As data becomes the cornerstone of the digital age, efficiently managing and scaling databases has become paramount for global businesses. Faced with the exponential growth and evolving nature of data, traditional database architectures struggle to scale effectively.
Aurora Limitless Database:
Amazon Aurora Limitless Database, a revolutionary cloud-based offering built on advanced scalability and elasticity, promises to redefine big data management.
Imagine a database that shatters scalability barriers, effortlessly handling millions of write transactions per second and storing petabytes of data. That's exactly what Amazon Aurora Limitless Database promises. It's a game-changer for the world of relational databases, designed to tackle the challenges of massive, write-intensive workloads.
Architecture:
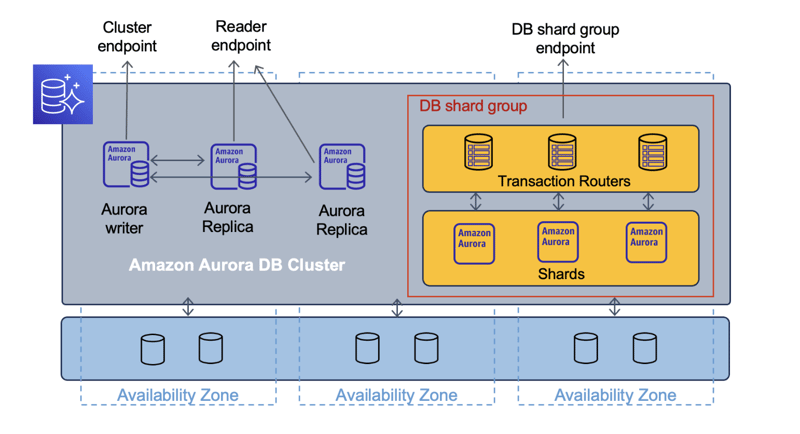
The architecture of Amazon Aurora Limitless Database is a two-layered masterpiece, designed for extreme scalability and efficient handling of massive data volumes. Here's a breakdown of its key components:
The architecture of Amazon Aurora Limitless Database is a two-layered masterpiece, designed for extreme scalability and efficient handling of massive data volumes. Here's a breakdown of its key components:
Layer 1: Transaction Routers:
- These act as the entry point for all client requests.
- They parse SQL commands, manage metadata, and orchestrate data access across the system.
- Think of them as traffic controllers, directing inquiries to the appropriate shards for optimal performance.
Layer 2: Shards:
- These are individual Aurora PostgreSQL DB instances that store subsets of the entire data set.
- The number of shards automatically scales up or down based on workload demands.
- Data is partitioned and distributed across shards based on a designated shard key (a column in your table).
- Shards handle read and write operations for their assigned data segments.
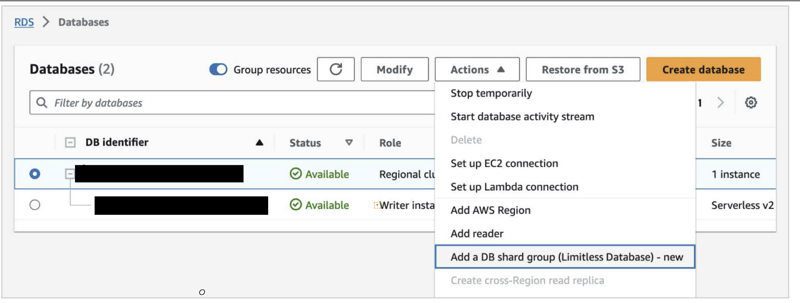
Create Amazon Aurora Limitless Database:
As part of the creation workflow for an Aurora cluster, choose the Limitless Database compatible version in the Amazon RDS console or the Amazon RDS API. Then you can add a DB shard group and create new Limitless Database tables. You can choose the maximum Aurora capacity units (ACUs).
After the DB shard group is created, you can view its details on the Databases page, including its endpoint.
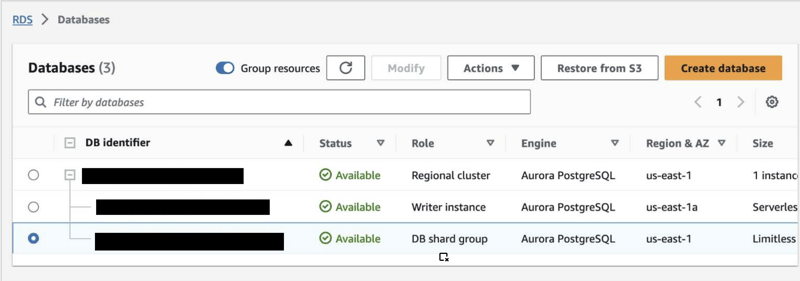
To use Aurora Limitless Database, you should connect to a DB shard group endpoint, also called the limitless endpoint, using psql or any other connection utility that works with PostgreSQL.
There will be two types of tables that contain your data in Aurora Limitless Database:
Sharded tables – These tables are distributed across multiple shards. Data is split among the shards based on the values of designated columns in the table, called shard keys.
Reference tables – These tables have all their data present on every shard so that join queries can work faster by eliminating unnecessary data movement. They are commonly used for infrequently modified reference data, such as product catalogs and zip codes.
Once you have created a sharded or reference table, you can load massive data into Aurora Limitless Database and manipulate data in those tables using the standard PostgreSQL queries.
Conclusion
While it's still in preview, Aurora Limitless is a glimpse into a data-driven future where limitations are relics of the past. It's an invitation to push the boundaries, to dream bigger, and to build applications that bend the very fabric of what's possible.
So, are you ready to break the data chains and join the Limitless revolution? Dive deeper, explore its functionalities, and see how it can empower your data journey. Remember, Aurora Limitless isn't just a database; it's a key to unlocking the full potential of your data, and ultimately, your future.





Top comments (0)