Mongoose is the most used ODM with MongoDB and Prisma is a modern ODM/ORM that supports MongoDB in this article we are going to do a complete comparison between these two in various areas!

Prisma vs Mongoose — Designed by Marisa Habibijouybari
I have used both Mongoose and Prisma in production for a few years and I want to share some experiences and information about using these two famous open source libraries. Prisma supports relational databases and it has been a while since it supports MongoDB and I think now is a good time for a comparison between these two!
What you will read in this article
We are going to compare these two libraries in various parameters. Here are the areas of comparison:
- Learning Curve
- Community
- Documentation
- Performance
- Typescript Experience
- Some Interesting Open Issues
Learning Curve
Mongoose Learning Curve
Mongoose has a bit shorter learning curve in my experiments and for using it there are only a few things that you need to know to run your first query using Mongoose! A simple piece of code which is on the home page of Mongoose documentation shows how easy it is to use:
const mongoose = require('mongoose');
// Connection
mongoose.connect('mongodb://127.0.0.1:27017/test');
// Schema
const kittySchema = new mongoose.Schema({
name: String
});
// Model
const Cat = mongoose.model('Cat', kittySchema);
// Option 1
const kitty = new Cat({ name: 'Zildjian' });
kitty.save().then(() => console.log('meow'));
// Option 2
const kitty2 = await Cat.create({ name: 'Zildijan' });
console.log(kitty2)
The first part is the database connection. It returns a promise but you do not need to wait for it.
The second part is the schema definition which is simply the structure of your collection. We use this schema object to create our database Model.
Now for creating a new document in our collection, we have two options that you can see. Option one creating a new object and calling .save() method and the second option is to call Model.create({...}) .
To use it we need to know two concepts of Schemaand Model. We use schema to create our database model. That is the only thing you need to learn to use Mongoose.
Prisma Learning Curve
For using Prisma first thing we need is a prisma.schema file. This is a file type with its own syntax which is not so complicated and you can quickly adapt. This is where we define our collections’ structure. They all exist in this single file(which sounds not good but it has some benefits, for example, you have a version of the database structure in your version control system that you can switch into). Our connection also exists in this file(address of environment variable if we want to be more accurate).
Let’s look at a schema file:
datasource db {
url = env("DATABASE_URL")
provider = "postgresql"
}
generator client {
provider = "prisma-client-js"
}
model Cat {
id String @id @default(auto()) @map("_id") @db.ObjectId
name String?
}
In the database source, we define the name of the env variable that we want to use for our connection string.
The second part is the client and generator address which we did not pass here. Prisma creates a client API based on this schema. Generator is important because each time we change our schema we have to run this command npx prisma generate to update Prisma Client(and typing of client).
We need to run another script to also apply changes of schema to the database. An example is creating a new index. We have to manually apply it to the database using Migrate:
npx prisma migrate dev --name
Now we can use our Prisma client to create a new Cat:
import { PrismaClient } from '@prisma/client'
async function createNewKitty() {
const prisma = new PrismaClient();
const kitty = await prisma.user.create({
data: {
name: 'Elsa Prisma'
},
});
console.log(kitty);
}
Summary of this part: So overall to use Mongoose we need to understand Mongoose Schema and Model. For using Prisma we need to understand schema definition in schema.prisma file, Generator, and Migration. Prisma has a longer learning curve compared to Mongoose.
Community
Both projects have quite a good community which is satisfactory. Mongoose has been around for a long time and it has a big community and eco-system. On the other hand, Prisma has a more active community from my perspective. They have an active Slack channel and also a Discord channel. We should not also underestimate the Prisma Youtube Channel since there is a lot of good content created and they have live sessions after each release and they are presenting changes and answering questions in live.
Probably the difference you see here is because Prisma is backed by a dedicated company that manages these channels.
Summary of this part: Both have a good enough community but Prisma‘s community is much more active(Supporting No-SQL is quite new).
Documentation
Index of Documents of Mongoose and Prisma
Mongoose documentation is nice and sufficient for doing the job. The style of the documentation looks a bit old-fashioned but nothing to complain about. Prisma documentation looks modern. One thing that I find attractive in Prisma documentation is the separation of Concepts and Guides. We have mentioned the Prisma learning curve, and I think good documentation covers you quite well in the process of learning Prisma.
Summary of this part: Both have really good documentation!
Performance
In order to compare these two libraries in terms of performance I am going to compare the queries generated by these two libraries.
Find By ID or something Unique
We are trying to find a document by using something unique like _id.
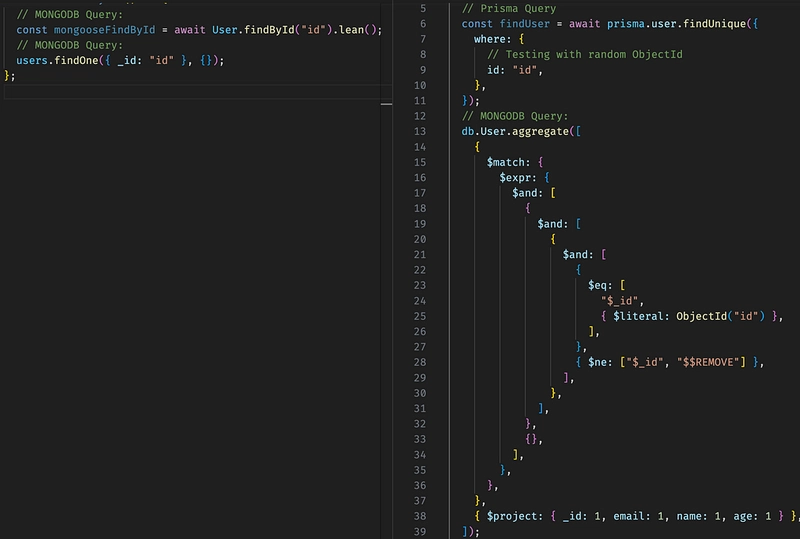
FindById Prisma vs. Mongoose
As we can see the User.findById Mongoose directly translates to findOne({ _id: "_id" }) which is the most efficient way of fetching a document.
For Prisma, it was translated to an aggregation pipeline. The first stage is $match and it contains a few single-element $and phrases and also one empty operation phrase {} . There is also a $ne with using $$REMOVE probably for conditional exclusion of fields. And in the end, we have a $project that exposes the fields that we have used in our Prisma Schema.
Does using an aggregation pipeline make it slower? Practically No, the speed of fetching documents highly depends on using an index(Check out my MongoDB Index Challenge). After the documents have been fetched doing some extra steps like projection or addFields does not take a lot of time unless we have an enormous number of documents.
Another interesting behavior is that if you have some extra fields in the database which does not exist on the schema, Prisma does not show them to you because it uses the projection even when you are not passing the projection object to it. But in Mongoose it returns the whole object from the database. it is not a positive or negative behavior(especially if we are using No-SQL) out of context.
Generally, the Mongoose query generator seems less complicated and straightforward, but in terms of performance, I think it does not make a big difference, since most of the time we want to project some of the fields and not all of them. Especially if we have a findOne like this the projection step in the aggregation pipeline is negligible.
Insert Many Documents
Queries are almost the same, on Mongoose we call insertMany (Be careful that create method generates some insertOne queries), and on Prisma we call createMany and we pass the documents.
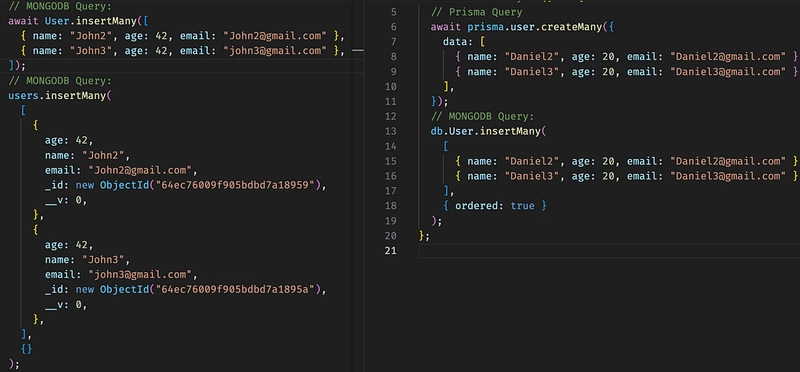
Inserting many documents using Prisma and Mongoose
As we can see both generate the same insertMany queries on MongoDB, the only difference is that Mongoose generates the _id and passes it to MongoDB(We can access _id if we use new User([...])) and it can be sometimes really helpful when we want to use _id in some other objects or pass it to the response of a request.
Update Documents
Updating documents is a bit different. Prisma only allows you to use a unique field for fetching a document. Beforehand it does a find(in Prisma world it is an aggregation pipeline) and returns an error if it cannot find the document! It also does another fetch after the update. So normally you have 2 more steps if you want to use Prisma for updating documents. One fetch beforehand to guarantee that the document is there and one fetch afterward to get the document. Mongoose simply translates your query to a updateMany or updateOne in MongoDB nothing more and nothing less.
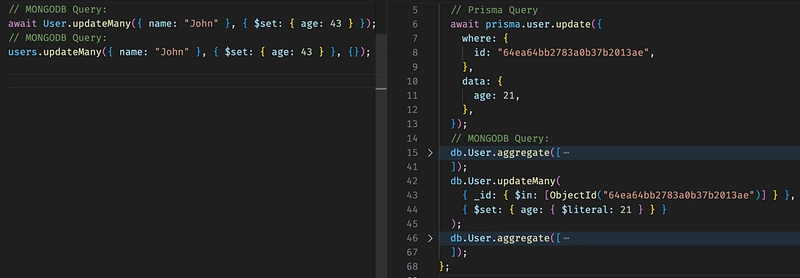
Someone might argue that this is not a common way when you have an ODM or ORM. That’s true and when you fetch the document it gives the object with extra methods and helpers on it that you can change the object and then you can call .save() method on the object to persist it to the database, but on Prisma, there is no option for that, however, you can pass your fetched user object to update method and reassign the object.
Conclusion of this part: Prisma builds queries quite differently (using the Aggregation pipeline). Prisma also does an extra fetch after create or update. For update Prisma forces you to only create a folder with unique fields and also it does the fetch twice once before it and once after it.
Mongoose queries are quite similar(at least now!) to the way that we use MongoDB native driver, which is why I like it. Prisma used to be a SQL-ORM and probably that is the reason why its query builder behaves a bit differently. Prisma could improve itself by letting you customize this fetch behavior or even customize the logic of forcing using unique fields for updates(Let me know in the comments section if there is a way!).
As an end-user, you might not feel that much performance difference in my opinion.
Typescript Experience
Hopefully, with the new version of Mongoose, we can create a type from a Schema.
const userSchema = new mongoose.Schema({
age: { type: Number, required: true },
name: { type: String, required: true },
email: String,
});
type User = InferSchemaType<typeof userSchema>;
With Prisma the Prisma client has already our types based on field definition in Prisma schema:
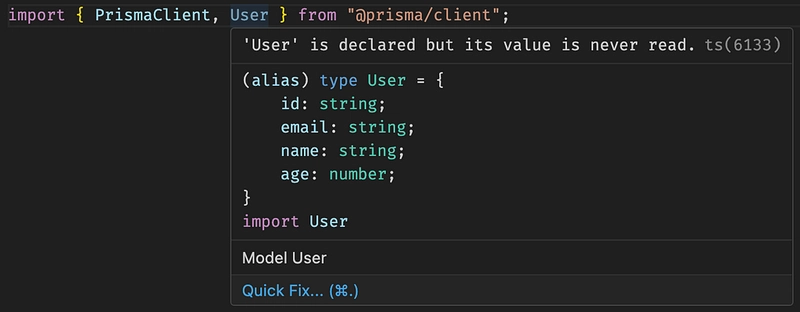
User type in Prisma Client
For Model Types, both give nice Type definitions.
Let’s see the type definitions for queries.
Find Queries Typings
Mongoose gives you the User type as the result of the find query but it unfortunately does not support typing when you project only some of the fields:
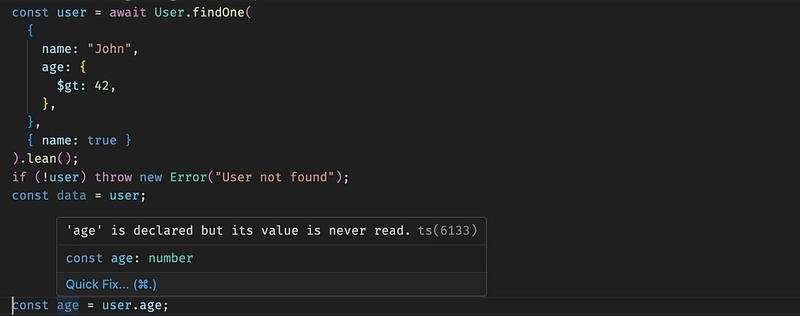
Mongoose Typing in the result of Find Query
To implement projection typing in Mongoose, you need a little bit of Typescript tricks like this:
type FindParameters = Parameters<typeof User.findOne>;
type Filters = FindParameters[0];
function findOneWithTyping<T extends mongoose.ProjectionType<User>>(
filter: Filters,
projection: T
): Promise<Pick<
User,
keyof typeof projection extends keyof User ? keyof typeof projection : never
> | null> {
return User.findOne(filter, projection) as any;
}
async () => {
const user = await findOneWithTyping({ name: "John" }, { name: true });
if (!user) throw new Error("User not found");
const age = user.age; // Error
};
Prisma perfectly supports the typing of projection in find queries.
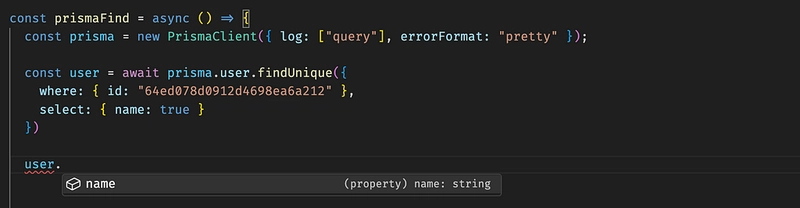
Prisma typing in find queries
Model Relationship Typing Support
Both support relation typings. But Mongoose has the same problem with projection and also you do not have nested projection typings. Prisma does have these capabilities:
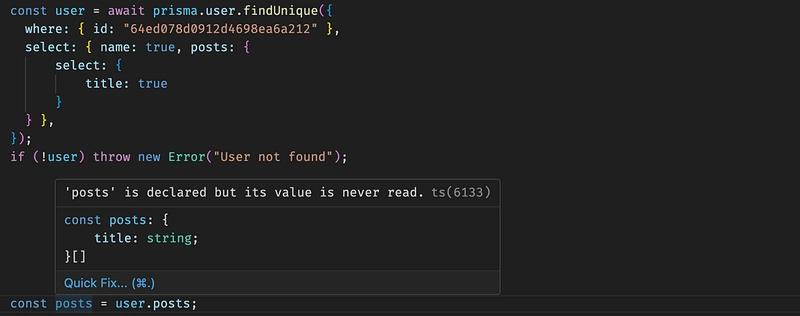
Prisma Nested Projection
Aggregation Typings Support
Unfortunately, Mongoose does not support aggregation pipeline typings and it always types the result as any[].

Mongoose Aggregation Pipeline Typing is always an array of Any
There are two options for an aggregation pipeline building with Prisma. The first one uses aggregate method but it supports only a limited number of aggregation operations but it supports typing with this method:
Prisma Aggregate Method
You can alternatively use aggregateRaw method which supports all aggregation operations, but it does not support aggregations.

Prisma AggregteRaw Method does not support typing
Summary of this part : Both support Typescript to some extent but Prisma supports most use cases. Mongoose is not perfect but with some extra Typescript tricks, you can build what you need.
Some Interesting Open Issues
At the time of writing this article Prisma has 2.7k issues and Mongoose has only 257 open issues. One of the reasons is that Prisma supports different databases and each have a lot of speciel cases and bugs. Also Mongoose has been around for a long time and most bugs are already fixed.
Here we want to check out some of the debatable and interesting open issues of both.
Prisma Open Issues
Add runtime validation to models · Issue #3528: This issue suggests that Prisma could expose the validation function so people can check their object before trying to perform database actions. Also, some people might want to have some custom validations. This issue is open from 2020 I think. Mongoose already has this feature. I think if Prisma is not implementing this, then you could have a little bit of duplication for validation using Zod or something else.
Soft deletes (e.g. deleted_at) · Issue #3398: This is a very interesting idea! Prisma does not support it directly at the schema level but there are some ways to implement this using Middlewares. Mongoose has also some workarounds that work with hooks.
Support for splitting Prisma schema into multiple files · Issue #2377: This is open from 2020, people want to split their schema into multiple files. Some people have suggested some scripts to do that. You can even implement the script yourself for appending and mixing multiple files into one schema.
Add exclude in the query arguments · Issue #5042: This is also open for a long time and I think for MongoDB it is important to have this since it does support exclusion projection.
Support for a Union type · Issue #2505: Supporting union types is also one of desirable features that users asked Prisma. They want to use multiple types(table or collection).
Subscriptions/real-time API support · Issue #298: Having subscriptions and real time support is also another requested feature. In my perspective it is noramlly a ORM/ODM does not need to give this feature since its job is something else. But if they provide something it will save a lot of poeple a lot of time.
Nested relations using createMany · Issue #5455: This feature request is asking for creating nested records. For example a User could have some posts. Normally you create the user and then you create the posts and in the end you make the connection. But what if you could create the user and the posts at the same time? In my perspective this is not really common use case and I needed this feature at the time of implementing some database migrations and structural changes in the database, but looks like so many people supported the request.
Mongoose Open Issues
Mongoose execution time increased 2 times after upgrading 4 to 6 #11380 Mongoose had a performance issue after Mongoose 6 release and this was not due to mongo-native-driver upgrade. They are still investigating this issue.
new feature: virtual async #5762 Virtuals are simply virtual fields that you can set and they exist in your object but sometimes not in your database. This feature does not support async functions and as a result people have to use some other workarounds. In my opinion it is not a major issue and you can find some good workarounds in the issue discussions.
Multi-level discriminators #2851 Discriminators help implement inheritance in Mongoose model. This feature asks for the feature of multiple discriminators.
[Feature] option to disable running pre/post hooks #8768 This requests simply disable hooks.
Optimize nested populate #3812 In a case it generates two separate queries which could be improved but it is still not implemented.
Conclusion
Both libraries are really good and well-documented and well-supported and you can easily do the job with both of them. The choice really depends on your values and the context. If you value stability more than other things I think Mongoose could give you that and it will never surprise you(negative or positive). If can tolerate some minor bugs and you are curious, maybe Prisma is a better choice for you and it will definitely suprise you with new features with each release and after a while it could be your choice no matter which database you are using.

Top comments (0)