
In this course I have demonstrated everything using the Vault development server. The development server is excellent for learning and for quick prototyping. It is not intended for production use. Apart from using Vault to configure auth methods, store secrets, write policies, etc, there is a lot to do when it comes to the Vault architecture. How to configure Vault in a production scenario, as well as how to actually start up a server or cluster, is a big topic. In this post we will look at a few things related to the architecture of Vault and a bit about how Vault functions under the hood.
Explain Vault architecture makes up the ninth objective in the Vault certification journey. This objective covers the following sub-objectives:
- Describe Shamir secret sharing and unsealing
- Describe seal/unseal
- Describe storage backends
- Describe the encryption of data stored by Vault
- Describe cluster strategy
- Be aware of replication
- Describe the Vault agent
- Describe secrets caching
- Be aware of identities and groups
- Explain response wrapping
- Explain the value of short-lived, dynamically generated secrets
I have rearranged the order of the sub-objectives to make this post a more coherent story. I have also combined a few sub-objectives into one because they were basically covering the same thing.
Before I start to go through the sub-objectives I would like to briefly introduce how you start a Vault server that is not the development server, because we will see this at a few places in this post.
You write one or more Vault server configuration files in HashiCorp Configuration Language (HCL). Then you can start the server using a modified vault server command:
$ vault server -config=my-server-config.hcl
You could provide multiple -config flags to load multiple configuration files:
$ vault server -config=config01.hcl -config=config02.hcl -config=config03.hcl
What goes inside a configuration file? This depends on how you want to configure your Vault server, and we will not go into depth on all the various options. A sample configuration file is shown below:
ui = true
cluster_addr = "https://127.0.0.1:8201"
api_addr = "https://127.0.0.1:8200"
storage "consul" {
address = "127.0.0.1:8500"
path = "vault/"
}
listener "tcp" {
address = "127.0.0.1:8200"
tls_cert_file = "/path/to/full-chain.pem"
tls_key_file = "/path/to/private-key.pem"
}
As in all HCL there are arguments and blocks1. The configuration starts with a few arguments specifying that we would like to enable the UI (ui = true), and we say that our cluster address is https://127.0.0.1:8201 and API address is https://127.0.0.1:8200. Following the arguments we have two common blocks seen in most (all?) configuration files:
- The
storageblock specifies what storage backend (more on storage backends later in the post) we want to use. In this case we use theconsulstorage backend. The arguments in this block depends on what type of storage backend we select. - The
listenerblock specifies how we can reach this specific Vault server. In this case we want to use TLS so we need to provide details on where the TLS certificate and key is located.
This was a very short introduction to starting up a Vault server for real, but we'll see some more examples further down in this post.
Describe Shamir secret sharing and unsealing and Describe seal/unseal
When you initialize a new production Vault server it starts up in a sealed state. It is not possible to perform any actions in the Vault cluster when it is in the sealed state, except for one important operation: unsealing the Vault server. When the server is sealed it knows where its physical storage is and how to access it, but it does not know how to decrypt the data in this storage.
The data in the storage is encrypted by a key, the data encryption key (DEK). This key is in turn encrypted by the root key, or master key. Unsealing Vault is the process of obtaining the plaintext root key in order to decrypt the DEK and in turn to decrypt the data stored on disk.
How does the unseal process work? By default, Vault uses the Shamir's Secret Sharing algorithm in order to split the root key into a number of unseal keys. In order to reconstruct the root key you need a certain number of these unseal keys. The idea here is that you would give each unseal key to different people, and no single person would be able to get ahold of the root key. Here I would like to mention that there is a process known as auto-unseal which involves using a trusted cloud provider key store to automate the unseal process. I will not cover auto-unseal in this post, but you can read more about it here.
To demonstrate how the unseal process works we'll start up a Vault server. In order to do this we need a Vault server configuration file:
// config.hcl
// use in-memory storage, not intended for production!
storage "inmem" {}
// http listener on 127.0.0.1:8200
listener "tcp" {
address = "127.0.0.1:8200"
tls_disable = "true"
}
// we can communicate with Vault on 127.0.0.1:8200
api_addr = "http://127.0.0.1:8200"
// let's enable the UI
ui = true
Using my configuration file I can start up my Vault server locally:
$ vault server -config=config.hcl
Now I have a running Vault server, but it is sealed and I do not have any token to authenticate to Vault with. I can check the status of my server using the following command:
$ vault status
Key Value
--- -----
Seal Type shamir
Initialized false
Sealed true
Total Shares 0
Threshold 0
Unseal Progress 0/0
Unseal Nonce n/a
Version 1.14.0
Build Date 2023-06-19T11:40:23Z
Storage Type inmem
HA Enabled false
The output tells me that my server is not initialized (Initialized=false), and that it is sealed (Sealed=true). To initialize our Vault server we run the following command:
$ vault operator init
Unseal Key 1: eu0+iP+Fs71au7YwZN2lo/UpAJDEGdolCLMCiwl0WKCX
Unseal Key 2: 1wYpo/9jyzQSelnXzK4SkSfhpFQe2K+jNSnRGrqQUE1u
Unseal Key 3: 7NXC2Gvded4qyPukMqcYKJRcsj5OVA5KSmdQ45vqcSg8
Unseal Key 4: U25S/3rHC9m/GoRqOs5MoAkAv023W4kcFemzfmfMYGlq
Unseal Key 5: XCrlRf1z3eDBoudSRUwxDPAvyM5dGvwwe7mHy1TjLHal
Initial Root Token: hvs.c3esiYi0AJNSzdn1YxYsJtjx
The output contains five unseal keys and one initial root token. If we check the status of our server again we see the following:
$ vault status
Key Value
--- -----
Seal Type shamir
Initialized true
Sealed true
Total Shares 5
Threshold 3
Unseal Progress 0/3
Unseal Nonce n/a
Version 1.14.0
Build Date 2023-06-19T11:40:23Z
Storage Type inmem
HA Enabled false
The server is now initialized, but it is still sealed. We see that Total Shares is set to 5 and Threshold is set to 3. The Unseal Progress is 0/3. What this information tells us is that to unseal Vault we must use three of the five available unseal keys. To start the unseal process, copy one of the unseal keys and run the following command:
$ vault operator unseal
Unseal Key (will be hidden): *****
Key Value
--- -----
Seal Type shamir
Initialized true
Sealed true
Total Shares 5
Threshold 3
Unseal Progress 1/3
Unseal Nonce 11a275e7-0e20-262c-7c65-30d4859c8357
Version 1.14.0
Build Date 2023-06-19T11:40:23Z
Storage Type inmem
HA Enabled false
The Unseal Progress changed to 1/3. We can continue the process by issuing a new vault operator unseal command:
$ vault operator unseal
Unseal Key (will be hidden): *****
Key Value
--- -----
Seal Type shamir
Initialized true
Sealed true
Total Shares 5
Threshold 3
Unseal Progress 2/3
Unseal Nonce 11a275e7-0e20-262c-7c65-30d4859c8357
Version 1.14.0
Build Date 2023-06-19T11:40:23Z
Storage Type inmem
HA Enabled false
Almost there, the Unseal Progress is now 2/3. We can run the last unseal command:
$ vault operator unseal
Unseal Key (will be hidden): *****
Key Value
--- -----
Seal Type shamir
Initialized true
Sealed false
Total Shares 5
Threshold 3
Version 1.14.0
Build Date 2023-06-19T11:40:23Z
Storage Type inmem
Cluster Name vault-cluster-206551a5
Cluster ID d15ae1cf-bff4-c53d-8131-c037cea78999
HA Enabled false
Now Sealed reports false, and our Vault server is ready to go. We can set our root token in an environment variable and see if we can interact with Vault:
$ export VAULT_TOKEN=hvs.c3esiYi0AJNSzdn1YxYsJtjx
$ vault secrets list
Path Type Accessor Description
---- ---- -------- -----------
cubbyhole/ cubbyhole cubbyhole_0bce5c18 per-token private secret storage
identity/ identity identity_bb8c3d8d identity store
sys/ system system_4afad89f system endpoints
To recap, what we did was to use three unseal keys to reconstruct the root key in order to decrypt the DEK and finally be able to read the data and configuration stored in Vault.
Describe storage backends
As you might have realized Vault needs to store its configuration and data somewhere. This is the purpose of a storage backend. HashiCorp officially supports two storage backends: integrated storage (Raft) and HashiCorp Consul. For the record it is possible to use other storage backends. In this post I will only mention integrated storage and Consul.
When I have been using the development cluster for demonstrations all the configuration and data have been stored in-memory. This is a bad idea because as soon as I shut my development server down all the configuration and data is gone. This is the reason why we need a storage backend: we want to be able to persist all the important things we do in Vault so that a simple shutdown of a server doesn't wipe our Vault history clean.
The storage backend is untrusted storage. This might sound like a strange statement, but it simply means that the storage backend is external to Vault proper and thus not trusted. It is used purely for storing encrypted data.
If you use integrated storage with Raft the data is persisted on some volume attached to the machine where Vault is running. This could be a virtual hard-drive attached to a virtual machine running in the cloud, or a persistent volume attached to a pod in a Kubernetes cluster. To configure your Vault server to use integrated storage you would add a block similar to the following to your cluster configuration file:
// config.hcl
// ... the rest of the config omitted ...
cluster_addr = "http://localhost:8201"
storage "raft" {
path = "/opt/vault/data"
node_id = "my-first-node"
}
Here we have specified that the data should be stored at the path /opt/vault/data. Note that this path is on the OS your Vault server is running, it is not a Vault path. We must also provide the cluster address in cluster_addr. This is because Raft is created for a distributed system, i.e. for running Vault as a cluster of nodes. The cluster_addr is the address where the nodes in the cluster can communicate with each other.
It is not clear from my example configuration file above what kind of storage media will be used. It is recommended to use a storage media with high IOPS to handle everything Vault throws at it. You will probably have to run tests to measure the performance of your storage media to determine how much IOPS your environment demands.
HashiCorp Consul is a separate tool offered by HashiCorp. The setup is more complex than integrated storage because here you will need to run a separate Consul cluster together with your Vault cluster. I will not go into any details of Consul2. In fact, in the Vault documentation you can find many recommendations to use integrated storage with Raft instead of using Consul. This is simply because the setup with Consul will be more complex, with more moving parts that can break and cause problems in your environments. Also note that if you go with Consul, it is recommended to use a dedicated Consul cluster specifically as the storage backend for Vault. So if you are already running Consul for another purpose do not reuse the same cluster.
Describe the encryption of data stored by Vault
All data stored by Vault is encrypted using the Data Encryption Key (DEK). Vault stores data in a storage backend. The storage backend is not part of the core Vault architecture, it lives outside of Vault. Vault encrypts the data before it leaves Vault proper and ends up at the storage backend. This is because the storage backend is not trusted, it should never see any unencrypted data.
The concept of Vault not sending out data unencrypted outside its core is known as the cryptographic barrier. Data that passes the cryptographic barrier is encrypted using the DEK. Note however that this does not apply for data that we request when we do e.g. vault kv get kv/database/password to read a secret - because as we have seen we get the plaintext data back.
The point of the cryptographic barrier is to protect the data at rest. It would be bad if someone would get ahold of the storage media where we store all our Vault data! Thus the data must be encrypted.
Describe cluster strategy
This subsection will briefly outline the recommended cluster architecture for Vault in production. As mentioned in the previous section HashiCorp recommends that you use integrated storage with Raft as your storage backend instead of Consul. We'll use Raft in this subsection.
Today it is common to run Vault in a public cloud environment, so the following discussion applies to that situation.
A typical cloud provider (e.g. AWS, Azure, GCP) has a presence in several locations across the globe. These locations are called regions. Each region usually consists of three or more zones. A zone is a data center consisting of one or more buildings housing the networking, CPU, memory, and storage, that make up a cloud provider. The zones are separated by a certain distance from each other, far enough to guarantee that a natural disaster or infrastructure disturbance won't take out two or more zones at the same time. The purpose of zones is to allow you to design highly available and redundant architectures.
HashiCorp recommends that you run five Vault nodes in a cluster, spread out over at least three zones in a region. An example of what this looks like in Azure is shown in the following figure:
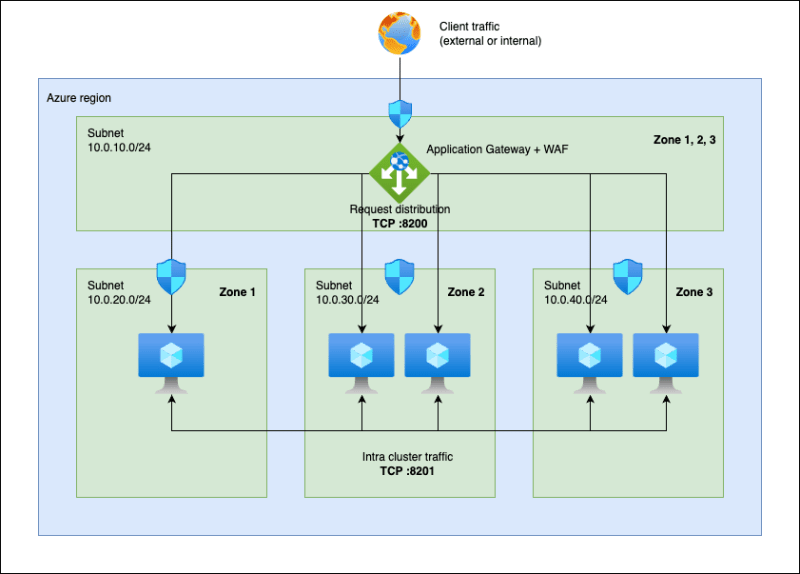
In this architecture we have five nodes (virtual machines) divided among three subnets in a virtual network (the virtual network itself is not shown in the figure). Each subnet is in a different zone of the region3. In front of the cluster we have a separate subnet containing an application gateway load balancer (AGW) with a web application firewall (WAF). The AGW is zone-redundant, meaning it is present in each zone of the region. Each subnet has its own network security group (NSG) to control what traffic is allowed to flow in and out of the subnet. The Vault nodes are not directly reachable from the outside, all traffic must go through the AGW/WAF. This is a good base design that follows HashiCorp recommendations but in a real environment this would probably be a small piece of a much larger infrastructure.
Why is this a recommended architecture? It allows for the loss of a whole zone, e.g. due to a power outage or a natural disaster that renders the data center unreachable. If we lose a zone we lose up to two Vault nodes, leaving us with at least three remaining nodes. This is important because part of the internal machinery of Raft requires at least three nodes to be able to elect a new leader node if the current leader node is lost. This architecture also allows for up to two simultaneous node failures to occur. These kinds of failures do happen, so you must be prepared for them.
What happens if the whole region would fail? Is this even something that could happen? It can indeed happen. The most likely scenario would be that the cloud provider make a bad deployment that affects a whole region at once. It is unlikely that all the zones would be affected by random events that take them offline at the same time. How should you prepare for a regional failure? The solution involves having multiple clusters, spread out in different regions. The details are beyond the scope of what we need to learn, but it involves setting up clusters and two or more regions and configuring replication between these clusters.
Be aware of replication
At the end of the last section I mentioned the word replication. There are two purposes of replication that you should be are of:
- Disaster recovery replication
- Performance replication
No matter what type of replication we consider the main principles are the same. The unit of replication is a cluster. There is one leader, or primary, cluster and any number of follower, or secondary, clusters. Most data is replicated asynchronously from the primary cluster to the secondary clusters.
In disaster recovery replication most data, including configuration, policies, tokens, leases are shared between the primary and the secondary clusters. This type of replication is meant to support continuous operation in case of failure in the primary cluster. Traffic could quickly be shifted over to the secondary cluster and clients would only detect a minor glitch before things start working again. A disaster recovery replication cluster should not receive any traffic during normal primary cluster operation.
In performance replication the underlying configuration, policies, and some secrets are shared among primary and secondary clusters. What is not shared however is tokens and secret leases. The secondary clusters can serve client requests. Each cluster in this setup keeps track of their own tokens and leases. This could at times lead to the need to reauthenticate to Vault in case traffic is shifted from one cluster to another for some reason.
In summary, I recreate the table from the Vault documentation that highlights the differences between the two types of replication:
| Capability | Disaster Recovery | Performance Replication |
|---|---|---|
| Mirrors the configuration of a primary cluster | Yes | Yes |
| Mirrors the configuration of a primary cluster’s backends (i.e., auth methods, secrets engines, audit devices, etc.) | Yes | Yes |
| Mirrors the tokens and leases for applications and users interacting with the primary cluster | Yes | No. Secondaries keep track of their own tokens and leases. When the secondary is promoted, applications must reauthenticate and obtain new leases from the newly-promoted primary. |
| Allows the secondary cluster to handle client requests | No | Yes |
Describe the Vault agent
The purpose of the Vault agent is to simplify the integration between your applications and Vault. The Vault agent can handle the authentication to Vault, the administration of token renewals, and the retrieval of secrets. This allows you to use Vault with your application without necessarily making any changes to your application code. The agent could run as a sidecar to your application, or as a separate process on a virtual machine.
The details of how to configure the Vault agent is beyond the scope of this post, and it will depend a lot on how you deploy and run your application. To get familiar with the Vault agent I recommend doing one of the ten available official tutorials on the subject. For the full list see the official page.
Describe secrets caching
This sub-objective discuss one important feature of the Vault agent: secrets caching.
If your application sends a large volume of requests to Vault to retrieve secrets and renew tokens, you might experience performance issues with Vault. This could show up as latency in your requests or the need to constantly scale up your Vault cluster to keep up with the demand.
To alleviate part of this problem the Vault agent can cache tokens and leased secrets. This minimizes the amount of traffic that goes directly to Vault, and instead keeps most of the traffic between your application and the Vault agent.
There is a specific official tutorial on how to configure secrets caching in Vault, I recommend you take a look at it here.
Be aware of identities and groups
I have mentioned the identity secrets engine in previous posts. In this sub-section I will repeat some of what I have said and we will see how to use the concept of entities in our policies.
The identity secrets engine is Vault's internal identity management solution. Our Vault server might have multiple auth methods enabled, and for a given user there might be more than one way to sign-in. Let's say we have a user named Bob who has a GitHub account bob-github and an account in an unspecified external OIDC system named bob-oidc. Our Vault server has both the GitHub and OIDC auth methods enabled. Bob could sign in using any of the two available auth methods.
We can assign Bob an entity in Vault, and we can create aliases for each of Bob's external accounts. So we can have one entity that represents Bob, and one alias connected to this entity for Bob's GitHub account bob-github, and another alias connected to this entity for Bob's OIDC account bob-oidc.
We could assign policies to Bob's entity. This means that no matter what auth method Bob uses to sign in, he would get a token with those policies attached. We could also assign different policies to each of Bob's aliases. This means when Bob signs in using GitHub, he would get some additional policies. When Bob signs in using OIDC he would get a different set of additional policies.
This is one of the strengths of the identity secrets engine, but there is more.
Imagine we would like to assign entities the permissions to administrate secrets under their own name. For instance, when Bob signs in we would like to provide him a policy that gives him full access to secrets under secrets/bob/*. Similarly when Alice signs in she should get a policy that gives her full access to secrets under secrets/alice/*. Do we need to create a policy for each entity in our system, and make sure to assign the correct policy to the correct entity? We could use the concept of identities to do this in a better way.
Take a look at the following policy:
// policy.hcl
path "secrets/data/{{identity.entity.name}}/*" {
capabilities = ["read", "create", "update", "delete", "patch"]
}
path "secrets/metadata/{{identity.entity.name}}/*" {
capabilities = ["read", "create", "update", "delete", "patch"]
}
Here we have used a special template syntax to make dynamic policies. When this policy is applied, the entity associated with the token is made available to the policy, and the corresponding values are replaced in the policy document. In this case, when Bob signs in {{identity.entity.name}} is replaced with bob. Similarly when Alice signs in {{identity.entity.name}} is replaced with alice.
The identity object contains a lot of useful information, see the documentation for a list of what is available.
Explain response wrapping
Let's say you want to share a secret from Vault with someone. You could retrieve the secret value and send it in plaintext to your recipient. This is usually a bad idea because most likely the secret is logged somewhere, at least in your chat or email history.
Vault has the concept of response wrapping, which allows you to wrap the response to a request. This could be a GET request to retrieve a secret value. The response wrapping hides the actual response to this request, and instead provides you with a single-use token that your recipient can use to retrieve the response. Why is the token single-use? This is a safety mechanism to allow only a single recipient to unwrap the response. If your intended recipient can't unwrap the response because the token has already been used, then you know some man-in-the-middle attack has taken place. You should also make the time-to-live (TTL) of the wrapped response short, preferably seconds or minutes at most.
To see this in action, let's start a Vault development server:
$ vault server -dev
Let's use the default key/value secrets engine mounted at secret/ and add a new secret:
$ vault kv put -mount=secret database/password password=s3cr3t
======== Secret Path ========
secret/data/database/password
======= Metadata =======
Key Value
--- -----
created_time 2023-09-15T12:55:24.243192Z
custom_metadata <nil>
deletion_time n/a
destroyed false
version 1
To read this secret back I would run the following command:
$ vault kv get -mount=secret database/password
======== Secret Path ========
secret/data/database/password
======= Metadata =======
Key Value
--- -----
created_time 2023-09-15T12:55:24.243192Z
custom_metadata <nil>
deletion_time n/a
destroyed false
version 1
====== Data ======
Key Value
--- -----
password s3cr3t
Let's run that command again, but this time we add the -wrap-ttl flag:
$ vault kv get -mount=secret -wrap-ttl=5m database/password
Key Value
--- -----
wrapping_token: hvs.CAESIMuy<truncated>c3JWRml3TW1SOWdzMTk
wrapping_accessor: Zr7aVEftkByAKPTl3KeZJR2P
wrapping_token_ttl: 5m
wrapping_token_creation_time: 2023-09-15 14:56:59.423872 +0200 CEST
wrapping_token_creation_path: secret/data/database/password
We received a wrapping_token that is valid for a duration of wrapping_token_ttl (in this case 5m). How do we use this token? First of all we would probably send the wrapping token to the intended receiver, then that person/system would issue the following command:
$ vault unwrap hvs.CAESIMuy<truncated>c3JWRml3TW1SOWdzMTk
Key Value
--- -----
data map[password:s3cr3t]
metadata map[created_time:2023-09-15T12:55:24.243192Z custom_metadata:<nil> deletion_time: destroyed:false version:1]
The values are shown as Go maps, but we can identify that the response contains the password. What happens if I try to use the token again? The following:
$ vault unwrap hvs.CAESIMuy<truncated>c3JWRml3TW1SOWdzMTk
Error unwrapping: Error making API request.
URL: PUT http://127.0.0.1:8200/v1/sys/wrapping/unwrap
Code: 400. Errors:
* wrapping token is not valid or does not exist
The token has expired, because it was only possible to use it once! This is how response wrapping works, and although I showed it with the key/value secrets engine you can use it at a lot of places apart from this one.
Explain the value of short-lived, dynamically generated secrets
This sub-objective was covered in part five of this series. To summarize that discussion briefly:
Dynamically generated secrets are created when requested, which means they don't exist all the time and get lost and spread around like long-lived static secrets. Dynamic secrets together with a short time-to-live means the secret only exists for a brief period of time when it is needed, and no longer. If the dynamic secret value gets highjacked there is only a small window of time when the attacker could cause harm using the secret.
-
It seems like the blocks are called stanzas in Vault. Not sure why this is! It would be better to use the same nomenclature in all HCL, but that is just my opinion. I will stick to using blocks in this course, because I am not sure it matters all that much what you call it. ↩
-
But I will probably write a blog series about the Consul certification in the future! ↩
-
In Azure you actually don't place a subnet in a given zone like you do in AWS, you would rather have to make sure the resources (e.g. virtual machines) that you place in your subnets are in a given zone. For simplicity I drew it as if it works similar to AWS. ↩

Top comments (0)