AWS Bedrock, a fully managed service, unlocks access to foundation models (FMs) for creating advanced generative AI applications. It was made generally available for use in October 2023. It offers a choice of high-performing FMs from leading AI companies including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon.
With Amazon Bedrock, you are in control of your data, and all your inputs and customizations remain private to your AWS account. Your data, such as prompts, completions, and fine-tuned models, is not used for service improvement. Also, the data is never shared with third-party model providers.
One of its key benefits is the liberty to customize its models using techniques like fine-tuning using your private data.
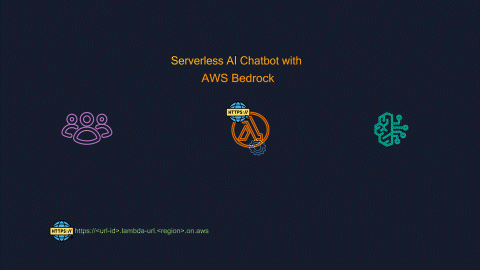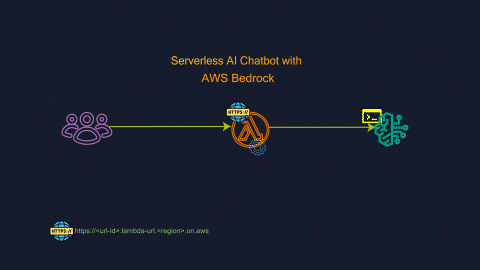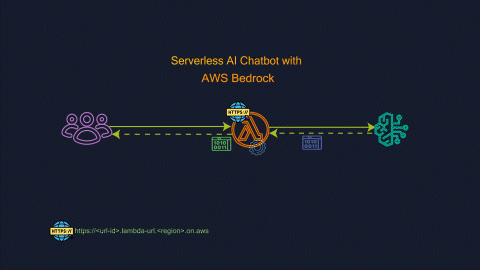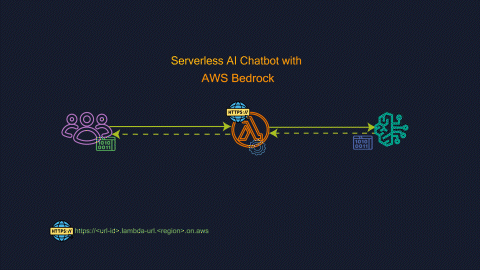
In this blog, we will explore the steps to build a Generative AI Chatbot utilizing Amazon Bedrock.
The idea is to use Amazon bedrock as the Generative AI provider and stream the response generated by the service to the user.
To achieve this, we need to delve into three critical concepts:
AWS Lambda function URL.
AWS Lambda response streaming.
AWS Bedrock foundation model Anthropic Claude v2.
If you are a visual learner, check out my youtube video :
AWS Lambda function URL
AWS Lambda function URL exposes a dedicated HTTPS endpoint which can be used to invoke a lambda function. Organisations adopting microservices architectures using serverless functions can leverage this feature to trigger the lambda function. This feature simplifies the process by eliminating the need for an API Gateway configuration to trigger a Lambda function. In our scenario, we will utilize the function URL to invoke a Lambda function, which in turn triggers Amazon Bedrock APIs.
We will be using SAM(Serverless Application Model) to deploy our application. In order to create a function URL you need to create a resource of type AWS::Lambda::Url and attach it your lambda function in your sam template file as shown in the code snippet below.
You can also add authentication by configuring the AuthType: AWS_IAM which restricts the endpoint to be triggered only by authenticated users and roles having the required resource based policies.
GenerativeAIFunctionUrl:
Type: AWS::Lambda::Url
Properties:
TargetFunctionArn: !Ref GenerativeAIFunction
AuthType: AWS_IAM
When you create the above resource attached to a Lamda function, SAM exposes an endpoint for your Lambda function.
In the next section we will use function URL in conjunction with Lambda response streaming
AWS Lambda response streaming
In early 2023, AWS announced support for response payload streaming. Response streaming is a new invocation pattern that lets functions progressively stream response payloads back to clients. This feature brings two major benefits
Response is streamed to the users as it becomes available improving the time to first byte performance.
Function can return larger payloads and perform long-running operations while reporting incremental progress.
In our scenario this feature will help to stream bedrock response back to the client.
Response streaming enables sending responses larger than Lambdas 6 MB response payload limit up to a soft limit of 20 MB. This increased limit can be useful in case the model generates a larger payload.
Using Lambda response streaming with function URLs
You can configure a function URL to invoke your function and stream the raw bytes back to your HTTP client via chunked transfer encoding. You configure the Function URL to use the new InvokeWithResponseStream API by changing the invoke mode of your function URL from the default BUFFERED to RESPONSE_STREAM
GenerativeAIFunctionUrl:
Type: AWS::Lambda::Url
Properties:
TargetFunctionArn: !Ref GenerativeAIFunction
AuthType: AWS_IAM
InvokeMode: RESPONSE_STREAM
The RESPONSE_STREAM mode, when combined with the streamifyResponse() decorator, allows your function to efficiently stream payload results as they become available. Lambda invokes your function using the InvokeWithResponseStream API. If InvokeWithResponseStream invokes a function that is not wrapped with streamifyResponse(), Lambda does not stream the response. We will see how to use this in the code at the end.
Now lets see how AWS Bedrock can be used in conjunction with the above two concepts.
AWS Bedrock foundation model Anthropic Claude v2
We will be using Anthropics Claude model since it supports streaming response back to the client. In order to work with AWS Bedrock you need to complete the following steps.
Get access to the foundation model
When you go to the aws bedrock console, you would need to go to the Model Access tab and request access for the model you wish to use. After raising the access it might take some time for the access to be granted.
Generate payload from the playground
Once you have gained access you can use the model from the playground in the aws console. You can send any prompt and get response back from the foundation model. You can not only play around with the different inference configurations but also see the payload if you were to use the AWS Bedrock API in your code using the View API request option. Use this option to get the payload for your lambda function. Before we go ahead lets take a minute to understand the inference configuration and how it impacts the response received from the model.
Following are the inference parameters you can tweek:
Temperature: This parameter controls how language models creates the next word in a sequence which is measured based on probability. If you keep this value closer to zero the model will generate higher probability words.
Top K: This parameter sets a cut off value within which the probability distributed words should be used.
Top P: It defines a cut off based on the sum of probabilities of the potential choices.
Max tokens to sample: The Max tokens to sample parameter allows you to specify the desired length of the models response.
Lambda function permission
Give lambda function the required permissions to access the foundation model. In this case the function would require InvokeModelWithResponseStream IAM policy access. We should also focus to provide granular access for best practices and hence provide this access to the claude-v2 resource only since that is the model we will be using.
Policies:
- Statement:
- Effect: Allow
Action: 'bedrock:InvokeModelWithResponseStream'
Resource: 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2'
SAM Template and Lambda function handler
Now after configuring the Function URL, changing the invoke type to RESPONSE_STREAM and completing all the pre requisites to use the anthropic claude v2 model. Lets see the SAM template and code within the lambda function to make this come to life.
Following is the SAM template
AWSTemplateFormatVersion: 2010-09-09
Transform: 'AWS::Serverless-2016-10-31'
Resources:
GenerativeAIFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/
Handler: index.handler
Runtime: nodejs18.x
MemorySize: 128
Timeout: 600
Policies:
- Statement:
- Effect: Allow
Action: 'bedrock:InvokeModelWithResponseStream'
Resource: 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2'
GenerativeAIFunctionUrl:
Type: AWS::Lambda::Url
Properties:
TargetFunctionArn: !Ref GenerativeAIFunction
AuthType: AWS_IAM
InvokeMode: RESPONSE_STREAM
Outputs:
StreamingBedrockFunction:
Description: "Streaming Bedrock Lambda Function ARN"
Value: !GetAtt GenerativeAIFunction.Arn
StreamingBedrockFunctionURL:
Description: "Streaming Bedrock Lambda Function URL"
Value: !GetAtt GenerativeAIFunctionUrl.FunctionUrl
The first part holds the details of the lambda function i.e. Lambda handler, runtime, memory, policy etc.
Next we can see the details of generating a function URL along with response streaming.
In the outputs we can see it generate the Lambda function ARN and function URL. We will be using the function URL in our frontend to trigger the lambda function.
Lets understand the code to see what exactly is happening here.
'use strict';
const {
BedrockRuntimeClient,
InvokeModelWithResponseStreamCommand} = require('@aws-sdk/client-bedrock-runtime'); // ES Modules import
const client = new BedrockRuntimeClient();
const util = require('util');
const stream = require('stream');
const pipeline = util.promisify(stream.pipeline);
const { Transform } = require("stream");
exports.handler = awslambda.streamifyResponse(async (event, responseStream, context) => {
const requestBody = JSON.parse(event.body);
const metadata = {
statusCode: 200,
headers: {
"Content-Type": "text/plain"
}
};
const prompt= requestBody.prompt;
const input = {
body: `{"prompt": "Human: ${prompt}\\nAssistant:","max_tokens_to_sample": 300 ,"temperature": 1,"top_k": 250,"top_p": 0.999,"stop_sequences":["\\n\\nHuman:"],"anthropic_version": "bedrock-2023-05-31" }`,
modelId: 'anthropic.claude-v2',
accept: '*/*',
contentType: 'application/json'
};
console.log(input);
const command = new InvokeModelWithResponseStreamCommand(input);
const data = await client.send(command);
const decodedData = new Transform({
objectMode: true,
transform(body, encoding, callback) {
try{
const parsedData = JSON.parse(new TextDecoder().decode(body.chunk.bytes));
//console.log(parsedData.completion);
this.push(parsedData.completion);
callback();
} catch (error) {
callback(error); // Handle parsing errors
}
},
});
responseStream = awslambda.HttpResponseStream.from(responseStream, metadata);
await pipeline(data.body, decodedData,responseStream)
.then(() => {
console.log('Pipeline completed');
})
.catch((error) => {
console.error('Pipeline error:', error);
});
});
First we can see that the function handler is using the streamifyResponse decorator with one of the input parameters being responseStream. This parameter is used to stream the response back to the client.
Next we take the prompt from the request received from the client and stitch into the payload used to invoke the foundation model. You can use a frontend application from where you send the prompt to the endpoint exposed by the Function URL or you can keep it simple and trigger it using Curl or Postman.
Next we invoke the AWS Bedrock InvokeModelWithResponseStreamCommand API which receives data from anthropic claude V2 model in streaming mode.
In order to send the data received from bedrock we need to decode the chunk of data received from the API and send it to the responseStream. We use the transform streams construct to read the incoming stream, transform and send the data to the outgoing stream.
Once the sam template and lambda handler is configured as above we build and deploy the code via SAM. It will give an endpoint to trigger the Lambda function. This endpoint can then be used in the frontend application simulating the behavior of a chatbot assistance.
You can test it in two ways:
- First is via curl using the following command
curl -X POST -H "Content-Type: application/json" -d '{"prompt":"What is chatbot assistant?"}' <<AWS_FUNCTION_URL>> --user <<AWS_CREDENTIALS>> --aws-sigv4 'aws:amz:us-east-1:lambda' --no-buffer
Note: If you do not use the -no-buffer flag curl will buffer the response before displaying it back to you defeating the entire purpose of streaming.
- You can design your own frontend application where you use the endpoint. I am using streamlit python framework to build our frontend. You can check out this link to understand the code StreamLit Coversation App Docs We simply use the code given in the above link and replace the chatGPT call mentioned with our own endpoint exposed. And voila, we have created a chatbot for ourselves.
Costing
You might incur cost based on three factors
First the cost of runnning the lambda function with the configuration you prefer might incur some cost.
Since we are using response streaming. Every request that processes data larger than 6mb might have an impact on the cost of the lambda function.
The generative model you use has its own pricing which you will have to consider while implementing this design.
You can find the code for the bedrock lambda function and the frontend python application at the following github repository with all the details to run the application.
Github:AI Assistant Code
Heres a sneak peek into how you can set up a serverless AI assistant, tailored for either your personal use or your business needs. Theres a whole world of possibilities with this! Im really curious to see how you might use it, so do share your thoughts and ideas in the comments. And hey, if you need a bit more help or just want to chat, feel free to hit me up on LinkedIn! LinkedIn
Thank you for reading! Stay tuned and follow my blog for more updates and engaging content.
Originally published athttps://kloudbuddy.io on March 7, 2024.





Top comments (0)