from db-with-lru-fallback-redis-which-fails-halfway.log generated by running npm run app-save-output-db-with-lru-fallback-redis-which-fails-halfway
Now when Redis fails, we don’t even notice it because all the users has already been cached in the LRU. This method reduces the dependency on Redis and made our demo application twice as fast , going from ~60ms to ~30ms average execution time.
Not all data can be stored indefinitely
In our example, we assumed that the user data does not change and can be cached forever. This is a luxury that most applications can’t make. Most of the time, you would store data in Redis with an expiration, using commands like SET key data and EXPIRE key 60 or just SETEX key 60 data. The data would then be removed from the cache after 60 seconds.
Caching information even for short periods can have a huge impact on high throughput systems. TheLRU library used in the examples also support setting data with an expiration time using set(key, value, maxAge). This means it is possible to set the value both in-memory and in Redis with the same TTL (Time To Live).
One thing to watch out for is that if you get the data from Redis it has already been in the cache for a certain period of time. So you can not store the data in the LRU with the same TTL as when you stored it in Redis. You can either:
-
Use the
TTLRedis command to get the key’s remaining time before expiration and set that in the LRU so that both expire at the same time. -
Make a few tradeoffs and set the TTL the same as for when you stored it in Redis. Then the maximum time that the item can exist in either Redis or the LRU becomes twice as much and there might be stale data for a certain period. This is better explained with an example:
- We set the Redis item with TTL of 60 seconds
- We get the item from Redis on second 59 and set it in our LRU cache for 60 seconds. So the item is “alive” for 2 minutes instead of 1.
- Another process might query Redis and now see that the item does not exist/expired and fetches a new one and stores it. Now two versions of the same item exist across these two process, the first processes has the old version and the new process has the new version.
Another side note, only if you are digging deeper into this. The in-memory LRU library used in this project will check the expiration time when it fetches the object and if it is expired return undefined as if it was not found and deletes it from memory. There is no background process running in the background to check and proactively delete all keys that expired. The prune() command can be called to check the TTL of all items and remove them if necessary, this is only needed in some scenarios where data is set with a TTL and hardly used after that.
Let’s talk about Lambda
Lambda functions usually over-provision on memory to get proportional CPU and network throughput, leaving the memory unused. The majority of workloads are CPU intensive which leads to an over-provisioning of memory to get proportional CPU which reduces execution time and cost.
The AWS Lambda Power Tuning is a great open source tool to help you find the best memory setting to optimize cost & execution time. Many times the cheapest and fastest option is a higher memory setting.

Chart from the output of the AWS Lambda Power Tuning
To prove my previous statement “The majority of workloads are CPU intensive” we observe that the same lambda & program that works with 1024MB also works on 128MB. The only thing that changed is that we have more CPU, network throughput and other proportionally scaled resources.
The unprovisioned memory can be used for caching data in-memory instead of reaching for an external cache every time. This can reduce downstream pressure on these caches, reduce costs and speed up systems.
Conclusion (TL;DR)
By leveraging an in-memory cache you reduce pressure on the downstream caches, reduce costs and speed up systems. Consider having an in-memory first policy, instead of having an in-memory fallback cache strategy to see the biggest gains.

Top comments (0)